1. ņä£ ļĪĀ
1.1. ņŚ░ĻĄ¼ ļ░░Ļ▓Į ļ░Å ĒĢäņÜöņä▒
ņ¢┤ļĪ£ ņé░ņŚģņØĆ Ļ│Āņ£äĒŚśņä▒ ņŚģņóģ ņżæ ĒĢśļéśļĪ£, ņ¢┤ņäĀ ņĀäļ│Ą ņé¼Ļ│ĀļŖö ņØ┤ļ¤¼ĒĢ£ ņé░ņŚģņŚÉņä£ ņŗ¼Ļ░üĒĢ£ ļ¼ĖņĀ£ ņżæ ĒĢśļéśļĪ£ ļČĆņāüĒĢśĻ│Ā ņ׳ļŗż.
Fig. 1Ļ│╝ Ļ░ÖņØ┤ ņĄ£ĻĘ╝ 5ļģäĻ░ä ņäĀļ░Ģ ņĀäļ│Ą ņé¼Ļ│ĀņØś ņĀłļ░ś ņØ┤ņāüņØ┤ ņ¢┤ņäĀņŚÉņä£ ļ░£ņāØĒĢśĻ│Ā ņ׳ļŗż(Korean Maritime Safety Tribunal, 2023). 2023ļģä 2ņøö ņĄ£ĻĘ╝ņŚÉļŖö ņŗĀņĢł ĒĢ┤ņāüņŚÉņä£ ņ¢┤ņäĀņØ┤ ņĀäļ│ĄļÉśņ¢┤ ļŗżņłśņØś ņäĀņøÉņØ┤ ņŗżņóģļÉśļŖö ņé¼Ļ│ĀĻ░Ć ļ░£ņāØĒĢśņśĆļŗż(BBC News Korea, 2023). ņ¢┤ņäĀ ņĀäļ│ĄņØś ņøÉņØĖņ£╝ļĪ£ļŖö ņäĀņ▓┤ ļ¼┤Ļ▓ī ņżæņŗ¼ņØś Ļ┤Ćļ”¼ ļČĆņŗż, ĻĖ░ņāü ņĢģĒÖö ļō▒ņ£╝ļĪ£ ņØĖĒĢ┤ ļ│ĄņøÉļĀź ņāüņŗżņØ┤ ņŻ╝ļÉ£ ņøÉņØĖņ£╝ļĪ£ ņ¢┤ņäĀņØĆ ņāüņäĀņŚÉ ļ╣äĒĢ┤ ĻĘĖ Ēü¼ĻĖ░Ļ░Ć ņ×æņ£╝ļ®░ ļö░ļØ╝ņä£ ļ│ĄņøÉļĀźņØä ņēĮĻ▓ī ņ×āņØä ņłś ņ׳ļŗż(Kim, et al. 2023).
ĻĘĖļ¤¼ļéś ņŗżņĀ£ ņ¢┤ņäĀņØś ņĀäļ│Ą ņāüĒÖ®ņØä Ļ│äņĖĪĒĢśņŚ¼ ņāüĒÖ®ņØś ņ£äĒŚśņä▒ņØä ĒīÉļŗ©ĒĢśņŚ¼ņĢ╝ ĒĢśņ¦Ćļ¦ī ĒśäņŗżņĀüņ£╝ļĪ£ ļČłĻ░ĆļŖźĒĢśļŗż. ĻĖ░ņĪ┤ņØś ņ¢┤ņäĀ ņĀäļ│Ą ņé¼Ļ│Ā ņŚ░ĻĄ¼ļŖö ņŻ╝ļĪ£ Ļ░£ļ│äņĀüņØĖ ņé¼Ļ│Ā ņé¼ļĪĆļź╝ ļČäņäØĒĢśļŖö ļŹ░ ņżæņĀÉņØä ļæÉņŚłņ£╝ļ®░, ņØ┤ļŖö ņé¼Ļ│ĀĻ░Ć ņØ┤ļ»Ė ļ░£ņāØĒĢ£ ĒøäņŚÉ ļīĆņØæĒĢśļŖö ļ░®ļ▓ĢņŚÉ ļŹö ņ¦æņżæļÉśņ¢┤ ņ׳ņŚłļŗż. ņØ┤ņÖĆ Ļ░ÖņØ┤ ņé¼Ļ│Ā ņśłļ░®ņØä ņ£äĒĢ£ ļŗżņĖĄņĀüņØ┤Ļ│Ā ĒåĄĒĢ®ņĀüņØĖ ņĢłņĀä ņĀäļץņŚÉ ļīĆĒĢ£ ņŚ░ĻĄ¼ļŖö ļČĆņĪ▒ĒĢ£ ņŗżņĀĢņØ┤ļŗż.
ņØ┤ņŚÉ ļö░ļØ╝ ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņ¢┤ņäĀņØś ĒÜĪļÅÖņÜöņØś ņÜ┤ļÅÖ ĒŖ╣ņä▒ņØä ņČöņČ£ĒĢśņŚ¼ ļöźļ¤¼ļŗØņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ĒÜĪļÅÖņÜö Ļ░üļÅäļź╝ ņśłņĖĪ ļ░Å ņ¢┤ņäĀ ņĀäļ│Ą ņé¼Ļ│Ā ņ£äĒŚśņØä ļ░®ņ¦ĆĒĢśĻ│Āņ×É ĒĢ£ļŗż.
1.2. ņŚ░ĻĄ¼ ļ░®ļ▓Ģ
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņ¢┤ņäĀņØś ĒÜĪļÅÖņÜö ņÜ┤ļÅÖņØä ņśłņĖĪĒĢśĻĖ░ ņ£äĒĢ┤ ņØ┤ļ»Ėņ¦Ć ĻĖ░ļ░ś ņŗ¼ņĖĄ ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØä ĒÖ£ņÜ®ĒĢśĻ│Āņ×É ĒĢ£ļŗż.
a. ļŹ░ņØ┤Ēä░ ņłśņ¦æ ļ░Å ņĀäņ▓śļ”¼
ņŗ£Ļ│äņŚ┤ ņ¢┤ņäĀ ĒÜĪļÅÖņÜö ļŹ░ņØ┤Ēä░ļź╝ ņłśņ¦æĒĢ£ļŗż. ņłśņ¦æļÉ£ ļŹ░ņØ┤Ēä░ļź╝ ņĀĢņĀ£ĒĢśĻ│Ā ļČłņÖäņĀäĒĢ£ ļŹ░ņØ┤Ēä░ļéś ņØ┤ņāüņ╣śļź╝ ņ▓śļ”¼ĒĢśņŚ¼ ĒĢÖņŖĄņŚÉ ņĀüĒĢ®ĒĢ£ ĒśĢĒā£ļĪ£ Ļ░ĆĻ│ĄĒĢ£ļŗż.
b. ļöźļ¤¼ļŗØ ļ¬©ļŹĖ ņäżĻ│ä
Xception, ResNet50, CRNNņØś ļöźļ¤¼ļŗØ ņĢäĒéżĒģŹņ▓śļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ ļ¬©ļŹĖņØä ņäżĻ│äĒĢ£ļŗż. CNN(Convolutional Neural Network)ņØĆ RNN(Recurrent Neural Network) ĻĖ░ļ░ś ļ¬©ĒśĢļ│┤ļŗż Ļ│äņé░ ļ│Ąņ×ĪļÅäĻ░Ć ņĀüļŗż(Ashish, V. et al. 2017). CNNņØĆ Ļ│ĀņĀĢļÉ£ ņ×ģļĀź ļŹ░ņØ┤Ēä░ņÖĆ Ļ│ĀņĀĢļÉ£ ņČ£ļĀź ļŹ░ņØ┤Ēä░ņØĖ ļ░śļ®┤ RNNņØĆ ņ×äņØśņØś ņ×ģļĀź, ņČ£ļĀź ļŹ░ņØ┤Ēä░ļź╝ ļŗżļŻ©ļ»ĆļĪ£ Ļ│äņé░ ņŗ£Ļ░äņØ┤ ļŹö ņśżļל Ļ▒Ėļ”░ļŗż. ļśÉĒĢ£ CNNņØĆ ņŗ£ņ░©ļź╝ ņé¼ņĀäņŚÉ ņ×ģļĀźĒĢĀ ĒĢäņÜöĻ░Ć ņŚåļŗżļŖö ņןņĀÉņØ┤ ņ׳ļŗż. DNN(Deep Neural Network) ļ¬©ĒśĢņØś Ļ▓ĮņÜ░, ņ×ģļĀź ļ│ĆņłśņØś ņŗ£ņ░©ļź╝ ņ¢╝ļ¦łļĪ£ ĒĢ┤ņĢ╝ ĒĢĀņ¦Ć Ļ▓░ņĀĢĒĢ┤ņĢ╝ ĒĢśļ®░ ņŗ£Ļ│äņŚ┤ņØś ņČöņäĖļéś Ļ│äņĀłņä▒, ņĀĢņŻ╝ņä▒ ļō▒ņØä ĒÖĢņØĖ Ēøä ļŹ░ņØ┤Ēä░Ļ░Ć ņĀĢņŻ╝ņä▒ņØä Ļ░¢ļÅäļĪØ ĒĢ┤ņĢ╝ ĒĢśļŖö ļō▒ ņŚ¼ļ¤¼ Ļ░Ćņ¦Ć ņżĆļ╣äĻ░Ć ĒĢäņÜöĒĢśļéś Xception, ResNet50, CRNNĻ│╝ Ļ░ÖņØĆ ņØ┤ļ»Ėņ¦Ć ĻĖ░ļ░ś ļ¬©ĒśĢņØś Ļ▓ĮņÜ░, ļé┤ļČĆņĀüņ£╝ļĪ£ ņ×ÉļÅÖņĀüņ£╝ļĪ£ ņ▓śļ”¼ļÉ£ļŗżļŖö ņØ┤ņĀÉņØ┤ ņ׳ļŗż.
c. ļ¬©ļŹĖ ĒĢÖņŖĄ
ĒĢÖņŖĄ ļŹ░ņØ┤Ēä░ņģŗņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØä ĒĢÖņŖĄņŗ£Ēé©ļŗż. ņØ┤ļĢī, ĒøłļĀ© ļŹ░ņØ┤Ēä░ņÖĆ Ļ▓Ćņ”Ø ļŹ░ņØ┤Ēä░ļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ Ļ│╝ņĀüĒĢ®ņØä ļ░®ņ¦ĆĒĢśĻ│Ā ļ¬©ļŹĖņØś ņØ╝ļ░śĒÖö ņä▒ļŖźņØä ļåÆņØĖļŗż. ņśżņ░© ĒĢ©ņłśļź╝ ņĀĢņØśĒĢśĻ│Ā ņĄ£ņĀüĒÖö ņĢīĻ│Āļ”¼ņ”śņØä ņäĀĒāØĒĢśņŚ¼ ļ¬©ļŹĖņØä ĒøłļĀ©ņŗ£Ēé©ļŗż.
1.3. ĻĄŁļé┤ņÖĖ ņŚ░ĻĄ¼ ĒśäĒÖ®
ļöźļ¤¼ļŗØņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ņØ┤ļ»Ėņ¦Ć ņŚ░ĻĄ¼, ņ×ÉņŚ░ņ¢┤ ņ▓śļ”¼ ņŚ░ĻĄ¼ ļō▒Ļ│╝ Ļ░ÖņØĆ ļŗżņ¢æĒĢ£ ļČäņĢ╝ņŚÉņä£ ĻĖ░ņłĀņĀü ņ¦äļ│┤ļź╝ ņØ┤ļŻ©Ļ│Ā ņ׳ļŗż. ņäĀļ░ĢĻ│╝ Ļ┤ĆļĀ©ļÉ£ ņŚ░ĻĄ¼ņØś Ļ▓ĮņÜ░, Ļ░ĢĒÖö ĒĢÖņŖĄņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ņäĀļ░ĢņØś ĒĢŁļĪ£ļź╝ ņāØņä▒ĒĢśļŖö ņŚ░ĻĄ¼Ļ░Ć ņĀ£ņĢłļÉśņŚłļŗż(Kim et al. 2023). ļśÉĒĢ£ ņäĀļ░Ģ ņŚ░ļŻī Ļ│äĒåĄ ņןļ╣äņØś Ļ│Āņן ņ¦äļŗ©ņØä ņ£äĒĢ£ ņŚ░ĻĄ¼Ļ░Ć ņĀ£ņĢłļÉśņŚłļŗż(Kim, H. et al. 2022). ĒĢŁļ¦īĻ│╝ Ļ┤ĆļĀ©ĒĢśņŚ¼ ļČĆņé░ ņŗĀĒĢŁņØś ņ╗©ĒģīņØ┤ļäł ļ░śņČ£ņ×ģ ņĀĢļ│┤ļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ ļöźļ¤¼ļŗØ ĻĖ░ļ░śņØś ļ░śņČ£ņ×ģ ņ░©ļ¤ē ĒÅēĻĘĀ ļīĆĻĖ░ ņŗ£Ļ░äņØä ņśłņĖĪĒĢśļŖö ļ¬©ĒśĢņØ┤ ņĀ£ņĢłļÉśņŚłļŗż(Kim et al. 2022).
ņäĀļ░Ģ ĒÜĪļÅÖņÜöņÖĆ Ļ┤ĆļĀ©ļÉ£ ņŚ░ĻĄ¼ļŖö ļŗżņØīĻ│╝ Ļ░Öļŗż. Suhermi et al.(2018)ļŖö ARIMAņÖĆ ļŗżņĖĄ ĒŹ╝ņģēĒŖĖļĪĀ ņŗĀĻ▓Įļ¦Ø(DNN) ļ¬©ļŹĖņØä Ļ▓░ĒĢ®ĒĢśļŖö Ēś╝ĒĢ® ļ░®ļ▓ĢņØä ņ▒äĒāØĒĢśņśĆļŗż. ņé¼ņÜ®ļÉ£ ņŗżņĀ£ ļŹ░ņØ┤Ēä░ļŖö ļČĆņ£ĀņŗØ ņāØņé░ ņ£Āļŗø(FPU)ņØś ĒÜĪļÅÖņÜö ļ¬©ņģśņØ┤ļ®░ ņŗżĒŚś Ļ▓░Ļ│╝ļŖö DNN-ARIMA Ēś╝ĒĢ® ļ¬©ļŹĖņØ┤ ļ╣ä Ēś╝ĒĢ® ļ¬©ļŹĖņŚÉ ļ╣äĒĢ┤ ļĪż ļ¬©ņģśņØä ņśłņĖĪĒĢśļŖö ļŹ░ Ļ░Ćņן ņÜ░ņłśĒĢ£ ļ¬©ļŹĖņØ┤ļ®░ ņśłņĖĪ ņĀĢĒÖĢļÅäļź╝ Ēü¼Ļ▓ī Ē¢źņāüņŗ£ĒéżļŖöļŹ░ ļ¦żņÜ░ ĒÜ©Ļ│╝ņĀüņ×äņØä ļ│┤ņŚ¼ņŻ╝ņŚłļŗż. Zhou et al.(2023)ņØĆ ļöźļ¤¼ļŗØ ļäżĒŖĖņøīĒü¼ņÖĆ ļ¦żĻ░£ļ│ĆņłśļĪĀņĀü ļ░®ņĀĢņŗØņØä Ļ▓░ĒĢ®ĒĢ£ ŌĆ£ĻĘĖļĀłņØ┤ ļ░ĢņŖżŌĆØ ņĢīĻ│Āļ”¼ņ”śņØä ņĀ£ņĢłĒĢśņśĆļŗż. ņŻ╝ņä▒ļČä ļČäņäØņØ┤ļØ╝ļŖö ĻĖ░ļ│Ė ļ╣äņ¦ĆļÅä ĒĢÖņŖĄ ļ░®ļ▓ĢņØä ļÅäņ×ģĒĢśņŚ¼ ĒÜ©ņ£©ņä▒Ļ│╝ ņĀĢĒÖĢļÅäļź╝ Ē¢źņāüņŗ£ņ╝░ļŗż. ņŗżĒŚś Ļ▓░Ļ│╝ ņŻ╝ņä▒ļČä ļČäņäØ ļ░Å ŌĆ£ĻĘĖļĀłņØ┤ ļ░ĢņŖżŌĆØ ĻĖ░ļ░ś ĒĢÖņŖĄ ļ¬©ļŹĖņØä ņé¼ņÜ®ĒĢśņŚ¼ ņ╗©ĒģīņØ┤ļäłņäĀņØś ĒÜĪļÅÖņÜöļź╝ ņ¦¦ņØĆ ņŗ£Ļ░ä ļé┤ņŚÉ ņĀĢĒÖĢĒĢśĻ▓ī ņŗ£ļ«¼ļĀłņØ┤ņģś ĒĢĀ ņłś ņ׳ņŚłļŗż. El et al.(2023)ļŖö ņäĀļ░Ģ ņåŹļÅä ņČöņĀĢņØä ņ£äĒĢ┤ Ļ│╝Ļ▒░ ļŹ░ņØ┤Ēä░ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ļöźļ¤¼ļŗØ ĻĖ░ļ▓ĢņØä ņĀ£ņĢłĒĢśņśĆļŗż. ĻĘĖļ¤¼ļéś ņä▒ļŖź Ē¢źņāüņØ┤ ĒĢäņÜöĒĢ┤ ļ│┤ņØ┤ļ®░ ļöź ļ¤¼ļŗØ ļ¬©ļŹĖņØś ĒĢ┤ņäØ Ļ░ĆļŖźņä▒ņØ┤ ļČĆņĪ▒ĒĢśļŗżļŖö ņĀÉņØä ņČöĒøä Ļ│╝ņĀ£ļĪ£ ņ¢ĖĻĖēĒĢśņśĆļŗż. Alvarellos et al.(2021)ļŖö ņĀĢļ░ĢļÉ£ ņäĀļ░ĢņØś 6 ņ×Éņ£ĀļÅä ņÜ┤ļÅÖņØä ņśłņĖĪĒĢśĻĖ░ ņ£äĒĢ┤ ņŗĀĻ▓Įļ¦Ø ļ░Å ĻĘĖļלļööņ¢ĖĒŖĖ ļČĆņŖżĒīģ ļ¬©ļŹĖņØä ĒÖ£ņÜ®ĒĢśņśĆļŗż. ĻĘĖļ¤¼ļéś ĒĢŁļ¦īņŚÉņä£ ņØ╝ņ¢┤ļéśļŖö ĒśäņŗżņĀüņØĖ ņØ╝ņØä ļ¬©ļŹĖņŚÉ ĒżĒĢ©ĒĢśņŚ¼ņĢ╝ ĒĢśļ®░ ņóüņØĆ ĒåĄļĪ£, ņŚ░ļŻī ņåīļ╣ä ļō▒ļÅä Ļ│ĀļĀżĒĢ┤ņĢ╝ ĒĢĀ ņé¼ĒĢŁņØ┤ļØ╝ ņ¢ĖĻĖēĒĢśņśĆļŗż. Lin et al.(2022)ļŖö ņäĀļ░ĢņØś ĒÜĪļÅÖņÜö ļ░®ņ¦Ćļź╝ ņśłņĖĪĒĢśĻĖ░ ņ£äĒĢ┤ ņŗ¼ņĖĄ Ļ░ĢĒÖö ĒĢÖņŖĄņØä ĻĖ░ļ░śņ£╝ļĪ£ DDPG ņĢīĻ│Āļ”¼ņ”śņØä ĒÖ£ņÜ®ĒĢśņśĆļŗż. ĒÜĪļÅÖņÜö ļ░®ņ¦Ć ĒÜ©ņ£©ņØ┤ 95%ļź╝ ļäśņ¢┤ ļ╣©ļ”¼ ņĢłņĀĢņĀüņ£╝ļĪ£ ņłśļĀ┤ĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆļŗż. Kim et al.(2018)ļŖö ĻĖ░Ļ│äĒĢÖņŖĄ ĻĖ░ļ░śņØś ĻĘ╝ņé¼ ļ¬©ļŹĖņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ĒÜĪļÅÖņÜö ņÜ┤ļÅÖ ĒŖ╣ņä▒ņØä ņśłņĖĪĒĢśĻ│Āņ×É ĒĢśņśĆļŗż. ņČöĻ░Ć ņŚ░ĻĄ¼ļĪ£ ņäĀņóģ, ņÜ┤ĒĢŁ ĒŖ╣ņä▒(ĒØśņłś, ļ¼┤Ļ▓ī ņżæņŗ¼) ļō▒ņØ┤ ļ░śņśüļÉśņ¢┤ņĢ╝ ĒĢ£ļŗżĻ│Ā ņ¢ĖĻĖēĒĢśņśĆļŗż.
ņĀ£ņĢłļÉ£ ņŚ░ĻĄ¼ņŚÉņä£ļŖö ļīĆĒśĢ ņāüņäĀņŚÉ ļ╣äĒĢ┤ Ļ┤Ćņŗ¼ņ׳ļŖö ļČäņĢ╝ņØś ņŚ░ĻĄ¼ ņŻ╝ņĀ£Ļ░Ć ņĢäļŗłļ®░ ņ¢┤ņäĀņØś ņ×”ņØĆ ĒÜĪļÅÖņÜö ņŻ╝ĻĖ░Ļ░Ć Ļ│ĀļĀżļÉśņ¦Ć ņĢŖņØĆ ņĀÉ, ņ¢┤ņäĀņØś ņŗ£Ļ│äņŚ┤ ĒÜĪļÅÖņÜö ļŹ░ņØ┤Ēä░ļź╝ ņłśņ¦æĒĢśĻĖ░ ņ¢┤ļĀżņÜ┤ ļ¼ĖņĀ£ņĀÉņØ┤ ņ׳ņŚłļŗż.
1.4. ļ│Ė ņŚ░ĻĄ¼ņØś ņØśņØś
- ņØ┤ļ»Ėņ¦Ć ĻĖ░ļ░ś ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØä ņŗ£Ļ│äņŚ┤ ļ¬©ļŹĖņŚÉ ņĀüņÜ®ĒĢśņśĆļŗż. ĒŖ╣Ē׳ ņŗ£Ļ░äņŚÉ ļö░ļźĖ Ēī©Ēä┤ņØä Ļ░Éņ¦ĆĒĢśĻ│Ā ņśłņĖĪĒĢśļŖöļŹ░ ĒÜ©Ļ│╝ņĀüņØ┤ļŗż. ņØ┤ļź╝ ĒåĄĒĢ┤ ņŗ£Ļ│äņŚ┤ ļŹ░ņØ┤Ēä░ņØś ļŗżņ¢æĒĢ£ Ēī©Ēä┤Ļ│╝ ĻĄ¼ņĪ░ļź╝ ņØĖņŗØĒĢĀ ņłś ņ׳ļŗż. ļśÉĒĢ£ ļé«ņØĆ ņłśņżĆņØś ĒŖ╣ņ¦ĢļČĆĒä░ Ļ│ĀņłśņżĆņØś ņČöņāüņĀüņØĖ ĒŖ╣ņ¦ĢĻ╣īņ¦Ć ĒĢÖņŖĄĒĢśņŚ¼ ļ│Ąņ×ĪĒĢ£ Ēī©Ēä┤ņØä ĒĢÖņŖĄĒĢĀ ņłś ņ׳ļŗż.
- ņŗ£Ļ│äņŚ┤ ņśłņĖĪņŚÉ ResNet50ņØś ņ×öņ░© ļĖöļĪØņØä ņé¼ņÜ®ĒĢśņŚ¼ ĻĖ░ņĪ┤ņØś ļĀłņØ┤ņ¢┤ļź╝ Ļ▒┤ļäłļø░Ļ▓ī ĒĢ©ņ£╝ļĪ£ņŹ© ĻĘĖļĀłļööņ¢ĖĒŖĖ ņåīņŗż ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢĀ ņłś ņ׳ļŗż.
- ņ¢┤ņäĀņØś ņŗ£Ļ│äņŚ┤ ĒÜĪļÅÖņÜö ļŹ░ņØ┤Ēä░ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ĒÜĪļÅÖņÜö Ļ░üļÅäļź╝ ņśłņĖĪĒĢśņŚ¼ ņĀäļ│Ą ņé¼Ļ│Ā ļ░®ņ¦ĆņŚÉ ĻĖ░ņŚ¼ĒĢĀ ņłś ņ׳ļŗż.
2. ņŗ¼ņĖĄ ļäżĒŖĖņøīĒü¼ ļ¬©ļŹĖ
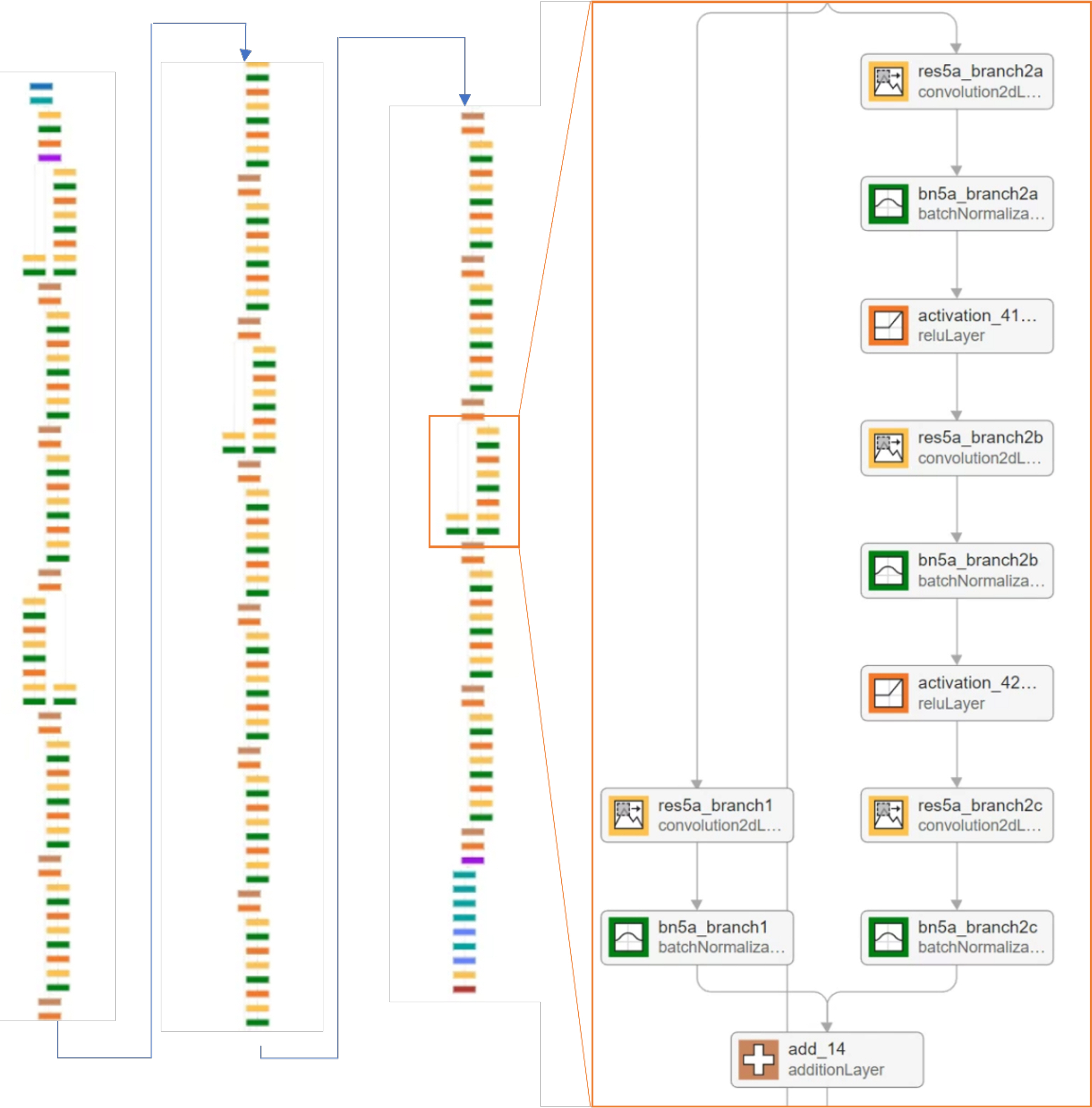
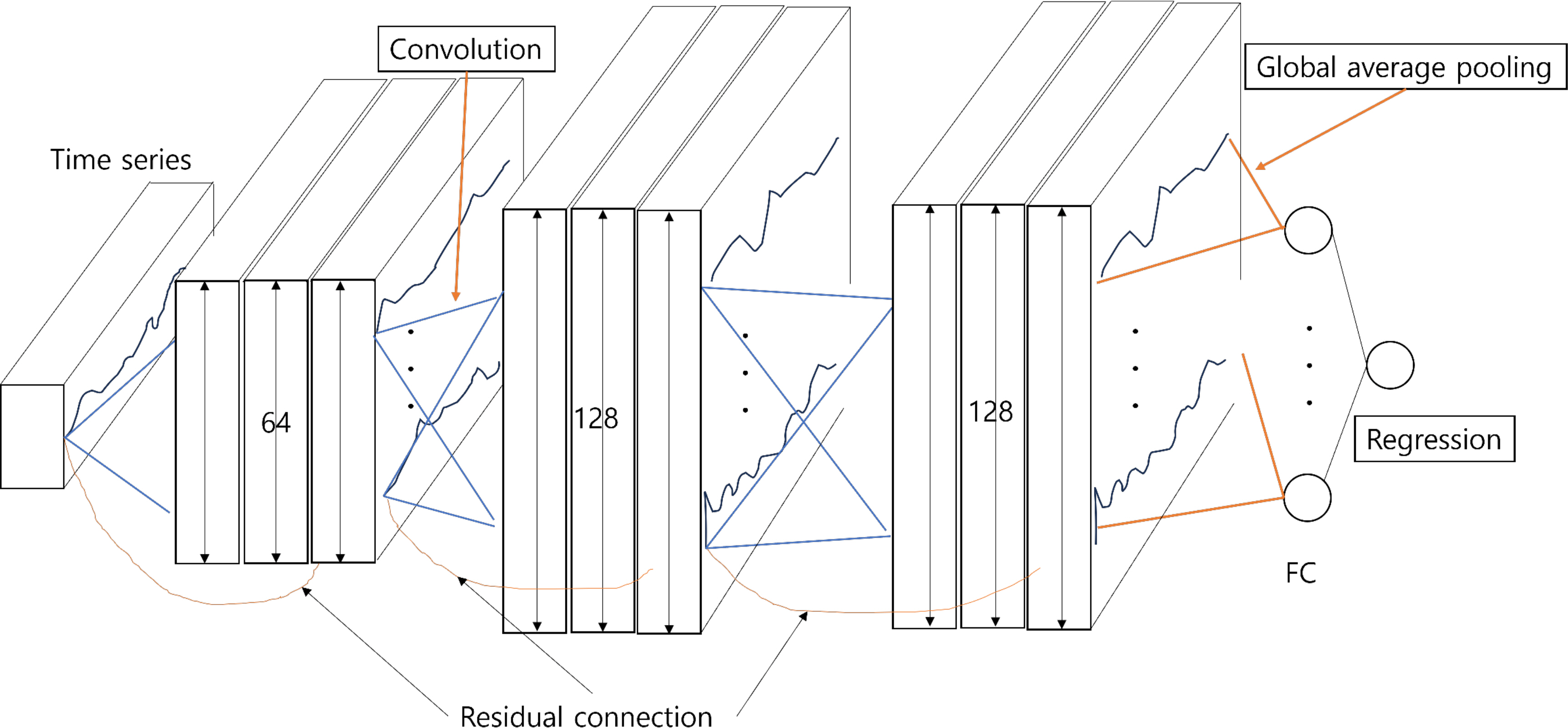
ļ¦łņØ┤Ēü¼ļĪ£ņåīĒöäĒŖĖņŚÉņä£ Ļ░£ļ░£ĒĢ£ ResNet ņĢīĻ│Āļ”¼ņ”śņØĆ ņØ┤ņĀä ļ¬©ļŹĖļōżĻ│╝ļŖö ļŗ¼ļ”¼, ļĀłņØ┤ņ¢┤ņØś ņ”ØĻ░Ćļ│┤ļŗżļŖö ļĀłņØ┤ņ¢┤ ļé┤ņŚÉņä£ņØś ņĀĢļ│┤ ņĀäļŗ¼ņŚÉ ņżæņĀÉņØä ļæö ļ░®ļ▓ĢņØä ļÅäņ×ģĒĢśņśĆļŗż(He et al. 2016). ņØ┤ņĀäĻ╣īņ¦ĆļŖö ņŗĀĻ▓Įļ¦ØņØä Ļ╣ŖĻ▓ī ņīōņĢäņä£ ļåÆņØĆ ņä▒ļŖźņØä ņ¢╗ļŖö Ļ▓āņŚÉ ņŻ╝ļĀźĒ¢łņ¦Ćļ¦ī, ņØ┤ļŖö Ļ╣Ŗņ¢┤ņ¦łņłśļĪØ ņŚŁĒ¢ēļĀ¼ņØś ĻĖ░ņÜĖĻĖ░Ļ░Ć ņåīļ®ĖĒĢśļŖö ĻĖ░ņÜĖĻĖ░ ņåīļ®Ė ļ¼ĖņĀ£ļź╝ ņĢ╝ĻĖ░ĒĢśņśĆļŗż. ResNetņØĆ ņØ┤ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ┤ ņ×öņ░© ļĖöļĪØņØä ļÅäņ×ģĒĢśņśĆļŗż. ResNet50ņØĆ 50Ļ░£ņØś ĒĢ®ņä▒Ļ│▒ ņĖĄņ£╝ļĪ£ ĻĄ¼ņä▒ļÉśņ¢┤ ņ׳ņ£╝ļ®░ Fig. 2ņÖĆ Ļ░ÖņØ┤ ņ×ģļĀź Ļ░ÆņØ┤ ņČ£ļĀź Ļ░ÆņŚÉ ņ¦üņĀæ ļŹöĒĢ┤ņ¦ĆļŖö ŌĆśņ¦Ćļ”äĻĖĖ(shortcut)ŌĆÖ ĻĄ¼ņĪ░ļź╝ ņ▒äĒāØĒĢśņśĆļŗż. ŌĆśIdentity mappingŌĆÖņØĆ ņ×ģļĀź xĻ░Ć ņ¢┤ļ¢ż ĒĢ©ņłśļź╝ ĒåĄĻ│╝ĒĢśļŹöļØ╝ļÅä ņČ£ļĀźņØ┤ xļĪ£ ņ£Āņ¦ĆļÉśļÅäļĪØ ĒĢ£ļŗż. ņØ┤ļź╝ ĒåĄĒĢ┤ ņĖĄņØ┤ ļ¦ÄņĢäņĀĖļÅä ņ×ģļĀź Ļ░ÆņØ┤ ņåīņŗżļÉśļŖö ĻĖ░ņÜĖĻĖ░ ņåīļ®Ė ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢĀ ņłś ņ׳ņŚłļŗż. Fig. 3ņØĆ ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ ņé¼ņÜ®ĒĢ£ ResNet-50ņØś ņĢäĒéżĒģŹņ▓śļĪ£, ņ┤Ø 184Ļ░£ņØś ņĖĄņ£╝ļĪ£ ņØ┤ļŻ©ņ¢┤ņĀĖ ņ׳ļŗż.
Fig. 4ļŖö ņŗ£Ļ│äņŚ┤ ļŹ░ņØ┤Ēä░ ņśłņĖĪņŚÉ ļīĆĒĢ£ ļé┤ņÜ®ņØ┤ļŗż. ļ©╝ņĀĆ ņŗ£Ļ│äņŚ┤ ļŹ░ņØ┤Ēä░ļź╝ 1ņ░©ņøÉ ĒśĢĒā£ļĪ£ ļ│ĆĒÖśĒĢ£ļŗż. ļŹ░ņØ┤Ēä░ļź╝ ņ×æņØĆ ņ£łļÅäņÜ░ļĪ£ ļéśļłłļŗż. ņśłļź╝ ļōżņ¢┤ 30Ļ░£ņØś ļŹ░ņØ┤Ēä░ļź╝ ĒĢśļéśņØś ņ£łļÅäņÜ░ļĪ£ ņ¦ĆņĀĢĒĢ£ļŗż. ņ£łļÅäņÜ░ļĪ£ ļéśļłł ļŹ░ņØ┤Ēä░ļŖö ĒĢ®ņä▒Ļ│▒ ļĀłņØ┤ņ¢┤ņŚÉ ņ×ģļĀźļÉ£ļŗż. ņØ┤Ēøä ĒĢ®ņä▒Ļ│▒ ļĀłņØ┤ņ¢┤ļŖö ņ£łļÅäņÜ░ ļé┤ņŚÉņä£ Ēī©Ēä┤ņØä Ļ░Éņ¦ĆĒĢśļ®░ ņØ┤Ļ▓āņØĆ ņŗ£Ļ│äņŚ┤ ļŹ░ņØ┤Ēä░ņŚÉņä£ ņŻ╝ĻĖ░ņä▒ņØ┤ļéś ļŗżļźĖ Ēī©Ēä┤ņØä ņ░ŠņØä ņłś ņ׳ļÅäļĪØ ĒĢ£ļŗż. ĒÆĆļ¦ü ļĀłņØ┤ņ¢┤ļŖö ņ░©ņøÉņØä ņżäņØ┤ļŖö ņŚŁĒĢĀņØä ĒĢśļ®░ ņĀäĻ▓░ĒĢ® ļĀłņØ┤ņ¢┤(Fully connected layer)ņÖĆ ņŚ░Ļ▓░ļÉśņ¢┤ ņ׳ļŗż. ņĀäĻ▓░ĒĢ® ļĀłņØ┤ņ¢┤ļŖö CNNņØś ņČ£ļĀźņØä ļ░øņĢä ņŗ£Ļ│äņŚ┤ ļŹ░ņØ┤Ēä░ņØś ļŗżņØī Ļ░ÆņØä ņśłņĖĪĒĢśĻĖ░ ņ£äĒĢ£ ļē┤ļ¤┤ ļäżĒŖĖņøīĒü¼ļź╝ ņČöĻ░ĆĒĢ£ļŗż. ĒÜīĻĘĆ ļ¼ĖņĀ£ņØś Ļ▓ĮņÜ░, ĒĢśļéśņØś ļē┤ļ¤░ņØä ņé¼ņÜ®ĒĢśļ®░ ĒÖ£ņä▒ĒÖö ĒĢ©ņłśļŖö ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖļŖöļŗż.
2.2 Xception
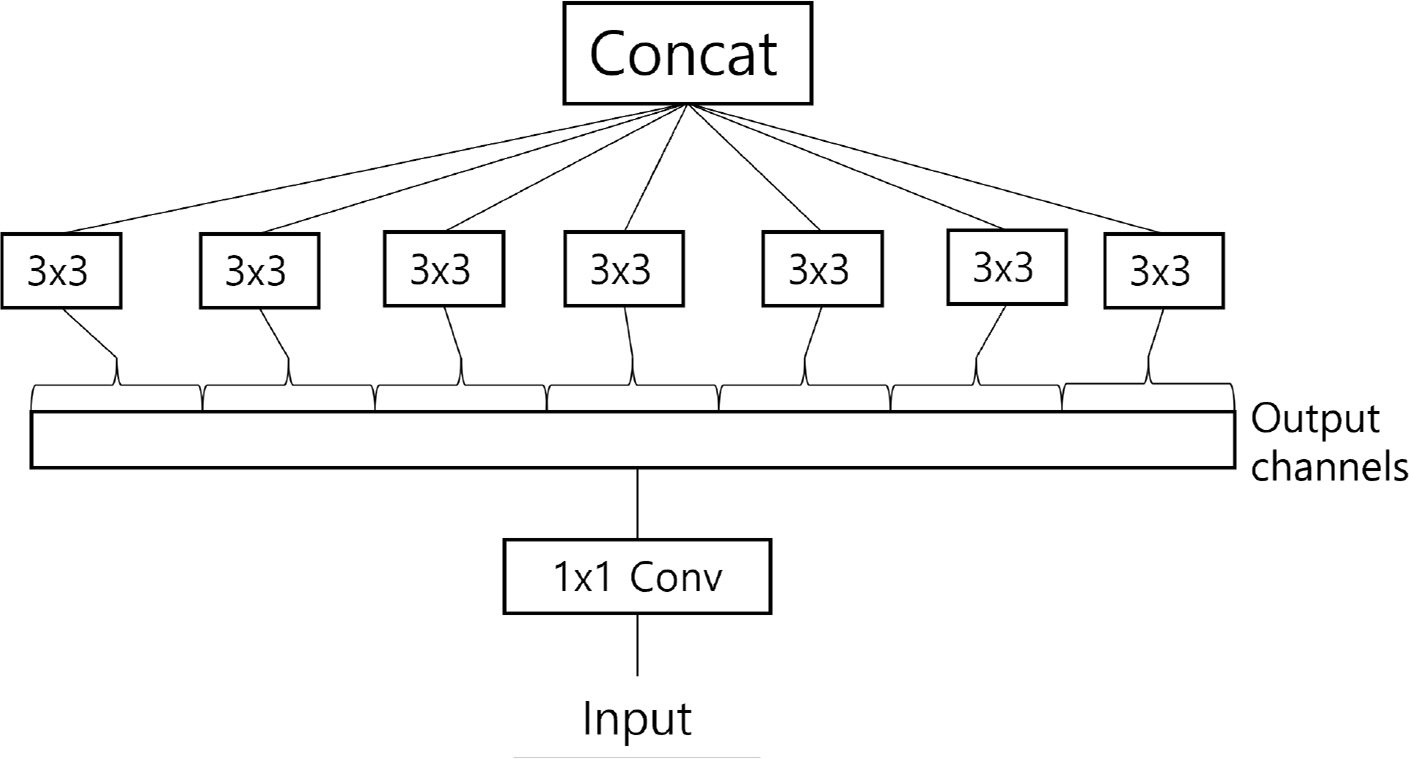
XceptionņØĆ ŌĆśeXtreme InceptionŌĆÖņØś ņĢĮņ×ÉļĪ£ Inception ļ¬©ļŹĖņØä ĻĖ░ļ░śņ£╝ļĪ£ Ļ░£ņäĀļÉ£ ĒśĢĒā£ņØ┤ļŗż(Chollet, 2017). ņØ┤ ļ¬©ļŹĖņØĆ ņ▒äļäÉĻ│╝ Ļ│ĄĻ░äņØä ļČäļ”¼ĒĢśĻ│Ā, ņØ┤ļź╝ Ļ╣ŖņØ┤ļ│ä ļČäļ”¼ Ļ░ĆļŖźĒĢ£ ĒĢ®ņä▒Ļ│▒ņ£╝ļĪ£ Ļ░ĢĒÖöĒĢ£ Ļ▓āņØ┤ļŗż. ņØ╝ļ░śņĀüņØĖ ĒĢ®ņä▒Ļ│▒ ņĖĄņØĆ ĒĢäĒä░ļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ļåÆņØ┤, ļäłļ╣ä, ņ▒äļäÉņØä ļ¬©ļæÉ ĒĢÖņŖĄĒĢśļĀż ĒĢ£ļŗż. ņØ┤ļŖö ĒĢśļéśņØś ĒĢäĒä░ļĪ£ ĻĄÉņ░© ņ▒äļäÉ ņāüĻ┤Ć Ļ┤ĆĻ│äņÖĆ Ļ│ĄĻ░ä ņāüĻ┤Ć Ļ┤ĆĻ│äļź╝ ļÅÖņŗ£ņŚÉ ļ¦żĒĢæĒĢ┤ņĢ╝ ĒĢśĻĖ░ ļĢīļ¼ĖņØ┤ļŗż. ĻĘĖļ¤¼ļéś XceptionņØĆ ĻĄÉņ░© ņ▒äļäÉ ņāüĻ┤Ć Ļ┤ĆĻ│äņÖĆ Ļ│ĄĻ░ä ņāüĻ┤Ć Ļ┤ĆĻ│äļź╝ ļÅģļ”ĮņĀüņ£╝ļĪ£ Ļ│äņé░ĒĢśĻ│Ā mapping ĒĢśĻĖ░ ņ£äĒĢ┤ Ļ│ĀņĢłļÉ£ ļ¬©ļŹĖņØ┤ļŗż.
Fig. 5ņŚÉņä£ņ▓śļ¤╝ ņ×ģļĀź ļŹ░ņØ┤Ēä░ļź╝ 1 x 1 ĒĢ®ņä▒Ļ│▒ņØä ņé¼ņÜ®ĒĢśņŚ¼ ņäĖĻĘĖļ©╝ĒŖĖļĪ£ ļéśļłł ļŗżņØī Ļ░ü ņäĖĻĘĖļ©╝ĒŖĖņŚÉ ļīĆĒĢ┤ ņØ╝ļ░śņĀüņØĖ ņ╗©ļ│╝ļŻ©ņģś ņŚ░ņé░ņØä ņłśĒ¢ēĒĢśĻ│Ā ņØ┤ļź╝ ņŚ░Ļ▓░(concatenation)ĒĢ£ļŗż. ĻĘĖļ¤¼ļéś XceptionņŚÉņä£ļŖö ņäĖ Ļ░£ļĪ£ ļéśļłäļŖö ļīĆņŗĀ, ņ▒äļäÉĻ│╝ Ļ│ĄĻ░ä ņāüĻ┤Ć Ļ┤ĆĻ│äļź╝ ņÖäņĀäĒ׳ ļČäļ”¼ĒĢśļŖö ņĢäņØ┤ļööņ¢┤ļź╝ ņĀ£ņĢłĒĢśņśĆļŗż. ļŗżņŗ£ ļ¦ÉĒĢ┤, Fig. 6ņŚÉņä£ņÖĆ Ļ░ÖņØ┤ 1 x 1 ņ╗©ļ│╝ļŻ©ņģśņØä ņé¼ņÜ®ĒĢśņŚ¼ ņ▒äļäÉ ņāüĻ┤Ć Ļ┤ĆĻ│äļź╝ ņ▓śļ”¼ĒĢ£ Ēøä, ņČ£ļĀź ņ▒äļäÉņŚÉ ļīĆĒĢ┤ Ļ│ĄĻ░ä ņ╗©ļ│╝ļŻ©ņģśņØä ņłśĒ¢ēĒĢ£ļŗż. ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ ņé¼ņÜ®ļÉ£ Xception ļ¬©ļŹĖņØĆ Fig. 7Ļ│╝ Ļ░Öņ£╝ļ®░ 177ņĖĄņ£╝ļĪ£ ĻĄ¼ņä▒ļÉśņŚłļŗż.
2.3. CRNN
ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø(CNN)ņØĆ ļŹ░ņØ┤Ēä░ņØś ĒŖ╣ņä▒ņØä ņČöņČ£ĒĢśĻ│Ā ņØ┤ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ļČäļźśĒĢśļŖö ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØ┤ļŗż(Yao et al. 2019). Ļ│╝ļÅäĒĢ£ ļŹ░ņØ┤Ēä░ ņåÉņŗżņŚÉ ļö░ļźĖ ņ¢ĖļŹö Ēö╝ĒīģņØ┤ ļ░£ņāØĒĢĀ ņłś ņ׳ņ¦Ćļ¦ī, ĒĢÖņŖĄ ņåŹļÅäĻ░Ć ļ╣Āļź┤ļ®░ ņśżļ▓ä Ēö╝Ēīģ Ļ░ĆļŖźņä▒ņØ┤ ņāüļīĆņĀüņ£╝ļĪ£ ļé«ļŗż. ņł£ĒÖś ņŗĀĻ▓Įļ¦Ø(RNN)ņØĆ ļŹ░ņØ┤Ēä░ņØś ņŗ£Ļ░äņĀü ņł£ņä£ ņĀĢļ│┤ļź╝ ĒÖ£ņÜ®ĒĢśļŖö ņ×¼ĻĘĆ ĻĄ¼ņĪ░ņØś ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØ┤ļ®░ ņ×ģņČ£ļĀź Ļ░£ņłśņŚÉ ļö░ļØ╝ ļŗżņ¢æĒĢ£ ļ¬©ļŹĖ ĻĄ¼ņä▒ņØ┤ Ļ░ĆļŖźĒĢśļŗż.
ĻĖ░ņĪ┤ ņŗ£Ļ│äņŚ┤ ņŚ░ĻĄ¼ņØś Ļ▓ĮņÜ░, S-CNN(Smoothed-CNN)ņØä ņĀ£ņĢłĒĢśņŚ¼ ņø╣ņé¼ņØ┤ĒŖĖ ļ░®ļ¼ĖĻ░Ø ņłśļź╝ ņśłņĖĪĒĢśņśĆļŗż. ļśÉĒĢ£ CNNĻĖ░ļ░ś ĒöäļĀłņ×ä ņøīĒü¼ļź╝ ņĀ£ņĢłĒĢśņŚ¼ ņŻ╝ņŗØ ņŗ£ņןņØä ņśłņĖĪĒĢśņśĆļŗż(Hoseinzade, E. and Haratizadeh, S., 2019).
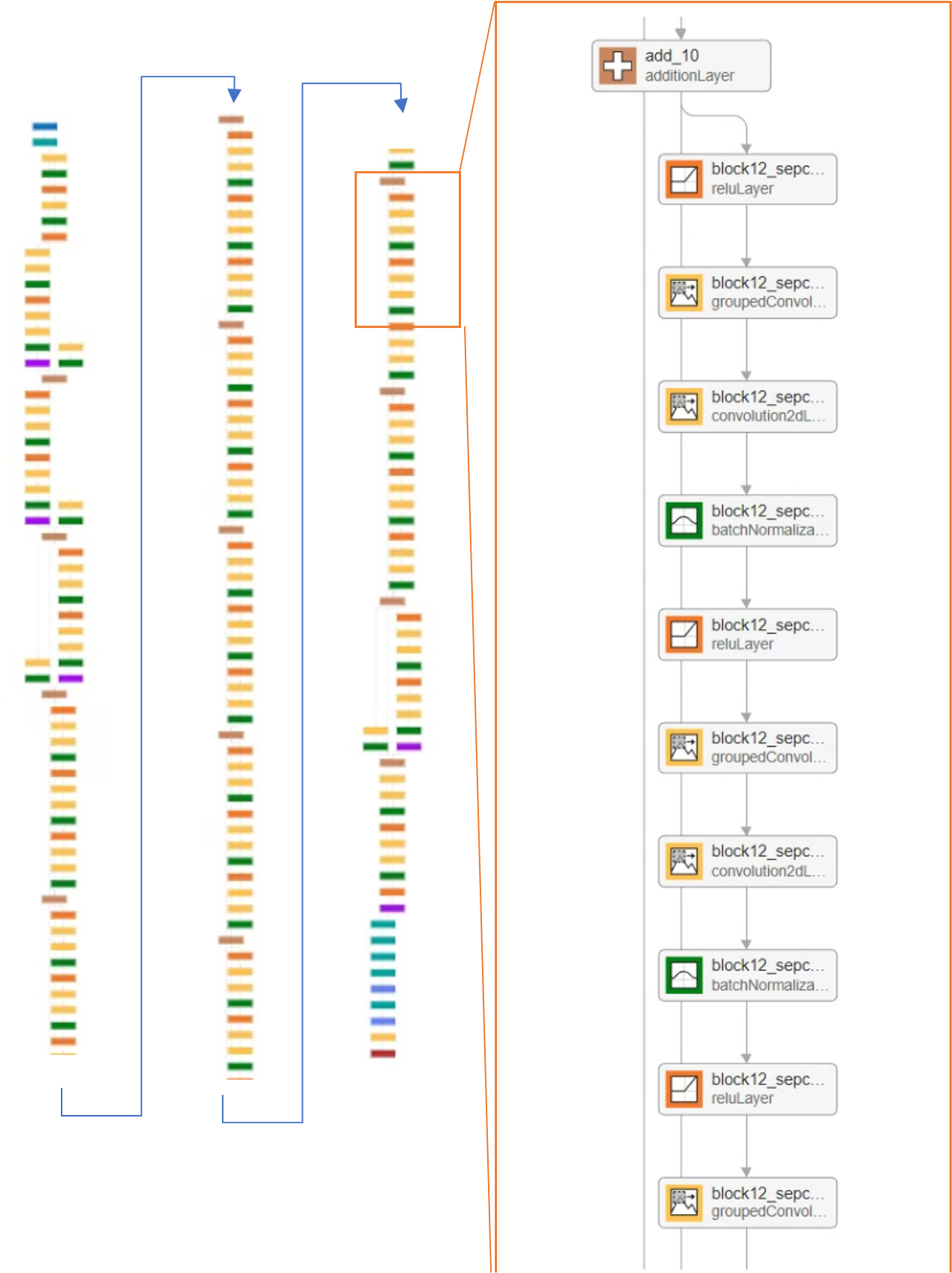
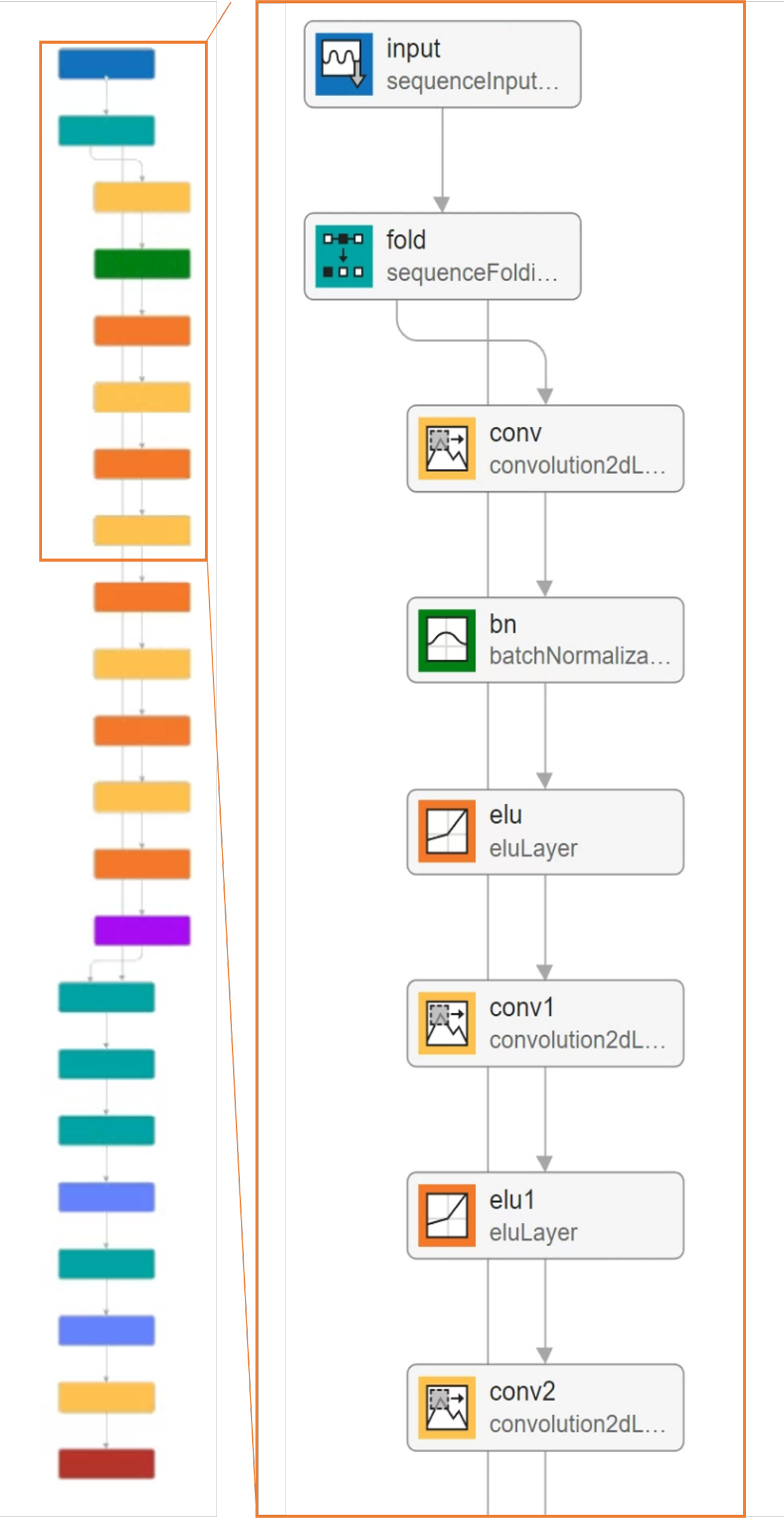
Fig. 8Ļ│╝ Ļ░ÖņØ┤ CRNNņØĆ ļ©╝ņĀĆ CNNņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ņŚ░ņé░ņØä ņłśĒ¢ēĒĢśĻ│Ā, Ļ░ü ņ▒äļäÉņØä ļéśļłł Ēøä RNNņŚÉ ņ×ģļĀźĒĢśļŖö ĻĄ¼ņĪ░ņØ┤ļŗż. RNNņŚÉļŖö GRU(Cho, K. et al. 2014)ņÖĆ LSTM(Hochreiter, S. and Schmidhuber J. 1997)ņØ┤ ņé¼ņÜ®ļÉśņŚłļŗż. ņŚ¼ĻĖ░ņä£, convolution 5 x 32ņŚÉņä£ 5ļŖö ĒĢäĒä░ņØś Ēü¼ĻĖ░ļź╝, 32ļŖö ĒĢäĒä░ņØś Ļ░£ņłśļź╝ ņØśļ»ĖĒĢ£ļŗż. ņØ┤ĒøäņŚÉļŖö Batch Normalization LayerĻ│╝ Exponential Linear Unit(ELU) ļĀłņØ┤ņ¢┤ļź╝ Ļ▒░ņ│É ĒÅēĻĘĀ ĒÆĆļ¦üņØä ņĀüņÜ®ĒĢ£ Ēøä ĒÅēĒÖ£ĒÖöĻ░Ć ņØ┤ļŻ©ņ¢┤ņ¦äļŗż. ļ¦łņ¦Ćļ¦ēņ£╝ļĪ£ GRUņÖĆ ļō£ļĪŁņĢäņøā, LSTMņØä Ļ▒░ņ╣śļ®┤ņä£ ĒĢÖņŖĄņØ┤ ņ¦äĒ¢ēļÉ£ļŗż. CRNN ņĖĄņØś ĻĄ¼ņĪ░ļŖö Fig. 9ņÖĆ Ļ░Öņ£╝ļ®░ 22Ļ░£ņØś ņĖĄņ£╝ļĪ£ ĻĄ¼ņä▒ļÉśņŚłļŗż.
3. ņ¢┤ņäĀ ĒÜĪļÅÖņÜö ņŗ£Ļ│äņŚ┤ ņśłņĖĪ ņŗ£ļ«¼ļĀłņØ┤ņģś
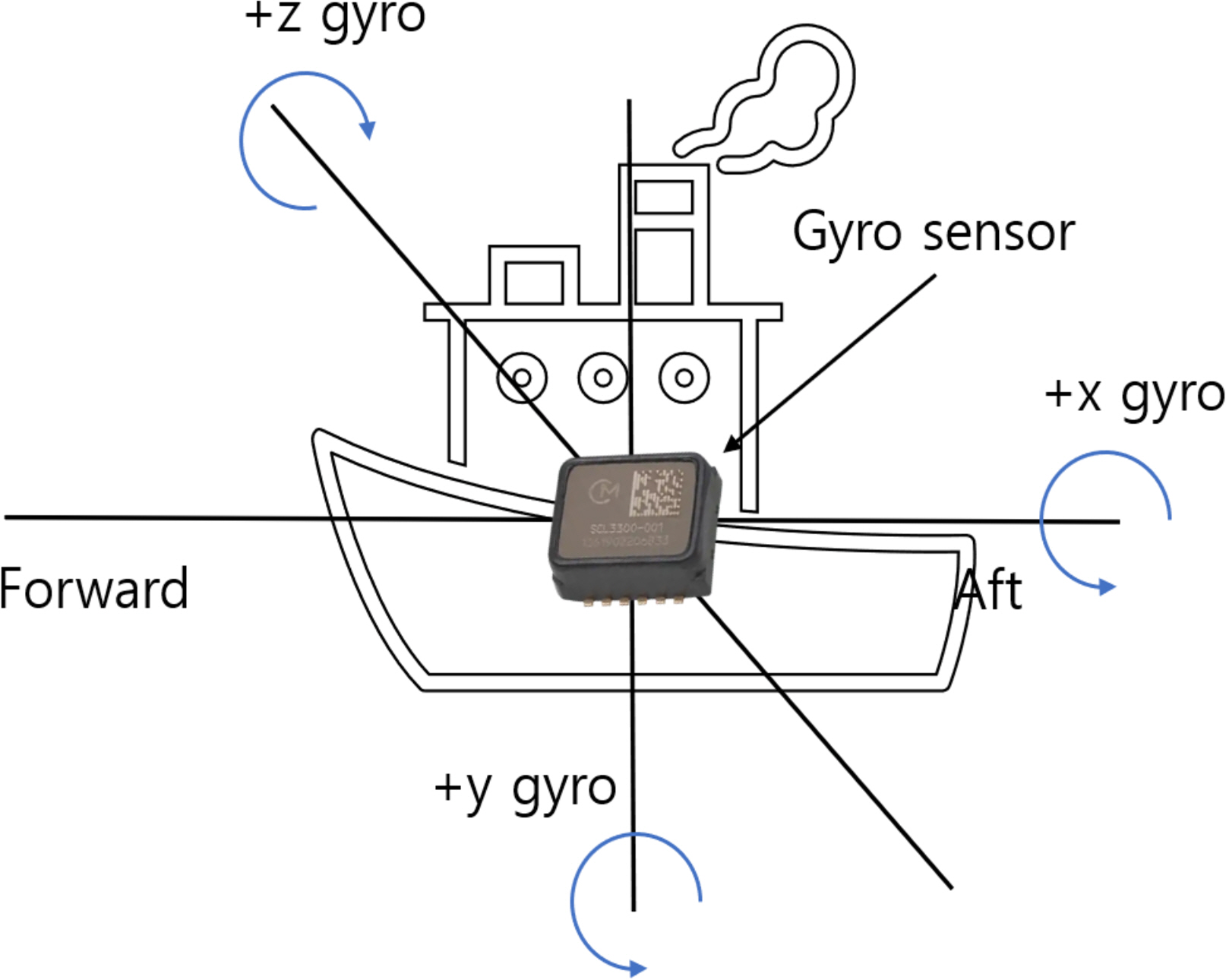
3.1. ļŹ░ņØ┤Ēä░ ņłśņ¦æ
ņŗżĒŚś ļŹ░ņØ┤Ēä░ ņłśņ¦æņØĆ Fig. 10Ļ│╝ Ļ░ÖņØ┤ ņäĀļ░ĢņØś ņżæņĢÖņŚÉ ņ×ÉņØ┤ļĪ£ ņä╝ņä£ļź╝ ņäżņ╣śĒĢśņŚ¼ ņłśņ¦æĒĢśņśĆļŗż. 20HzļĪ£ ņ×æļÅÖĒĢśļŖö ņ×ÉņØ┤ļĪ£ ņä╝ņä£ļŖö ņäĀņłśļ»Ė ļ░®Ē¢źņØś ĒÜĪļÅÖņÜö Ļ░üļÅäļź╝ ņłśņ¦æĒĢ£ļŗż. ņ┤Ø ņłśņ¦æ ņŗ£Ļ░äņØĆ 49ļČä 59ņ┤łņØ┤ļ®░ ņäĀļ░ĢņØś ņĀ£ņøÉņØĆ Table 1Ļ│╝ Ļ░Öļŗż. ņäĀļ░ĢņØś ĻĖĖņØ┤ļŖö 21.5 ļ»ĖĒä░, ĒÅŁ 3.9 ļ»ĖĒä░, Ļ╣ŖņØ┤ 0.75 ļ»ĖĒä░ņØ┤ļŗż. ņ┤Ø ļ░░ņłśļ¤ēņØĆ 23.467 ĒåżņØ┤ļ®░ ļööņĀż ņŚöņ¦äņØ┤ ņäżņ╣śļÉśņ¢┤ ņ׳ļŗż.
3.2. ļŹ░ņØ┤Ēä░ ņĀäņ▓śļ”¼
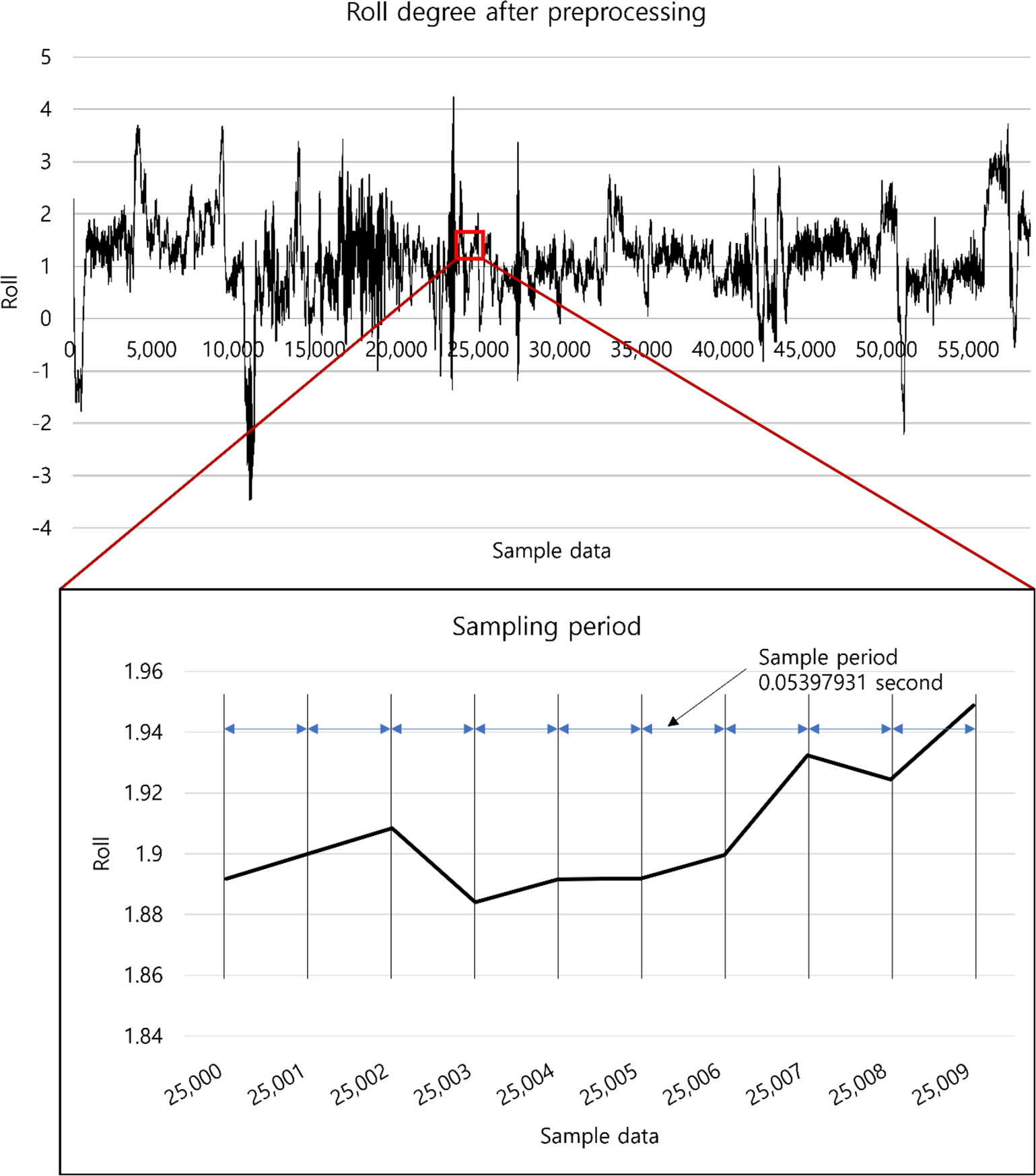
Fig. 11Ļ│╝ Ļ░ÖņØĆ ņł£ņä£ļĪ£ ļŹ░ņØ┤Ēä░ņØś ņĀäņ▓śļ”¼ļź╝ ņŗżņŗ£ĒĢśņśĆļŗż. ļ©╝ņĀĆ ļŹ░ņØ┤Ēä░ļź╝ ņŗ£Ļ░ä ņł£ņä£ļīĆļĪ£ ņĀĢļĀ¼ĒĢ£ļŗż. ņØ┤Ēøä ņżæļ│ĄļÉ£ Ē¢ēņØä ņĀ£Ļ▒░ĒĢśĻ│Ā ņżæļ│ĄļÉ£ ņŗ£Ļ░ä Ļ░ÆņŚÉņä£ ņä£ļĪ£ ļŗżļźĖ ļŹ░ņØ┤Ēä░Ļ░Ć ņ׳ņØä Ļ▓ĮņÜ░ ĒĢ┤ļŗ╣ Ļ░ÆņØä ņĀ£Ļ▒░ĒĢ£ļŗż. ļ¬©ļōĀ Ļ░ÆņØś ņŗ£Ļ░ä Ļ░äĻ▓®ņØä ļÅÖņØ╝ĒĢśĻ▓ī ļ¦īļōżĻĖ░ ņ£äĒĢ┤ ļ”¼ņāśĒöīļ¦üņØä ņłśĒ¢ēĒĢśĻ│Ā, Ļ░äĻ▓®ņØ┤ ņØ╝Ļ┤ĆļÉśĻ▓ī ļéśļłäņ¢┤ņĪīļŖöņ¦Ć ĒÖĢņØĖĒĢ£ļŗż. ļŹ░ņØ┤Ēä░ņØś ņĄ£ļīĆĻ░Æ, ņĄ£ņåīĻ░Æ, Ļ▓░ņĖĪņ╣ś, ņØ┤ņāüņ╣śļź╝ ĒÖĢņØĖĒĢśņśĆļŗż. Fig. 12ļŖö ņĀäņ▓śļ”¼ Ēøä ņ¢┤ņäĀņØś ĒÜĪļÅÖņÜö Ļ░üļÅäļź╝ ļéśĒāĆļéĖļŗż. ņāśĒöī ņŻ╝ĻĖ░ļŖö 0.05397931ņØ┤ļ®░ ņĄ£ļīĆ 4.4ļÅäņØś ĒÜĪļÅÖņÜö Ļ░üļÅäĻ░Ć ĻĖ░ļĪØļÉśņŚłļŗż.
3.3. ļŹ░ņØ┤Ēä░ ņĀĢĻĘ£ĒÖö
ļŹ░ņØ┤Ēä░Ļ░Ć Ļ░Ćņ¦ä ĒŖ╣ņ¦ĢņØś ļ▓öņ£äĻ░Ć Ēü¼Ļ▓ī ņ░©ņØ┤Ļ░Ć ļéĀ Ļ▓ĮņÜ░, ĒĢÖņŖĄņŚÉ Ēü░ ņśüĒ¢źņØä ļ»Ėņ╣Ā ņłś ņ׳ļŗż. ļö░ļØ╝ņä£ ļŹ░ņØ┤Ēä░ ļ▓öņ£äņØś ņ░©ņØ┤ļź╝ ņÖ£Ļ│ĪĒĢśņ¦Ć ņĢŖļÅäļĪØ Ļ│ĄĒåĄ ņ▓ÖļÅäļĪ£ ļ│ĆĻ▓ĮĒĢśļŖö Ļ▓āņØ┤ ĒĢäņÜöĒĢśļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö Ēæ£ņżĆņĀĢĻĘ£ļČäĒżņØś ņåŹņä▒ņØä Ļ░Ćņ¦ĆļÅäļĪØ ĒŖ╣ņ¦ĢņØä ņ×¼ņĪ░ņĀĢĒĢśņśĆļŗż. ņŗØ (1)ņŚÉ ņØśĒĢ┤ ņ×ģļĀź ļ│Ćņłśļź╝ ņāłļĪ£ņÜ┤ Ļ░Æ zļĪ£ Ļ│äņé░ĒĢ£ļŗż. ņŚ¼ĻĖ░ņä£ ╬╝ļŖö ĒÅēĻĘĀ, ŽāļŖö Ēæ£ņżĆĒÄĖņ░©ļź╝ ņØśļ»ĖĒĢ£ļŗż.
3.4. ļ¬©ļŹĖļ¦ü ļ░Å ĒøłļĀ©
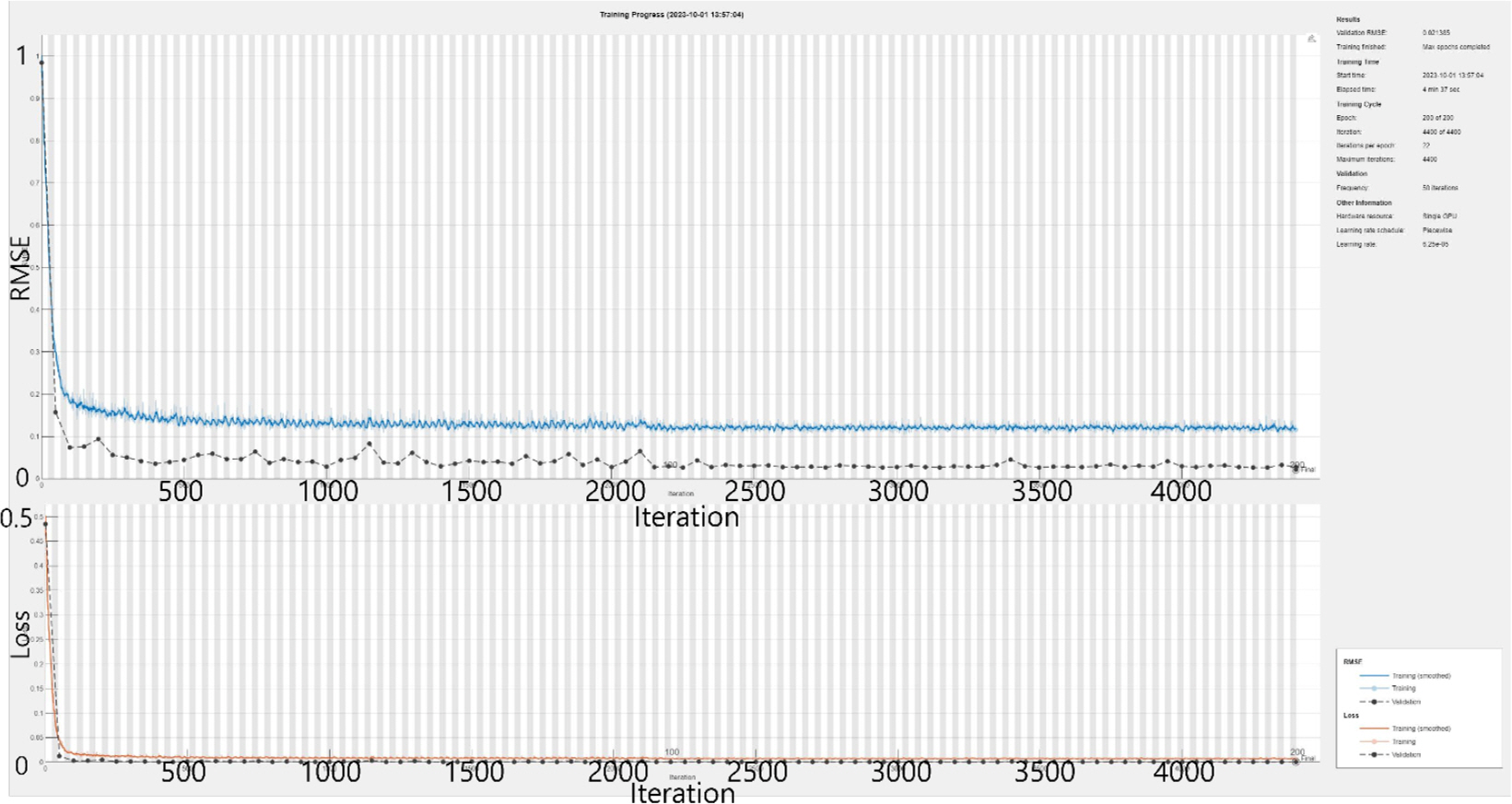
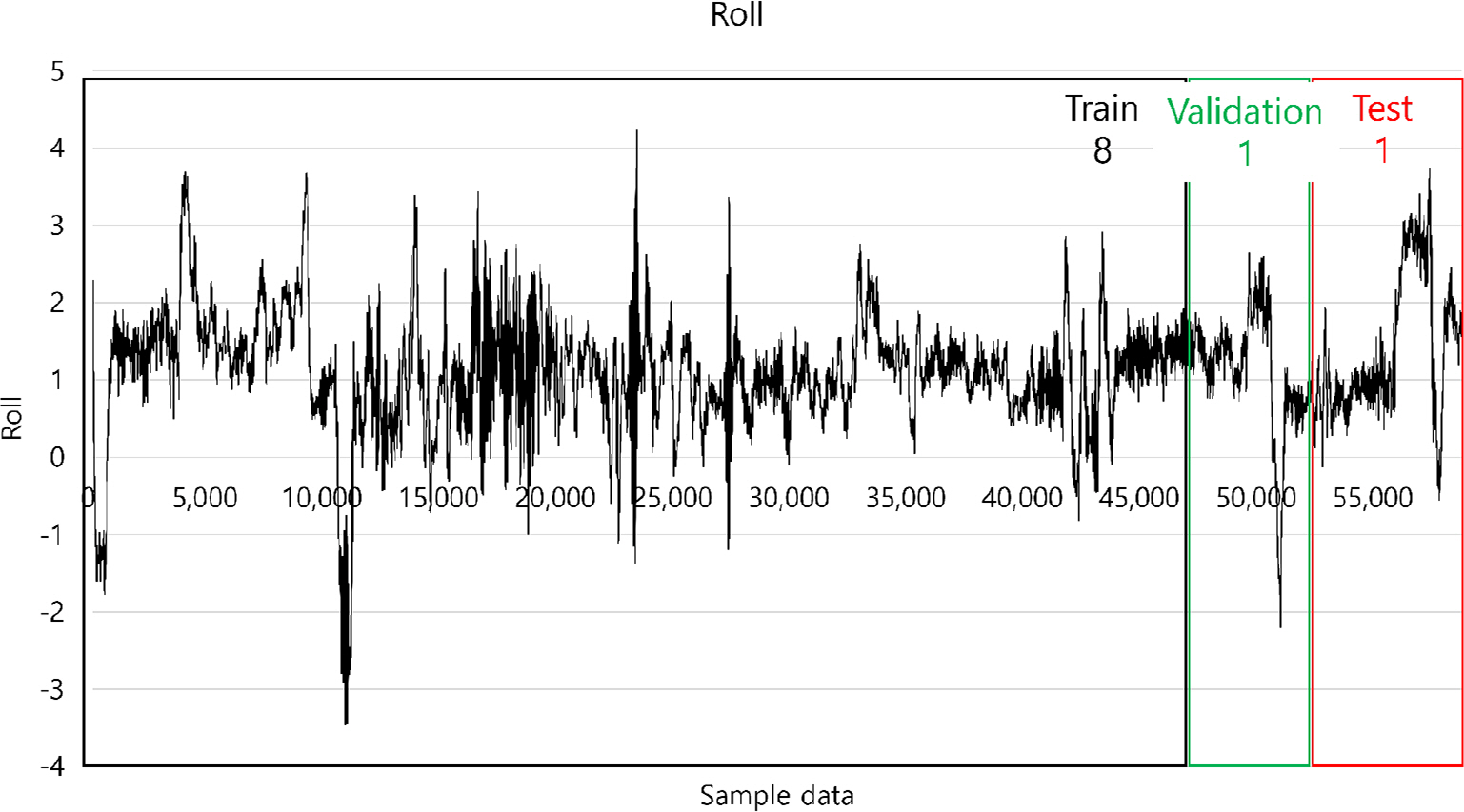
Table 2ņŚÉļŖö Ļ░ü ļ¬©ļŹĖņØś ĻĄ¼ņä▒ņØ┤ ļéśņÖĆ ņ׳ļŗż. ļŹ░ņØ┤Ēä░ņģŗņØĆ Fig. 14ņÖĆ Ļ░ÖņØ┤ ĒøłļĀ©, Ļ▓Ćņ”Ø, ĒģīņŖżĒŖĖļĪ£ 8:1:1ņØś ļ╣äņ£©ļĪ£ ļéśļłäņ¢┤ ņé¼ņÜ®ļÉśņŚłļŗż. ĒøłļĀ©ņŚÉļŖö ņ┤Ø 200ĒÜīņØś epochļź╝ ņŗżĒ¢ēĒĢśņśĆņ£╝ļ®░ ņ┤łĻĖ░ Learning rateļŖö 0.001ļĪ£ ņäżņĀĢĒĢśņśĆļŗż. Ļ▓Ćņ”ØņØĆ 50ĒÜīļ¦łļŗż ņłśĒ¢ēļÉśļÅäļĪØ ĒĢśņśĆņ£╝ļ®░ solverļŖö adamņ£╝ļĪ£ ņäżņĀĢļÉśņŚłļŗż. Gradient ThresholdļŖö ĻĖ░ņÜĖĻĖ░ ņ×äĻ│äĻ░ÆņØä ņØśļ»ĖĒĢ£ļŗż. ĻĖ░ņÜĖĻĖ░ņØś Ēü¼ĻĖ░Ļ░Ć ĻĖēĻ▓®Ē׳ ņ”ØĻ░ĆĒĢśļŖö Ļ▓ĮņÜ░, ĒøłļĀ©ņØś ņĢłņĀĢņä▒ņØ┤ ļ¢©ņ¢┤ņ¦äļŗż. ņØ┤ļź╝ ĻĖ░ņÜĖĻĖ░ ĒÅŁņŻ╝ļØ╝ ļČĆļź┤ļ®░ ņØ┤ļ¤¼ĒĢ£ Ļ▓ĮņÜ░, ĻĖ░ņÜĖĻĖ░ ņĀ£ĒĢ£ņØä ņé¼ņÜ®ĒĢ£ļŗż. Initial Learning RateļŖö ņ┤łĻĖ░ ĒĢÖņŖĄļźĀņØä ņØśļ»ĖĒĢ£ļŗż. ĒĢÖņŖĄļźĀņØ┤ ļäłļ¼┤ ļé«ņ£╝ļ®┤ ĒøłļĀ© ņŗ£Ļ░äņØ┤ ņśżļל Ļ▒Ėļ”┤ ņłś ņ׳ņ£╝ļ®░ ĒĢÖņŖĄļźĀņØ┤ ļäłļ¼┤ ļåÆņ£╝ļ®┤ ļ░£ņé░ĒĢĀ ņłś ņ׳ļŗż. Validation FrequencyļŖö Ļ▓Ćņ”Ø ļ╣łļÅäļź╝ ņØśļ»ĖĒĢśļ®░ ņäżņĀĢļÉ£ Ļ░Æ ļŗ©ņ£äļĪ£ ņŗĀĻ▓Įļ¦ØņØä ĒÅēĻ░ĆĒĢ£ļŗż. SolverļŖö RMSpropņÖĆ MomentumņØś ņןņĀÉņØä Ļ▓░ĒĢ®ĒĢ£ adamņØä ņØ┤ņÜ®ĒĢśņśĆļŗż. XceptionņØĆ ņ┤Ø 177Ļ░£ņØś ļĀłņØ┤ņ¢┤ļĪ£, ĒĢÖņŖĄ Ļ░ĆļŖźĒĢ£ ĒīīļØ╝ļ»ĖĒä░ņØś ņłśļŖö 2,170ļ¦īĻ░£ņØ┤ļŗż. ResNet50ņØĆ 284Ļ░£ņØś ļĀłņØ┤ņ¢┤ļĪ£, ĒĢÖņŖĄ Ļ░ĆļŖźĒĢ£ ĒīīļØ╝ļ»ĖĒä░ņØś ņłśļŖö 2,440ļ¦īĻ░£ņØ┤ļŗż. CRNNņØĆ 22Ļ░£ņØś ļĀłņØ┤ņ¢┤ļź╝ Ļ░Ćņ¦Ćļ®░, ĒĢÖņŖĄ Ļ░ĆļŖźĒĢ£ ĒīīļØ╝ļ»ĖĒä░ņØś ņłśļŖö 24ļ¦ī 3ņ▓£3ļ░▒Ļ░£ņØ┤ļŗż. Fig. 13ņØĆ Xception ļ¬©ļŹĖņØś ĒøłļĀ© Ļ│╝ņĀĢņØä ņØśļ»ĖĒĢ£ļŗż. Ļ░ĆļĪ£ņČĢņØ┤ ļ░śļ│Ą Ēܤņłś, ņäĖļĪ£ ņČĢņØ┤ Ļ░üĻ░ü RMSE, Lossļź╝ ņØśļ»ĖĒĢ£ļŗż. ņŗżĒŚśņØ┤ ņ¦äĒ¢ēļÉĀņłśļĪØ RMSEņÖĆ LossĻ░Ć ļé«ņĢäņ¦ĆļŖö Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆļŗż.
3.5. ņä▒ļŖźĒÅēĻ░Ćņ¦ĆĒæ£
ņä▒ļŖźĒÅēĻ░Ćņ¦ĆĒæ£ļŖö sMAPE(Symmetric Mean Absolute Percentage Error), RMSE(Root Mean Squared Error)ļź╝ ņé¼ņÜ®ĒĢśņśĆļŗż. sMAPEļŖö ņśłņĖĪ Ļ░ÆņØ┤ ņŗżņĀ£ Ļ░Æļ│┤ļŗż ņ×æņØä ļĢīņŚÉļŖö ļČäļ¬©Ļ░Ć ļŹö ņ×æņĢäņ¦ĆĻĖ░ ļĢīļ¼ĖņŚÉ ņśżņ░©Ļ░Ć ņ╗żņ¦ĆļŖö ĒśäņāüņØ┤ ļ░£ņāØļÉĀ ņłś ņ׳ņ£╝ļéś 0Ōł╝ 200% ņé¼ņØ┤ņØś ĒÖĢļźĀĻ░ÆņØä Ļ░Ćņ¦Ćļ®░ Ļ▓░Ļ│╝ ĒĢ┤ņäØņØ┤ ņÜ®ņØ┤ĒĢśļŗż. RMSEļŖö ĒÅēĻĘĀ ņĀ£Ļ│▒ĻĘ╝ ņśżņ░©ļź╝ ņØśļ»ĖĒĢśļ®░ ņśłņĖĪ ļ¬©ļŹĖņŚÉņä£ ņśłņĖĪĒĢ£ Ļ░ÆĻ│╝ ņŗżņĀ£ Ļ░Æ ņé¼ņØ┤ņØś ĒÅēĻĘĀ ņ░©ņØ┤ļź╝ ņØśļ»ĖĒĢ£ļŗż. Ļ░üĻ░üņØä ĻĄ¼ĒĢśļŖö ņŗØ (2), ņŗØ (3)Ļ│╝ Ļ░Öļŗż. ņŚ¼ĻĖ░ņä£ Yi, yiļŖö ņŗżņĀ£Ļ░ÆņØä, Y i ^ y i ^
ņŗżĒŚś Ļ▓░Ļ│╝ ļ╣äĻĄÉļź╝ ņ£äĒĢ┤ ARIMA ļ¬©ĒśĢĻ│╝ ļ╣äĻĄÉĒĢśņśĆļŗż. ļ©╝ņĀĆ ņŗ£Ļ│äņŚ┤ņØ┤ ņĀĢņāüņä▒ņØä Ļ░Ćņ¦ĆļŖöņ¦Ć ĒÖĢņØĖ Ēøä ņ×ÉĻĖ░ņāüĻ┤ĆĒĢ©ņłś(ACF, Autocorrelation Function), ĒÄĖņ×ÉĻĖ░ņāüĻ┤ĆĒĢ©ņłś(PACF, Partial Autocorrelation Function)ņØä ņØ┤ņÜ®ĒĢśņŚ¼ ļŗ©ņ£äĻĘ╝ ņŚ¼ļČĆļź╝ ĒÖĢņØĖĒĢśņśĆļŗż. ņØ┤Ēøä ADF(Augmented Dickey-Fuller Test)ļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ 2ņ░© ņ░©ļČäĒĢ£ ļŹ░ņØ┤Ēä░ņŚÉ ļŗ©ņ£äĻĘ╝ņØ┤ ņ׳ļŖöņ¦Ć ĒÖĢņØĖĒĢśņśĆļŗż.
ņŗØ (4)ļŖö Ļ│äņé░ Ļ▓░Ļ│╝ņØ┤ļŗż. ĻĘĆļ¼┤ Ļ░Ćņäż Ļ▓Ćņ”ØņØä ņŗżņŗ£ĒĢśņśĆņ£╝ļ®░ Table 3Ļ│╝ Ļ░ÖņØ┤ P-valueļŖö 0.001 ņØ┤ĒĢśņ×äņØä ĒÖĢņØĖĒĢśņśĆļŗż.
Table 4ļŖö ņŗżĒŚśņŚÉ ņé¼ņÜ®ļÉ£ ĒĢśļō£ņø©ņ¢┤ņÖĆ ņåīĒöäĒŖĖņø©ņ¢┤ļź╝ ņØśļ»ĖĒĢ£ļŗż. ņŗżĒŚśņŚÉ ņé¼ņÜ®ļÉ£ ĒģīņŖżĒŖĖ ļŹ░ņØ┤Ēä░ļŖö ņ┤Ø 5,827Ļ░£ņØ┤ļ®░ ņ┤Ø 4Ļ░£ņØś ļ¬©ļŹĖņŚÉ ņé¼ņÜ®ļÉśņŚłļŗż. Fig. 14ņÖĆ Ļ░ÖņØ┤ 8:1:1ļĪ£ ļéśļłäņ¢┤ņ¦ä ĒģīņŖżĒŖĖ ļŹ░ņØ┤Ēä░ļź╝ ĒÖ£ņÜ®ĒĢśņśĆļŗż.
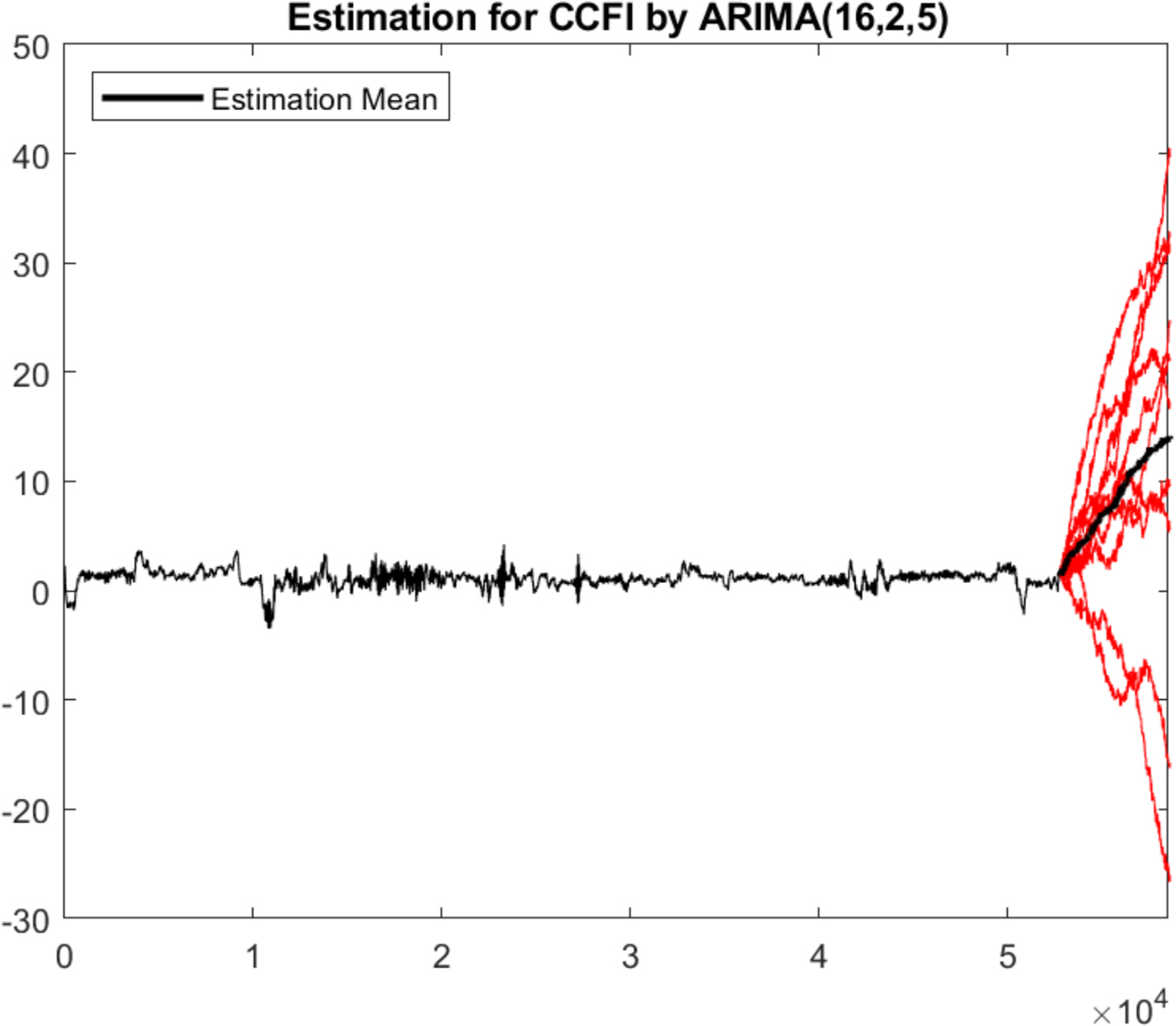
Fig. 15ņØś ļ╣©Ļ░äņāē ņŗżņäĀņØĆ ARIMA ļ¬©ļŹĖņØä 10ĒÜī ļ░śļ│Ą ņŗżĒŚśņØä, Ļ▓ĆņĀĢņāē ņŗżņäĀņØĆ ĒÅēĻĘĀ ņśłņĖĪĻ░ÆņØä ņØśļ»ĖĒĢ£ļŗż. ņśłņĖĪĻ░ÆņØ┤ ņĀÉņĀÉ ņ”ØĻ░ĆĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆļŗż.
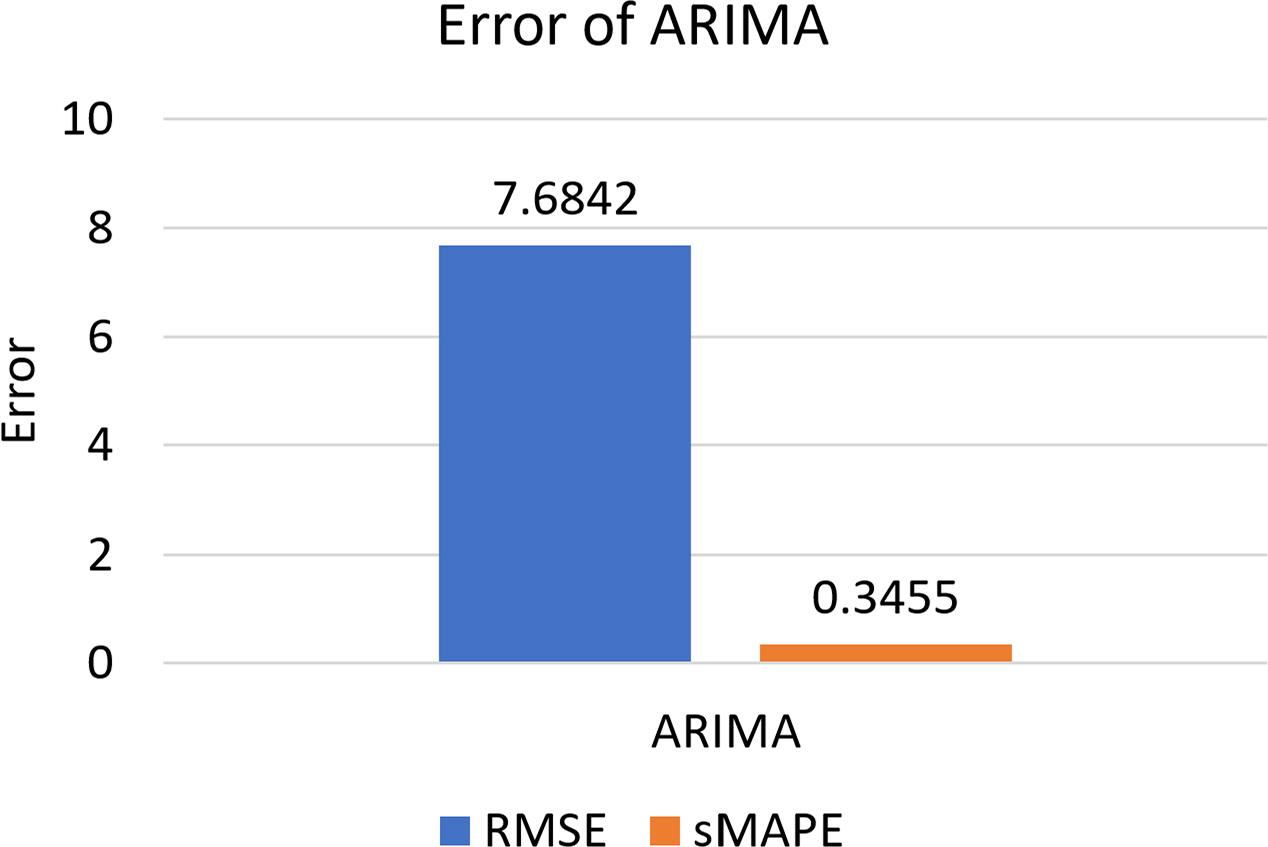
Fig. 16ņØĆ ARIMA ļ¬©ļŹĖņØś RMSEņÖĆ sMAPEļź╝ ņØśļ»ĖĒĢ£ļŗż. RMSEļŖö 7.6842, sMAPEļŖö 0.3455ļź╝ ĻĖ░ļĪØĒĢśņśĆļŗż.
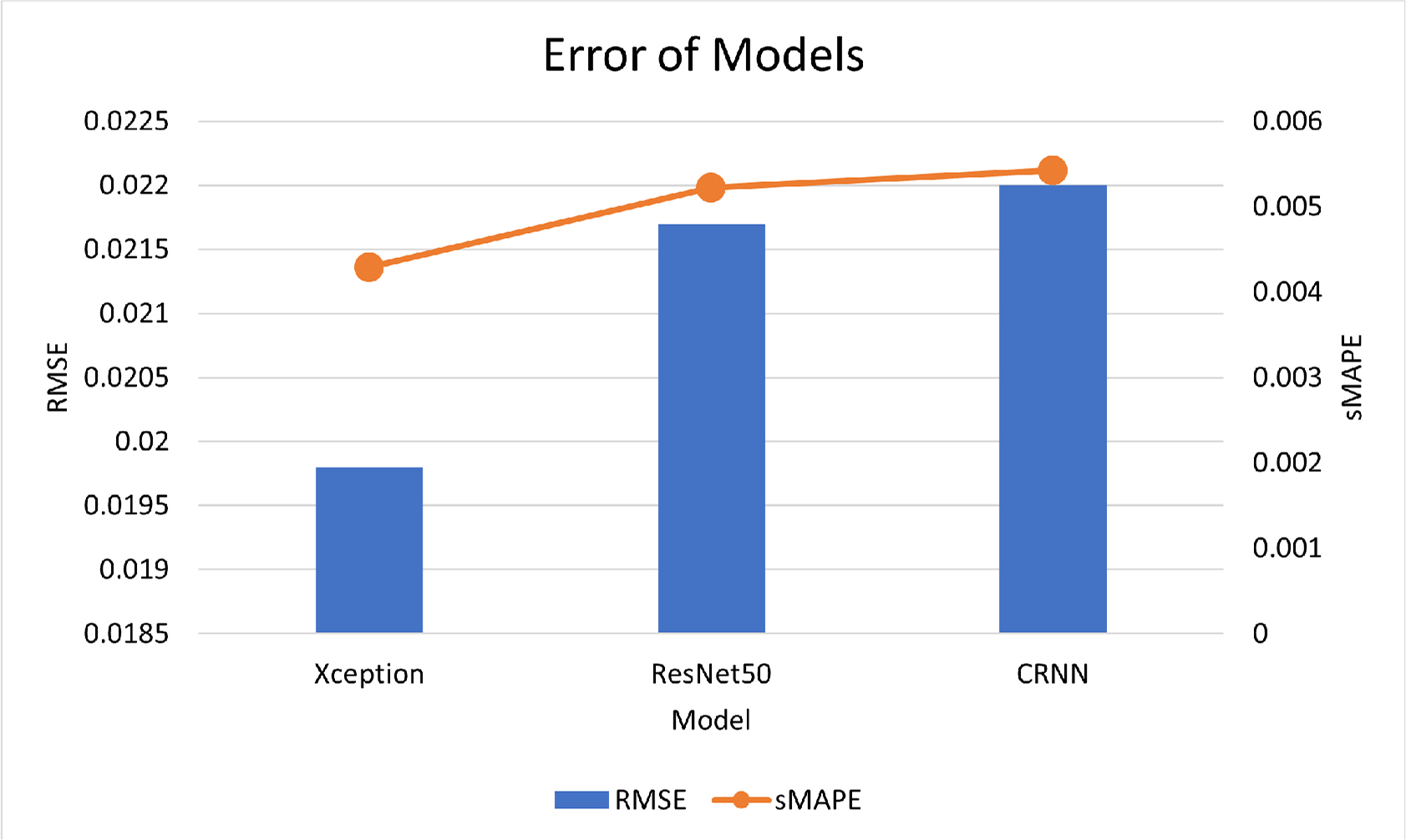
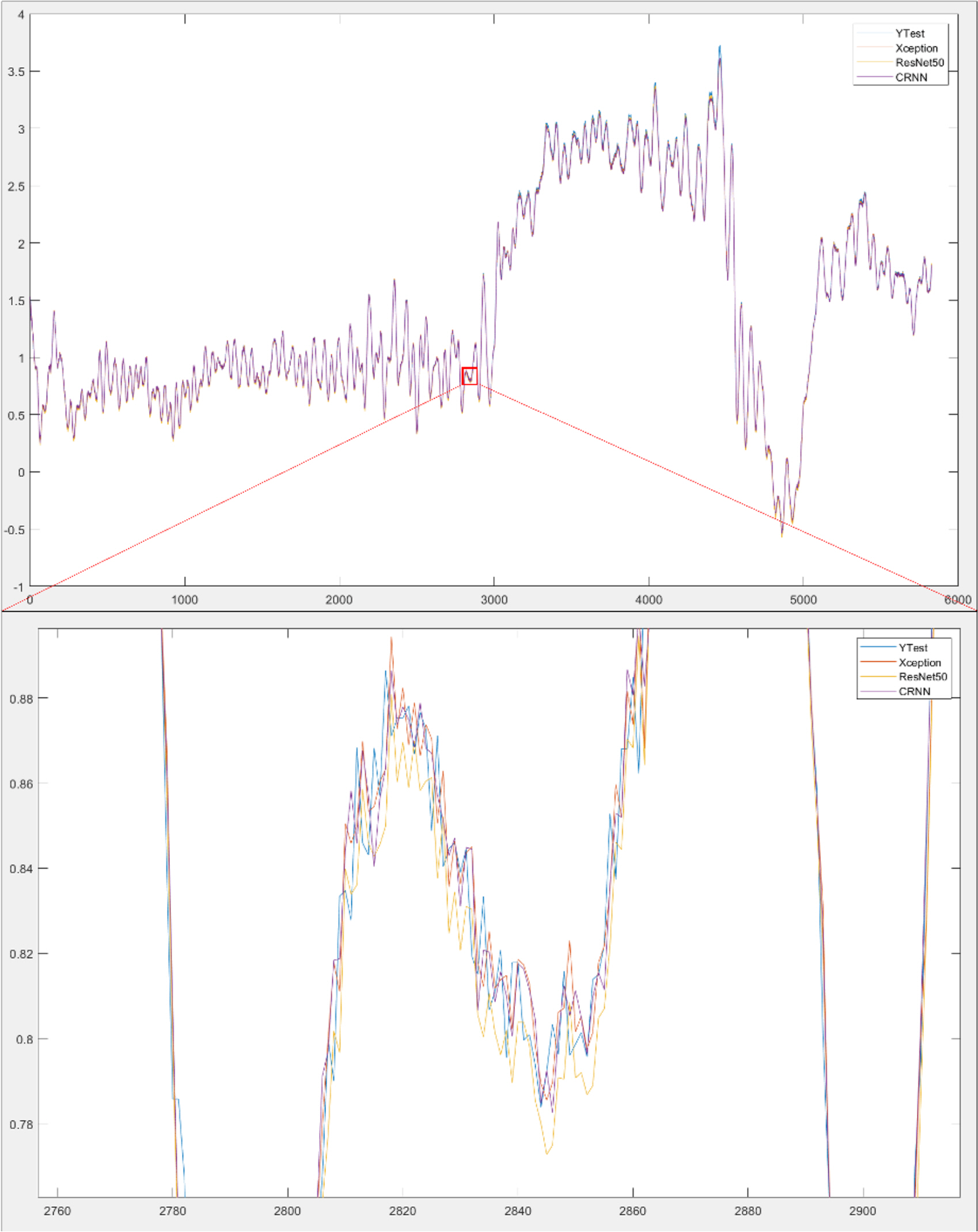
Fig. 17ņØĆ Ļ░ü ļ¬©ļŹĖļ│ä sMAPEņÖĆ RMSEļź╝ ļ│┤ņŚ¼ņżĆļŗż. XceptionņØ┤ Ļ░Ćņן ļé«ņØĆ sMAPEņØĖ 0.0042905ļź╝ ĻĖ░ļĪØĒĢśņśĆņ£╝ļ®░ CRNNņØ┤ 0.0054233ņØś sMAPEļź╝ ĻĖ░ļĪØĒĢśņśĆļŗż. Fig. 18ņØĆ ARIMA ļ¬©ļŹĖņØä ņĀ£ņÖĖĒĢ£ ņŗżņĀ£Ļ░ÆĻ│╝ ļ¬©ļŹĖļōżņØś ņśłņĖĪĻ░ÆņØä ņØśļ»ĖĒĢ£ļŗż. ĒÖĢļīĆĒĢśņśĆņØä Ļ▓ĮņÜ░, Ļ░ü ļ¬©ļŹĖļ│ä ņśłņĖĪĻ░ÆņØ┤ ņāüņØ┤ĒĢ©ņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŗż.
4. Ļ▓░ ļĪĀ
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņ¢┤ņäĀņØś ņŗ£Ļ│äņŚ┤ ĒÜĪļÅÖņÜö ļŹ░ņØ┤Ēä░ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ĒÜĪļÅÖņÜö Ļ░üļÅäļź╝ ņśłņĖĪĒĢśĻĖ░ ņ£äĒĢ┤ ņŗ¼ņĖĄ ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØä ņĀ£ņĢłĒĢśņśĆļŗż. ņØ┤ļź╝ ņ£äĒĢ┤ Xception, ResNet50, CRNNņØś ņØ┤ļ»Ėņ¦Ć ĻĖ░ļ░ś ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØä ĒÖ£ņÜ®ĒĢśņśĆļŗż. ļ│Ė ņŚ░ĻĄ¼ņØś Ļ▓░Ļ│╝ļź╝ ņÜöņĢĮĒĢśļ®┤ ļŗżņØīĻ│╝ Ļ░Öļŗż.
1. ņØ┤ļ»Ėņ¦Ć ĻĖ░ļ░ś ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØä ņŗ£Ļ│äņŚ┤ ļ¬©ļŹĖņŚÉ ņĀüņÜ®ĒĢśņśĆļŗż. ņØ┤ļź╝ ņ£äĒĢ┤ ņ×ģļĀź ļŹ░ņØ┤Ēä░ņŚÉ ņØ┤ļ»Ėņ¦Ć ļŹ░ņØ┤Ēä░Ļ░Ć ņĢäļŗī ņŗ£Ļ│äņŚ┤ ļŹ░ņØ┤Ēä░ļź╝ ņ×ģļĀźĒĢśņśĆļŗż.
2. ņŗ£Ļ│äņŚ┤ ļŹ░ņØ┤Ēä░ņØś ņןĻĖ░Ļ░ä ņśłņĖĪņŗ£ ĻĘĖļĀłļööņ¢ĖĒŖĖ ņåīņŗż ļ¼ĖņĀ£Ļ░Ć ļ░£ņāØĒĢśļŖöļŹ░ ResNet50ņØś ņ×öņ░© ļĖöļĪØņØä ņé¼ņÜ®ĒĢśņŚ¼ ņØ┤ļ¤¼ĒĢ£ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśņśĆļŗż.
3. ņŗżĒŚś Ļ▓░Ļ│╝ņŚÉņä£ Xception ļöźļ¤¼ļŗØ ļ¬©ļŹĖņØ┤ Ļ░Ćņן ļé«ņØĆ ņśżņ░©ļź╝ ĻĖ░ļĪØĒĢśņśĆņ£╝ļ®░ ResNet50, CRNNņØ┤ ļÆżļź╝ ņØ┤ņŚłļŗż.
4. XceptionņÖĆ ResNet50ņØś Ļ▓ĮņÜ░, CRNNņŚÉ ļ╣äĒĢ┤ ĒīīļØ╝ļ®öĒä░ņØś ņłśĻ░Ć ļ¦żņÜ░ ļ¦ÄņĢśņ£╝ļ®░ ļö░ļØ╝ņä£ ĒĢÖņŖĄ ņŗ£Ļ░äņŚÉņä£ļÅä ņ░©ņØ┤Ļ░Ć ļ░£ņāØĒĢśņśĆļŗż.
ņČöĒøä ņŚ░ĻĄ¼ Ļ│╝ņĀ£ļĪ£ ņĄ£ņĀüņØś ĒĢśņØ┤ĒŹ╝ ĒīīļØ╝ļ®öĒä░ņØś ņäżņĀĢņØ┤ ĒĢäņÜöĒĢśļŗż. ļśÉĒĢ£ ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ļŗ©ņØ╝ņØś ņŗ£Ļ│äņŚ┤ ļŹ░ņØ┤Ēä░ļ¦īņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ņ¢┤ņäĀņØś ĒÜĪļÅÖņÜö Ļ░üļÅäļź╝ ņśłņĖĪĒĢśņśĆņ£╝ļéś ĒĢ┤ņāü ņāüĒā£, ĒÆŹĒ¢ź, ĒÆŹņåŹ ļō▒ņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ļŹöņÜ▒ ņĀĢļ░ĆĒĢ£ ņśłņĖĪņØ┤ ĒĢäņÜöĒĢĀ Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ĒĢ£ļŗż.





 PDF Links
PDF Links PubReader
PubReader ePub Link
ePub Link Full text via DOI
Full text via DOI Download Citation
Download Citation Print
Print