2. 관련 연구
장치장과 관련하여 수행되는 작업으로 수출컨테이너의 경 우 크게 장치장 내부로의 반입작업, 이적작업 그리고 적하작 업으로 이루어져 있으며 이런 작업들을 효율적으로 수행하기 위한 연구가 진행되어 왔다. 먼저 장치장에 컨테이너를 반입 하는 과정에서 재취급을 줄이는 방안에 관한 연구로
Kang(2004b)은 반입 컨테이너의 무게에 대한 정보를 활용하 여 재취급을 줄이기 위한 장치 위치를 결정하는 방안을 제안 하였다. 이 방안으로 장치할 경우, 무게에 대하여 감안하지 않 고 무작위로 장치할 때 보다 효과적인 것으로 나타났다.
Park(2011)은 장치장에 컨테이너를 반입하는 과정에서 선처리 를 수행함으로써 장치장에서 반출하는 시점에 재취급이 발생 할 가능성을 낮추는 두 가지 방안을 제안하였으며 시뮬레이션 을 통하여 그 효과를 증명하였다. 컨테이너들의 장치장 반입 이 완료된 후부터 선박에 선적하기 전까지의 시간을 활용하여 재취급을 방지하는 방안에 대한 연구들도 많았는데 먼저 한 베이 내의 컨테이너들에 대하여 실시하는 재정돈에 대한 연구 로
Kang(2004a)은 분지한계법을 이용하여 컨테이너 이동 계 획을 수립하는 방안을 제시하였다. 이 논문에서 최소 컨테이 너의 이동횟수인 하한 값을 효과적으로 계산하는 방안도 함께 소개하였다.
Ha(2012)는 최소 크기의 재정돈 계획인 최단 길 이를 가지는 이적 순서를 도출하는 방안을 제안하였다. 이 연 구에서는 A
*알고리즘을 사용하여 상대적으로 짧은 시간에 베 이 내의 이동으로 최적해를 도출하는 방법과 최소이적횟수의 하한을 구하는 방법도 함께 제안하였다. 본 논문에서 제안하 는 방안도 A
*알고리즘을 바탕으로 재정돈 계획을 수립하지만
Ha(2012)와 다른 점은 다음과 같다. 첫째 베이 내의 이동만이 아닌 이웃한 베이로의 이동을 포함한다는 것이고, 둘째는 베 이 내의 이동으로 구하지 못한 해를 구한다는 점이다. 그 외 차이점은 해당하는 곳에서 언급한다. 그리고 선박에 선적하기 전의 시간에 블록내 이적을 통하여 재취급을 방지하는 방안에 대한 연구로
Kang(2005)는 하나의 크레인으로 블록내에 흩어 져 있는 컨테이너들을 재취급이 발생하지 않게 한 곳에 모으 는 방안을 제안하였으며
Oh(2005)은 복수 크레인으로 블록 내 에서 컨테이너들을 이적할 때 효율적으로 수행할 수 있는 휴 리스틱을 제안하였다. 서로 교차가 불가능한 복수 크레인을 이용하여 블록내의 컨테이너들을 이적할 때 크레인들 간의 간 섭에 의해 발생할 수 있는 지연을 최소화하는 이적 계획을 수 립하는 방안이었다. 크레인의 유휴시간을 이용하는 제약 없이 재정돈을 실시하는 방안에 대한 연구도 있었다.
Kim(2014)은 효율적인 장치장 운영을 위하여, 본 작업 중이라도 기회가 있 을 때마다 재정돈을 수행하도록 크레인 작업을 할당하는 방안 을 제안하였다. 시뮬레이션을 통하여 제안하는 방안이 터미널 생산성에 효과가 있음을 보였다. 그 외에도
Bae(2006)는 수직 형 블록을 대상으로 이적작업을 계획하는 방안을 장치위치 할 당문제와 장비 작업순서 문제로 분할하여 모형화하였으며 이 를 위하여 혼합정수계획법과 동적계획법을 사용하였다.
재정돈에 대한 기존의 연구에서 제안하는 방법들은 컨테이 너 이동 범위를 해당 베이 내로 제한하는 방안들이며 이 방안 들은 단순한 베이에 대하여 이동시간과 이동비용이 적게 드는 장점은 있으나, 복잡한 문제에 대해서는 해를 찾기 위하여 너 무 많은 시간을 소요한 후 해결하지 못하는 경우가 많았다. 그 래서 본 연구에서는 이웃한 베이를 이용함으로써 복잡한 문제 에 대한 해를 찾는 알고리즘을 제안한다.
3. 제안 알고리즘
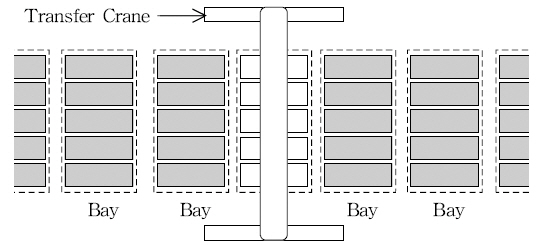
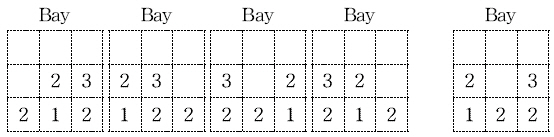
본 장에서는 먼저 재정돈 문제와 관련된 용어를 먼저 소개 한 후 제안하는 재정돈 방안에 대하여 설명한다. 장치장은 앞 의 설명처럼 블록이 여럿 모인 구조로 되어 있으며 각 블록은 다시 여러 베이들로 이루어져 있다. 베이란 Transfer Crane이 움직이지 않고 작업할 수 있는 컨테이너들의 묶음으로 아래 Fig.
1에 나타내었다. Fig.
1에는 4단 5열의 구조를 가진 베이 를 표현하였는데 흰색 베이 1개와 회색 베이 2개를 나타내었 다. 흰색 베이에서 재정돈 작업을 수행할 경우, 흰색 베이 주 위의 베이들 (Fig.
2의 회색 베이들)이 이웃한 베이들이 된다. 이웃한 베이들이 같은 규격의 컨테이너들을 적재하고 있다면 재정돈 작업을 할 때, 이웃한 베이들 상단의 빈 슬롯에 컨테이 너를 임시로 이동할 수 있다.
Fig. 1
Example of bay, stack and outer slot

Fig. 2
베이 내부의 빈 슬롯으로 이동하는 것 보다 베이 외부의 빈 슬롯(이하 외부 슬롯으로 기술함)으로 이동할 경우, (Transfer Crane의 베이간 이동이 발생하므로) 이동 시간과 비용이 더 소요되나, 외부 슬롯을 이용함으로써 베이 내부의 빈 슬롯만 이용하여 해결할 수 없는 재정돈 문제들을 해결할 수 있게 된 다. 외부 슬롯은 같은 사양의 컨테이너가 적재된 이웃 베이 상 단의 빈 슬롯 중 임시 저장을 위하여 선택한 것이기 때문에, 여러 개의 외부 슬롯이 있을 수 있다. 예를 들면 Fig.
1에서 이웃한 베이들이 같은 사양의 컨테이너를 적재한 베이들이라 면, 3개의 외부슬롯을 선택해야 할 경우, 앞쪽 회색 베이의 빈 슬롯 7개 중 2개, 뒤쪽 회색 베이의 빈 슬롯 6개 중 1개를 외 부 슬롯(점선상자로 표현)으로 사용할 수 있을 것이다. Fig.
2 에는 Fig.
1을 위에서 본 모습을 나타내었다. Fig.
1의 흰색 베 이에 Transfer Crane이 위치하고 있다고 가정한 그림이다. 회 색 베이들이 앞에서 말한 것처럼 이웃한 베이들을 나타낸다.
베이에 장치된 컨테이너들이 장지장에서 반출되는 순서는 우선순위를 사용하여 나타낸다. 높은 우선순위의 컨테이너가 낮은 우선순위보다 먼저 반출되며, 높은 우선순위에 작은 값 의 인덱스를 부여하는 방식으로 표현한다. 여러 개의 컨테이 너를 한 스택 위에 있는 여러 외부 슬롯들에게 적재할 경우, 아래쪽 인덱스가 위쪽보다 같거나 작은 순서로 적재해야 한 다. 이는 다음에 설명하는 알고리즘의 세 번째 파트에서 인덱 스를 기준으로 외부슬롯에 있는 컨테이너를 내부로 이동하기 때문이다. 내부 부적합 컨테이너는 베이 내의 각 스택에서 자 신의 아래에 자신보다 높은 우선순위(작은 값의 인덱스)의 컨 테이너가 하나라도 있는 컨테이너들로 재정돈을 위해서 반드 시 재배치되어야 하는 컨테이너들이다. 외부 부적합컨테이너 는 외부 슬롯으로 이동한 컨테이너들 중 베이 내로 이동할 때 어떤 스택으로 이동하여도 내부 부적합 컨테이너가 되는 컨테 이너를 말한다. 선택 재배치 컨테이너는 베이 내의 컨테이너 들 중 내부 부적합 컨테이너는 아니지만 재정돈을 위하여 필 요에 의해 재배치되는 컨테이너를 의미한다. 아래 Fig.
3에서 와 같이 베이 내에 7개의 컨테이너가 외부에 2개의 컨테이너 가 놓여 있을 경우, 베이 내부에 빗금 친 컨테이너가 내부 부 적합 컨테이너를 외부슬롯에 빗금 친 컨테이너가 외부 부적합 컨테이너를 나타낸다. 그림에서 작은 사각형은 컨테이너를, 내 부 숫자는 인덱스를 나타내는데 외부슬롯의 3을 베이내로 이 동을 한다면, 어떤 스택으로 이동을 하더라도 부적합 컨테이 너가 된다. 반면에 외부슬롯의 1은 내부의 2번째나 4번째 스 택에 적재할 경우 부적합 컨테이너가 되지 않는다. 내부 부적 합컨테이너를 모두 들어내더라도 재정돈을 위해서는 추가로 컨테이너를 (스택4의 1이나 스택 2의 2 컨테이너들 중 선택하 여) 더 들어내어야 하는데 이런 컨테이너를 선택 재배치 컨테 이너라고 한다.
Fig. 3

본 논문에서 제안하는 방법은 A
*알고리즘(
Nilsson, 1998)을 바탕으로 재정돈 계획을 수립하는(해를 찾는) 방안으로, 너비 우선탐색과 비슷하지만 문제의 특성에 대한 정보를 바탕으로 가장 좋은 경로 상에 있다고 판단되는 노드를 우선 방문하는 탐색방법이다. 여기서 노드는 베이를 나타낸다. A
*알고리즘에 서는 평가값을 사용하여 노드들을 평가하는데 평가값은 평가 함수 f(n) = g(n) + h(n)로 구한다. g(n)는 깊이 추정값, 즉 시 작 노드에서 노드 n까지의 최단 거리에 대한 추정값이고, h(n) 은 노드 n에 대한 휴리스틱 추정값으로 노드 n에서부터 목표 노드까지의 최단 거리에 대한 추정값을 나타낸다. f(n)은 베이 의 초기상태인 시작노드에서 재정돈을 완성하는 상태 즉 목표 노드까지 탐색하기 위해 이동하는 컨테이너의 개수를 의미하 며, g(n)은 시작 노드에서 노드 n까지 이동한 컨테이너의 개 수를 의미한다. h(n)은 노드 n에서 목표노드까지 앞으로 이동 해야할 컨테이너의 개수를 의미한다. 본 논문에서 h(n)은 내 부 부적합 컨테이너의 수, 외부 부적합 컨테이너 수 그리고 최 소 선택 재배치 컨테이너의 수의 합으로 구한다.
알고리즘의 각 파트에 대한 구체적인 절차는 다음과 같다. 이 절차들은
Nilsson(1998)과
Ha(2012)에 기술된 알고리즘을 참조하여 기술한다. 본 제안알고리즘과
Ha(2012)의 알고리즘 의 차이는 첫째, 아래 첫 번째 파트와 세 번째 파트가
Ha(2012)에는 없으며, 둘째 OPEN 리스트들을 정렬하는 방식 이 다르다는 점이다.
Ha(2012)의 알고리즘에서의 정렬기준은 평가함수 f(n)의 값이지만 제안 알고리즘은 h(n)이다. 외부슬 롯과 관련되는 부분들도
Ha(2012)의 알고리즘과 다른 부분들 이다.
[ 첫 번째 파트 ]
1. 시작노드만 들어 있는 OPEN1 리스트와 비어있는 OPEN2 리스트(OPEN2 리스트는 두 번째 파트에서 사용된다.)와 CLOSED 리스트를 준비한다.
2. OPEN1이 비게 되면 두 번째 파트로 간다.
3. OPEN1의 제일 앞에 있는 노드 n을 꺼낸 후 다음을 수행한다. 노드 n에 빈 외부슬롯이 없으면 그 노드 를 정렬기준에 따라 OPEN2에 삽입하고 단계2를 다 시 한다. 빈 외부 슬롯이 있으면 CLOSED에 삽입한 다.
4. 노드 n에서 ‘자식노드 생성방법(아래 설명)’으로 자 식노드의 집합 M을 만든다.
5. M에 포함된 각각의 노드 m에 대하여 다음을 수행 한다. m과 동일한 노드가 OPEN1과 CLOSED에 없 으면 m을 OPEN1에 삽입한다. m과 동일한 노드m’ 가 OPEN1에 있고 m의 평가값이 m’의 평가값보다 작으면, m’를 m으로 대체한다.
6. OPEN1와 OPEN2에 노드들은 휴리스틱 추정값 (h(n))에 따라 오름차순으로 정렬한다. 이때 동일한 휴리스틱 추정값을 가지는 노드들은 깊이 추정값에 따라 내림차순으로, 동일한 깊이 추정값을 가질 때 는 부적합컨테이너의 인덱스 합에 따라 오름차순으 로 정렬한다.
7. 단계2로 간다.
[ 두 번째 파트 ]
1. OPEN2에서 제일 앞에 있는 노드n을 꺼낸 후 CLOSED에 삽입한다.
2. 노드n이 내부 부적합 컨테이너와 외부 부적합 컨테 이너가 없는 노드이면 해를 발견한 것이며 세 번째 파트로 넘어간다.
3. 노드 n에서 가능한 이적을 적용하여 자식노드의 집 합 M을 만든다.
4. M에 포함된 각각의 노드 m에 대하여 다음을 수행 한다. m과 동일한 노드가 OPEN2와 CLOSED에 없 으면, m을 OPEN2에 삽입한다. m과 동일한 노드 m’ 가 OPEN2에 있고 m에서의 평가값이 m’의 평가값 보다 작으면, m’를 m으로 대체한다.
5. OPEN2가 비게 되면 세 번째 파트를 실행할 필요 없 이 실패로 끝난다.
6. OPEN2에 노드들은 휴리스틱 추정값에 따라 오름차 순으로 정렬한다. 동일한 휴리스틱 추정값을 가질 때는 깊이 추정값에 따라 오름차순으로 정렬한다.
7. 단계2로 간다.
[ 세 번째 파트 ]
두 번째 파트가 정상종료가 되었을 경우 실질적인 해를 찾 은 것이 되며, 세 번째 파트에서는 마지막 정리 작업만 수행한 다.
1. 노드n에서 외부슬롯에 있는 컨테이너들 중 우선순위 가 가장 낮은 컨테이너를 찾는다.
2. 그 컨테이너를 적재할 수 있는 스택을 찾아 그 스택 으로 이동한다.
3. 외부슬롯의 노드가 모두 이동이 되면 알고리즘은 정 상 종료한다.
4. 단계1로 간다.
첫 번째 파트 4단계에 명시한 ‘자식노드 생성방법’에 대하 여 설명한다. 여기서는 외부슬롯으로 컨테이너를 이동시켜서 자식노드를 생성하는데 이때 옮길 컨테이너를 선택하는 기준 은 다음과 같다.
1번 기준으로 내부 부적합 컨테이너를 외부로 옮기면 Fig.
6의 4)에서처럼 적합 컨테이너로 바뀔 가능성이 있다. 2번 기 준은 Fig.
6의 3)의 예처럼 외부 슬롯에 있는 부적합 컨테이너 의 수를 줄일 수 있으며, 외부로 이동하는 적합 컨테이너의 우 선순위가 낮을수록 효과가 크다.
ne을 비어있는 외부 슬롯의 개수,
mj을 스택
j에 적재된 부적합 컨테이너 수 그리고
wji 을 스택
j에 적재된 적합 컨테이너들 중 인덱스
i보다 낮은 값 의 인덱스(높은 우선순위)의 컨테이너 수라고 하면
i값을 최댓 값의 인덱스(가장 낮은 우선순위)로 설정한 후
mj +
wji와
ne 중 낮은 수만큼 외부슬롯으로 옮겨서 자식노드를 생성한다. 이것이 첫 번째 파트에서 자식노드 생성하는 방법이다. 두 번 째 파트에서는 단순히 하나의 노드에서 하나의 컨테이너 이적 으로 가능한 모든 자식노드를 생성한다. 세 번째 파트에서는 자식 노드를 생성하는 과정이 없이, 두 번째 파트에서 찾은 해 에 해당하는 노드에서 외부 슬롯에 있는 컨테이너를 내부로 옮기는 마지막 정리 작업만 수행하게 된다. 첫 번째 파트에서 한꺼번에 여러 컨테이너를 한꺼번에 이적하여 자식노드를 생 성하는 방법과 두 번째 파트의 정렬기준을 첫 번째 파트의 정 렬기준과 다르게 적용하는 것 모두 해를 구하기 위해 너무 많 은 시간을 소비하는 것을 피하기 위함이다.
알고리즘을 실행할 때 하나의 노드로 자식노드를 많이 생 성하게 되므로 기존의 노드와 동일한 노드 생성을 막는 것이 중요하다. 장치형태가 달라도 동일한 노드인지 판단하기 위하 여 노드를 인덱스에 따라 사전순으로 정렬한 형태로 만드는 것을 정규화라하는데 이 방법은
Ha(2012)에서 사용되었다. 예 를 들면 아래의 첫 베이를 2-0-0, 1-2-0, 2-3-0로 표현하고 사전순으로 정렬하여 1-2-0, 2-0-0, 2-3-0으로 바꾸어 마지막 노드처럼 표현하는 것을 정규화라한다. (빈슬롯은 0), 정규화 로 표현하면 좌측 4개의 노드는 모두 오른쪽 노드가 된다.
Fig. 4
Example of layout normalization
다음은 3단 4열의 베이를 대상으로 알고리즘을 수행하는 과정을 나타내었다. 각각의 표는 베이를 나타내며, 표안의 숫 자는 컨테이너의 인덱스를 나타내고, 표 위에 숫자는 노드 번 호, g=깊이추정값, h=휴리스틱추정값을 나타내는데 노드번호 는 노드가 생성되는 순서를 의미한다. g값은 시작노드에서 그 노드가 될 때까지 이동한 컨테이너 수가 되고, h값은 앞으로 이동할 컨테이너 수로, 부적합 컨테이너수라고 보면 되는데 빗금친 칸으로 부적합 컨테이너를 나타내었다. 각각의 표아래 의 상자 두개는 외부슬롯을 나타내며 노드간의 화살표는 자식 노드 생성을 의미한다. 자식노드 생성은 컨테이너이동으로 생 성하게 되는데 화살표 중 굵은 선은 해를 구하는 과정을 의미 한다. 가로선(파선)들은 첫 번째 파트외 두 번째 파트의 경계 선과 두 번째 파트와 세 번째 파트의 경계선을 나타낸다.
Fig. 5
Example of algorithm execution
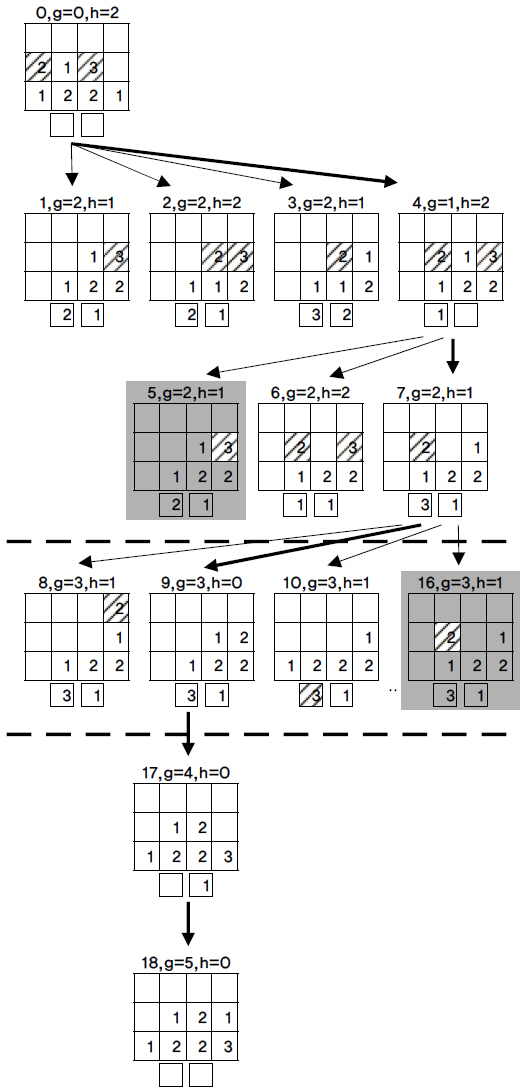
OPEN2 리스트와 CLOSED 리스트는 비어있고, 노드0만 OPEN1 리스트에 있는 상태로 알고리즘을 시작한다. 먼저 노 드0를 꺼내서 CLOSED 리스트에 삽입한다. 노드 0는 컨테이 너 이동이 없었으므로 g=0이고 부적합컨테이너가 2개이므로 h=2가 된다. 노드0를 가지고 첫 번째 파트에서 언급한 ‘자식노 드 생성방법’을 따라 자식노드를 만들게 되는데, 노드1은 노드 0의 스택1에서 컨테이너2개를 외부슬롯으로 이동시켜서 만든 후 정규화한 자식노드이다. 빈 외부슬롯이 없으므로 노드1을 OPEN2에 삽입한다.(위의 첫번 째, 파트 단계3참조)
노드를 삽입할 때 CLOSED와 OPEN1에 동일한 노드가 있 는지 확인하고, CLOSED에 동일한 노드가 있으면 이미 자식 노드를 생성한 적이 있는 노드와 동일한 노드이므로 삽입을 하지 않고 생성된 자식노드를 삭제를 한다. OPEN1에 동일한 노드가 있으면 두 노드의 평가값(g값과 h값의 합)을 비교하여 낮은 값을 가지는 노드를 리스트에 남겨둔다. 노드2는 노드0 의 스택2에서 컨테이너2개를 외부슬롯으로 이동시켜서 만든 후 정규화한 자식노드이다. 노드3도 같은 과정을 거친다. 노드 4는 노드0의 스택4의 컨테이너가 1개 뿐이므로 컨테이너 1개 를 외부슬롯으로 이동시킨 후 정규화한 노드이다. 빈 외부슬 롯이 있으므로 노드4는 OPEN1에 삽입된다.
노드0를 가지고 자식노드를 생성하는 과정을 마쳤으므로 다시 OPEN1에서 다음 노드인 노드4를 꺼내서 CLOSED에 삽 입한 후 외부슬롯을 하나 더 채우면서 자식노드들 5,6,7을 생 성하게 된다. 노드 5,6,7도 외부슬롯이 채워졌으므로 모두 OPEN2에 삽입된다. 노드 5를 삽입할 때 동일한 노드1이 이미 OPEN2에 있고 두 노드의 평가값(g=2, h=1)이 같으므로 노드 5는 삭제된다. OPEN1이 비었으므로 첫 번째 파트는 종료된 다. 이 시점에 OPEN2에는 노드 1,2,3,6,7이, CLOSED에는 노 드0,4가 있게 된다. OPEN2에서는 h값을 기준으로 오름차순으 로 정렬되어 있는데, 노드1,3,7의 h=1이므로 처음에, 노드2,6의 h=2이므로 그 다음에 정렬되어 있다. 모든 노드들이 2개의 컨 테이너를 옮겼으므로 g=2로 같다. 두 번째 파트에서는 OPEN2에서 노드를 선택한 후 컨테이너 하나를 옮기면서 만 들 수 있는 자식노드를 모두 생성하는 과정을 거치게 된다. 노 드 1,3,7중 하나가 임의로 선택되는데 여기서는 노드7을 가지 고 자식노드를 생성하는 과정을 그림에 나타내었다. 컨테이너 하나를 이동시켜 만들 수 있는 자식노드를 모두 만든 후 h값 을 기준으로 OPEN2에 정렬하면서 삽입하게 된다. 노드11에 서 노드15의 자식노드 생성은 생략하였는데, 자식16의 노드가 노드 7과 같고 평가값이 크므로 OPEN2 에 삽입하지 않고 삭 제한다. 노드7의 자식노드생성이 끝난 후 OPEN2에서 다음 노 드를 선택하면 (9의 h값이 0이므로 OPEN2의 가장 앞에 정렬 되어 있다) 노드 9가 선택된다. 앞으로 이동해야할 컨테이너 개수인 h값이 0이므로 노드9가 찾는 해가 되고 두 번째 파트 가 종료된다. 마무리 작업을 수행하는 세 번째 파트를 시작하 여 외부슬롯에 있는 컨테이너들을 높은 값의 인덱스 3부터 베 이 내부로 옮기게 되는데 옮길 수 있는 스택을 찾아서 모두 이동을 하면 세 번째 파트도 종료하게 된다.
다음은 3단 4열의 베이를 대상으로 제안 알고리즘을 수행 하여 해를 찾은 후, 해와 관련된 노드만 정규화를 하지 않은 형태로 나타내었다. 부적합 컨테이너들은 사선으로 표시하였 으며, 각각의 스텝에서 변하는 내부 부적합 컨테이너 수와 외 부부적합 컨테이너 수를 기록하였다.
Fig. 6
Example of finding solution
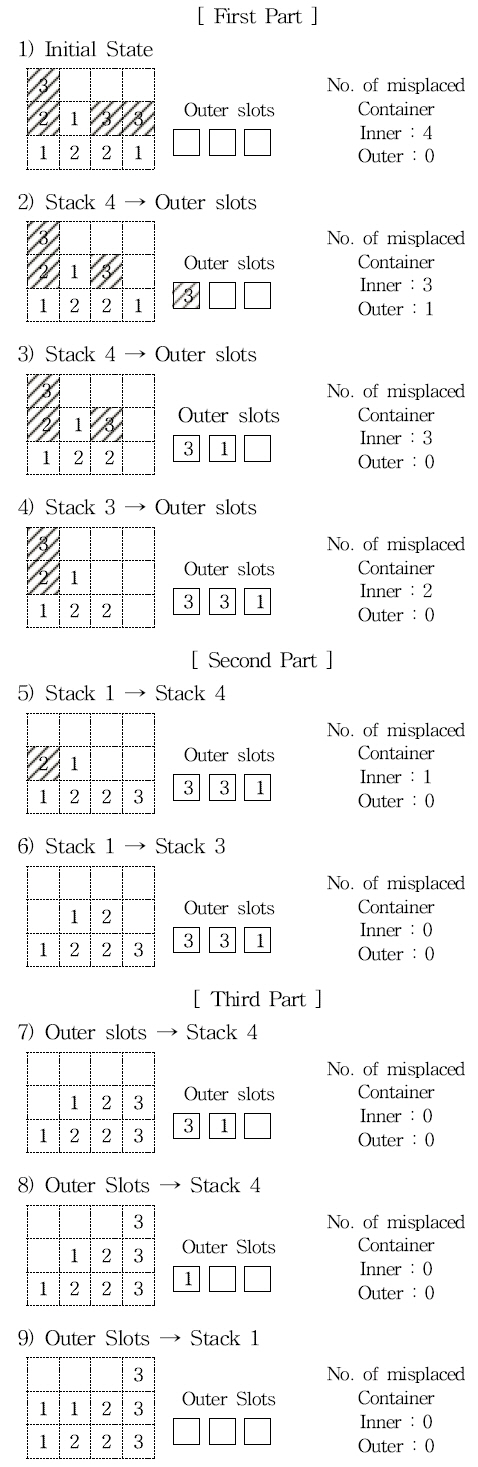
위의 예의 3)에서 외부 부적합 컨테이너 3이 적합 컨테이너 로 변한 이유는 컨테이너1을 외부로 옮긴 결과, 외부 컨테이 너3을 스택4에 옮긴다면 부적합 컨테이너가 되지 않기 때문이 다. 4)에서는 컨테이너 3이 베이 내부에서는 부적합 컨테이너 였으나 외부로 옮김으로 해서 적합 컨테이너가 되는 것을 알 수 있다. 3)이 수행되고 난 후 외부 부적합 컨테이너 수가 0이 되었으므로 외부 슬롯에 있는 컨테이너를 내부로 옮겨도 문제 가 없는 상태가 되었으며 6)에서 내부 부적합 컨테이너의 수 도 0개가 되었기 때문에 두 번째 파트가 종료될 수 있었다.


 PDF Links
PDF Links PubReader
PubReader Full text via DOI
Full text via DOI Download Citation
Download Citation Print
Print