서 론
해양안전심판원(이하, 해심)에서는 IMO Res. MSC.255(84) (IMO, 1997)에 근거한 「해양사고의 조사 및 심판에 관한 법 률 제11690호)」(MOF, 2013)에 의거하여 해양사고를 조사 및 분석하고 있다. 조사 및 분석 결과는 다양한 해양사고 통계 자 료(KMST, 2014)와 재결서 및 재결요약서 그리고 해양사고 종류별 주제어 등의 형태로 해양사고조사심판정보포털(이하, 정보포털)(KMST, 2015)에 제공하고 있다.
한편, 해심에서는 해양사고를 상세하게 분석하여 재결서를 작성하고, 재결서를 3쪽 이내로 요약하여 재결요약서를 작성 하고 있다. 재결요약서를 작성할 때 심판관들은 해양사고의 주요한 원인을 3∼4개의 대표적인 문장으로 기록하고 있는데, 이를 주제어(key word)로 칭하고 있다. 이러한 주제어 작성목 적은 해양사고의 주요한 원인을 판단하는 기준으로 활용하고, 용이하게 판례를 검색하기 위한 것이다(KMST, 2007). 따라서 주제어는 해양사고 원인분석과 심판관들의 효율적인 판례 검 색에 중요한 데이터이다.
한편, 해심에서는 주제어 작성의 통일성을 기하기 위하여 두 차례에 걸쳐서 주제어를 정비한 바 있다. 1차는 2007년에 실시하였는데, 1963년부터 2007년까지의 재결서 분석을 통하 여 해양사고별 대표적인 주제어 2,182개를 결정한 바 있다 (KMST, 2007). 그리고 본 논문 저자 등에 의해서 2008년부터 2016년까지 10년간의 재결요약서를 통하여 총 1,311개의 주제 어를 2차로 정비한 바 있다(KMST, 2016). 한편, 이러한 2차 정비를 통해서, 선정한 주제어 수가 너무 많고, 시간경과에 따 른 주제어 갱신 등이 필요하기 때문에 향후 주제어 축소를 위 한 프레임(frame) 개발이 필요한 것으로 나타났다.
이러한 주제어 축소 또는 주제어 구축 프레임에 관한 연구 의 필요성은 오래전부터 제기되어 왔는데, Yim(2009a)은 상선 운항사고 평가에 소수의 변수를 적용하기 위한 해양사고 데이 터 압축을 시도한 바 있다. 이어서 Yim(2009b)은 압축된 사고 원인에 대한 변수를 이용하여 선원의 인적과실을 평가한 바 있다. 그리고 Cho 등(2015)은 차원이 압축된 해심 데이터를 인적모델 개발에 적용하기 위한 연구를 시도한 바 있고, Jang 등(2016)은 현재 해심에서 분류한 주제어 수의 축소를 통한 인적오류 모델 개발에 관해서 보고한 바 있다.
이와 같이 주제어 수의 축소에 관한 연구의 필요성은 본 연 구 이전부터 제기되어 왔다. 주제어 수의 축소에 관한 연구의 핵심은 체계적인 주제어 구축 프레임의 개발인데, 이를 위해 서는 주제어 작성에 사용하는 단어를 통일시켜야 하고 최소한 의 단어를 사용해야 한다. 특히, 최소한의 단어는 단어의 수만 최소화시키는 것이 아니라 사고 내용을 충분하게 설명할 수 있어야 한다. 이러한 단어 중에 가장 중요한 것은 해양사고의 원인을 분류하기 위한 단어(이하, 원인분류단어)이다.
본 연구의 목적은 체계적인 주제어 구축 프레임에 가장 중 요한 원인분류단어를 최적의 최소 단어로 축소하기 위한 기법 을 개발하여 최소의 단어를 도출하기 위한 것이다.
연구 방법은 다음과 같다. 우선, 해양안전심판원의 정보포 털에서 아홉 가지 사고종류에 대한 2,642개의 주제어를 획득 한 후, 원인분류단어의 식별에 활용하기 위한 56개의 공통단 어를 도출하였다. 그리고 파레토(Pareto) 법칙(Atmour et al., 2014; Finkelstein et al., 2006)에 의거한 파레토 분포함수와 파레토 지수를 이용하여 사고종류별 최적의 최소 원인분류단 어를 추정하였다.
연구접근 방법
2.1. 연구 접근절차
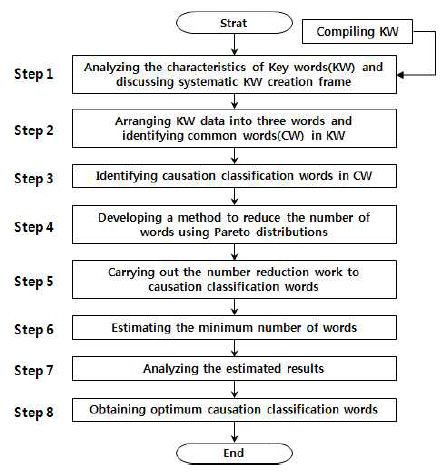
Fig. 1은 연구 접근절차를 나타낸다. Step 1에서는 주제어 (key word, KW)를 수집하여 KW의 특징을 분석하고 체계적 인 KW 작성을 위한 프레임(frame)을 검토한다. Step 2에서는 수집한 KW를 정리하여 단어 축소 연구에 적용할 통일된 공 통단어(common word, CW)를 식별한다. 그리고 Step 3에서 는 CW에서 해양사고 원인분류에 적용할 단어를 식별하고, Step 4에서 파레토(Pareto) 분포함수를 이용한 단어 축소 방 법을 개발한다. Step 5에서는 원인분류단어의 축소 작업을 실 시하고, Step 6에서 최소의 단어 수를 추정한 후, Step 7에서 추정한 최소 단어를 분석하여 최종적으로 Step 8에서 최적의 원인분류단어를 획득한다.
2.2. 해양사고의 원인분류단어 식별 방법
Fig. 2는 선행연구(KMST, 2016; Jang et al., 2016)에서 제 안한 체계적인 KW 구축 프레임을 하나의 예로 나타냈다. 이 프레임은 A부터 F까지의 6개의 변수로 구성되어 있는데, A는 상황을 나타내고, B는 환경, C는 대상, D는 임무, E는 원인, F 는 사고종류를 나타낸다. E의 원인은 E-1(인적 원인)과 E-2 (물리적 원인)로 세분되고, 변수는 다양한 종속변수를 갖는다.
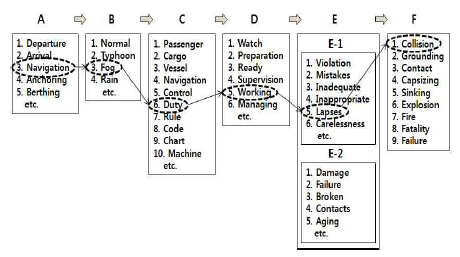
Fig. 2에 점선의 원과 선으로 표시한 예는, 「항해(A에서 3 번) 중, 안개(B에서 3번)가 발생하고 당직(C에서 6번) 근무(D 에서 5번) 소홀(E-1에서 5번)로 충돌(F에서 1번)이 발생한 사 고」의 경우를 나타낸 것으로, 그림과 같이 해당하는 단어를 선택하면 자동으로 KW가 당직근무소홀로 작성됨을 나타낸 다. 이와 같은 방법을 적용하면, 심판관 모두가 일관된 방법으 로 KW을 작성할 수 있을 뿐만 아니라 변수의 조합을 이용하 여 통계기반의 해양사고 원인도 분석할 수 있을 것으로 고려 된다.
여기서, 원인 변수에 해당하는 종속변수는 해양사고의 원인 을 파악하는데 가장 중요한데, 선행연구결과, 종속변수의 종류 가 대단히 다양하고 방대한 것으로 나타났다. 따라서 Fig. 2의 프레임을 구축하기 위해서는 원인에 해당하는 종속변수를 소 수의 종속변수로 축소하는 것이 우선 필요하다.
그래서 본 연구에서는 기존에 해심에서 사용하고 있는 방 대한 주제어 데이터를 이용하여 E의 원인에 해당하는 최적의 종속변수를 식별하였다.
2.3. 해양사고의 원인분류 단어 선정 방법
「해양안전심판원 재결판례분석 연구용역 최종보고서 (KMST, 2007)」에는 현재 해심에서 사용하고 있는 KW 작성 원칙과 주제어의 특징이 기술되어 있는데, 그 내용을 요약하 면 다음과 같다. (a) KW는 재결서 내용을 토대로 작성하고, (b) 한 건의 해양사고에 대해서 3∼4개의 KW를 도출한다. (c) 원인판단의 비중이 높은 것을 제1 KW로 선정하고, 그 다음으 로 비중이 높은 것을 제2, 제3 등의 KW로 정한다.
이러한 원칙에 의거하여 작성된 KW의 한 가지 예를 들면 다음과 같다. 2003년에 발생한 「어선 제OOO호 기관손상사 건」의 경우, 주기관 정비점검소홀, 클러치 손상, 윤활유 공급 차단, 기관손상 등 네 가지 KW로 작성되어 있다(KMST, 2003). 이러한 KW는 명사 또는 명사와 형용사의 조합으로 구 분할 수 있는 것이 특징인데, 예를 들면 다음과 같다. 주기관 정비점검소홀의 경우는 주기관과 정비점검 그리고 소홀로 구 분할 수 있고, 클러치 손상의 경우는 클러치와 손상으로 구분 할 수 있다. 이러한 예는 기관손상사건에 관한 것인데, 항해와 관련된 KW의 예를 들면 다음과 같다. 제한시계 경계소홀의 경우는 제한시계와 경계 그리고 소홀로 구분할 수 있고, 협수 로 무중항법위반의 경우는 협수로와 무중항법 그리고 위반으 로 구분할 수 있다.
위의 예와 같이 구분한 단어 중에서, 첫 번째 단어는 주로 주어진 상황 또는 장비 명칭 등으로 구성되고, 두 번째 단어는 첫 번째 단어에 대한 행위 또는 상황의 적용 등으로 구성되며, 세 번째 단어는 사고의 원인을 나타낸 것으로, 주로 해기사의 인적원인 또는 장비와 기기의 물리적인 원인 등으로 구성되어 있다.
여기서, 첫 번째와 두 번째 단어는 선박에서 일반적으로 사 용하는 단어들이 나타나는데 반하여, 세 번째 단어는 심판관 들의 주관적인 견해가 반영된 방대한 종류의 단어가 등장한 다. 그래서 본 연구에서는 방대한 종류의 세 번째 단어를 원인 분류 단어로 선정하였다.
실험 데이터 구축
3.1. 주제어 데이터 수집과 분류
해심의 정보포털(KMST, 2015)에서 아홉 가지 사고종류(충 돌, 좌초, 접촉, 전복, 화재/폭발, 침몰, 기관고장, 인명사상, 여객사상)에 대한 KW 총 2,982개를 수집한 후, 중복되거나 KW로 부적절한 것 등을 제외하고 총 2,642개의 KW을 선정 하였다. 선정한 KW는 액셀파일(Excel file)에 다음과 같은 형 태로 분류하였다(Yim et al., 2014).
여기서 〈〉는 데이터 세트(data sets)를 의미하고, Ak 는 사고종류의 단어를 나타낸다. K W k , j k
한편, K W k , j k ∈ { ω 1 k , j k , ω 2 k , j k , ω 3 k , j k } ω 1 k , j k , ω 2 k , j k , ω 3 k , j k ω 3 k , j k
Table 1
Compiled key words according to the type of
accidents Ak . NKW1k and NKW2k denotes the acquired number and the used number of key words in this work, respectively
여기서 N K W k , j k K W k , j k
Table 1에서, NKW1k 와 NKW2k 은 처음에 수집한 KW와 본 연구에 적용한 KW의 수를 나타낸다. 앞에서 설명한 바와 같이 k = 1부터 k = 9까지는 아홉 가지 사고종류를 나타내고, k = 10는 아홉 가지 사고종류 전체의 합을 나타낸다.
여기서, K W k , j k ∈ { ω 1 k , j k , ω 2 k , j k , ω 3 k , j k } ω 3 k , j k ω 3 k , j k ω 3 k , j k
3.2. 공통단어 식별
공통단어(CW)는 다음과 같이 식별하였다. 우선, K W k , j k ω 3 k , j k ( k = 10 ) W t ∪
Table 2
Identified common words CWm and their frequencies ℵm
여기서 ∩는 단어의 교집합을 의미한다.
그리고 식(3)의 W t ∩ ℵ t ∩ 〈 W t ∩ , ℵ t ∩ 〉 ℵ t ∩
위의 〈 W t ∩ , ℵ t ∩ 〉 〈 W ′ m , ℵ ′ m 〉
여기서 m = 1,2,3,⋯,M 이고, M = ∑ t = 1 T I W t
3.3. 사고종류별 공통단어 식별
Table 2의 CW를 이용하여 사고종류에 각각에 포함된 공통 단어를 식별하면 다음과 같다. 먼저, ω 3 k , j k
다음에는 ω 3 k , j k I C W k , n k
그리고 데이터 세트 〈 C ′ W k , n k , C ′ F k , n k 〉 C ′ F k , n k C W k , n k C F k , n k
단어 압축 방법
4.1. 파레토 분포함수와 지수
파레토(Pareto) 법칙은 「20%(q)의 인구가 80%(p)의 수입 을 갖고 있다」는 것으로, p + q = 1 규칙으로 불린다 (Wikipedia, 2016). 본 연구에서는 20%에 해당 단어가 전체단 어의 80%를 설명할 수 있는 최소의 단어 수를 구하기 위하여 파레토 함수를 적용하였다.
파레토 함수는 X 가 형식 1의 파레토 분포를 갖는 랜덤 (random) 변수인 경우 X 가 임의의 수 x 보다 클 때의 확률 Pr(X > x) 로 정의할 수 있고(Brynjolfsson et al., 2007; Fialova et al., 2004), Pr(X > x) 에 대한 누적분포함수는 F (x) = 1 - Pr(X > x)로 정의된다(Rytgaard, 1990; Sousa and Michailidis, 2004; Vilar-Zanon and Lozano-Colomer, 2007). 그리고 파레토 지수(index)는 α = log ( q ) / log ( q / p ) , ( p > q )
4.2. 단어 축소 절차
다음과 같은 4단계 절차를 적용하여 단어를 축소하였다.
여기서 F p k ( n k ) n k ( n k = 1 , 2 , 3 , ⋯ , N k ; N k = N C W k )
다음에는 공통단어의 수 NCWk 에서 축소하려는 단어의 수 Nqk 을 계산한다.
여기서 q 는 축소하려는 단어의 비율을 의미하는 것으로, 설계조건에서 q = 0.2이다.
여기서 N ^ q i
실험 및 결과
5.1. 파레토 분석 결과
Table 3에 단어 축소 과정에서의 계산결과들을 나타냈다. 설계조건(Design conditions)에서, α= 1.161는 설계조건으로 설정한 파레토 지수를 나타내고, NCWk 는 k 에 해당하는 CW의 수를 나타내고, Nqk 는 설계조건 q = 0.2에 대해서 결정 된 단어의 수를 나타낸다. 설계결과(Design results)에서, pk , qk , αk 등은 주어진 설계조건에 대해서 계산한 결과를 나타낸 다. 모든 k에 대해서 α k = α ¯ ( α ¯ = 1.161 ) N ^ q k p ^ k ≥ 0.8 q ^ k ≤ 0.2 α ^ k ≤ α ¯
Table 3
Calculation results to k
이상의 결과를 예로 설명하면, k = 1 (충돌사고)의 경우 해 당하는 단어의 수 NCWk = 34 이고, 설계조건을 만족하는 단 어의 수 Nqk = 6 인데, 평가결과 설계조건을 만족하지 못하였 다. 그래서 추정한 결과 N ^ q k = 12 α ^ k > α ¯ N ^ q k
5.2. 파레토 차트를 이용한 검증

5.3. 축소한 원인분류단어
Table 3의 N ^ q k C W k , n k ( n k = N q ^ k ) I C W k , n k ( n k = N q ^ k )
Table 4
Table 5에서 k = 1 이 γk = 64.7% 로 최댓값을 나타내고, k = 9에서 γk = 45.5% 로 최솟값을 나타냈다. 특히, 사고종류 전체에 대한 k = 10 의 경우 γk = 57.1% 로 나타났는데, 이 의 미는 56개의 공통단어 중에서 파레토 법칙에 의거하여 추정한 24개의 단어만을 이용하더라도 공통단어의 80%를 설명할 수 있음을 나타낸다. 그리고 평균 축소율은 58.5%로 나타났다.
Table 5
Calculation results for the reduction rates γk(%) , where NCWk and N ^ q k
| k | NCWk |
|
γk |
|---|---|---|---|
| 1 | 34 | 12 | 64.7 |
| 2 | 36 | 13 | 63.9 |
| 3 | 42 | 18 | 57.1 |
| 4 | 34 | 14 | 58.8 |
| 5 | 40 | 17 | 57.5 |
| 6 | 49 | 20 | 59.2 |
| 7 | 46 | 19 | 58.7 |
| 8 | 37 | 14 | 62.2 |
| 9 | 11 | 6 | 45.5 |
| 10 | 56 | 24 | 57.1 |
| Average | 58.5 | ||
결 론
본 연구에서는 주제어를 체계적으로 작성하는데 가장 중요 한 사고종류별 공통된 단어를 최적의 최소 단어로 축소하여 도출하였다. 해양안전심판원의 정보포털에서 아홉 가지 사고 종류에 대한 2,642개의 주제어를 획득한 후, 공통단어 56개를 도출해서 사고종류별 최적의 최소 단어를 추정하였다. 추정한 최소 단어는 파레토 차트(Pareto chart)를 이용하여 유효성을 입증하고, 축소율을 이용하여 축소 효율을 평가하였다. 연구결 과를 요약하면 다음과 같다.
첫째, 추정한 최소 단어의 수와 파레토 차트로 분석한 최소 단어의 수가 일치하여 추정한 단어가 유효함을 확인하였다.
둘째, 축소율의 최대는 64.7%, 최소는 45.5%로 나타났고, 아홉 가지 사고종류 전체에 대해서는 57.1%로 나타났으며, 평 균 축소율은 58.5%로 나타났다. 따라서 평균적으로 공통단어 의 58.5%만 이용하더라도 사고의 80% 이상을 설명할 수 있는 최소 단어를 추정할 수 있었다. 이를 통해서 체계적인 주제어 구축 프레임 개발에 필요한 최소의 단어를 획득하였다.
셋째, 파레토 법칙을 이용하여 방대한 단어를 최적의 최소 단어로 축소할 수 있는 기법을 제안하였다. 제안한 기법은 단 어로 구성된 데이터뿐만 아니라 다양하고 방대한 해양사고 데 이터의 차원을 축소하는 경우에도 적용 가능할 것으로 고려된 다.
추후, 본 연구에서 축소한 단어를 이용하여 주제어를 체계 적으로 작성할 수 있는 프레임을 구축할 예정이다.
 PDF Links
PDF Links PubReader
PubReader Full text via DOI
Full text via DOI Download Citation
Download Citation Print
Print