1. ýäťŰíá
ÝĽşŰžîýŁÇ ýäáŰ░ĽýŁś ýÂťý×ů, ýŐ╣ŕ░ŁýŁś ýŐ╣┬ĚÝĽśýäá, ÝÖöŰČ╝ýŁś ÝĽśýŚş Ű░Ć Ű│┤ŕ┤Çý▓śŰŽČ Űô▒ýŁä ýťäÝĽť ýőťýäĄŰôĄýŁ┤ ŕ░ľýÂöýľ┤ýžä ŕ││ýŁä ýŁśŰ»ŞÝĽťŰőĄ. ýŁ┤ŰčČÝĽť ÝĽşŰžîýŁÇ ýÖŞÝĽşýäáýŁ┤ ýú╝Űíť ý×ůýݼşÝĽśŰŐö ŰČ┤ýŚşÝĽşŕ│╝ ŕÁşŰé┤ ýÜ┤ÝĽş ýäáŰ░ĽýŁ┤ ýŁ┤ýÜęÝĽśŰŐö ýŚ░ýĽłÝĽşýť╝Űíť ŕÁČŰÂäŰÉśŰę░, ŕÁşŰé┤ýŚÉŰŐö 31ŕ░ťýŁś ŰČ┤ýŚşÝĽşŕ│╝ 29ŕ░ťýŁś ýŚ░ýĽłÝĽşýŁ┤ ýÜ┤ýśüŰÉśŕ│á ý׳ŰőĄ(Ministry of Ocean and Fisheries, 2023). ýŁ┤ý▓śŰč╝ ÝĽşŰžîýŁÇ Ýä░Ű»ŞŰäÉ, ŰÂÇŰĹÉ, ýáĽŰ░ĽýžÇ Űô▒ýŁś ÝĽşŰžî ýőťýäĄýŁä ýéČýÜęÝĽśŕŞ░ ýťäÝĽť ýäáŰ░ĽŰôĄŰíť ýŁŞÝĽ┤ ŰžĄýÜ░ Ű│Áý×íÝĽť ŕÁÉÝćÁ ÝîĘÝä┤ýŁä ŕ░ÇýžÇŕ│á ý׳ýť╝Űę░, ýäáŰ░ĽýŁś ýÜ┤ÝĽş Ű░ÇýžĹŰĆä ŰśÉÝĽť Űćĺŕ▓î ŰéśÝâÇŰéśŰŐö ŕ▓âýŁ┤ ýŁ╝Ű░śýáüýŁ┤ŰőĄ. ýŁ┤ýŚÉ ÝĽşŰé┤ ýäáŰ░Ľ ŕÁÉÝćÁýŁä Ű│┤ŰőĄ ýĽłýáäÝĽśŕ│á ÝÜĘýťĘýáüýť╝Űíť ŕ┤ÇŰŽČÝĽśŕŞ░ ýťäÝĽ┤ ÝĽ┤ýâüŕÁÉÝćÁŕ┤Çýáťýä╝Ýä░(VTS, vessel traffic services)Űą╝ ýäĄý╣śÝĽśýŚČ ýÜ┤ýśüÝĽśŕ│á ý׳ýť╝Űę░, AIS, RADAR, VHF Űô▒ýŁä ýŁ┤ýÜęÝĽśýŚČ ŕ┤Çýáť ŕÁČýŚşýŚÉýäť ýÜ┤ÝĽş ýĄĹýŁŞ ýäáŰ░ĽýŁä ýőĄýőťŕ░ä ۬ĘŰőłÝä░ŰžüÝĽśŕ│á ý׳ŰőĄ(Korea Coast Guard, 2023). ŕĚŞŰčČŰéś ŕÁÉÝćÁŰčëýŁ┤ ŰžÄýĽäýžÇŰŐö Ýś╝ý×íýőťŕ░äŰîÇýŁś ŕ▓ŻýÜ░ ŕ┤ÇýáťýéČýŁś ýŚůŰČ┤ ŰíťŰôťŕ░Ç ýŽŁŕ░ÇÝĽśýŚČ ýáüýőťýŚÉ ŕ┤Çýáť ýáĽŰ│┤ŕ░Ç ýáťŕ│ÁŰÉśýžÇ ۬╗ÝĽśŰŐö ŕ┤Çýáť ŕ│ÁŰ░▒ýŁ┤ ýâŁŕŞ░ŕŞ░ŰĆä ÝĽťŰőĄ. ýŁ┤ŰčČÝĽť ýŁ┤ýťáýŚÉýäť Ýś╝ý×íýŁä ýśłýŞíÝĽśýŚČ ŕÁÉÝćÁ ýâüÝÖęýŁä ÝćÁýáťÝĽśŕ▒░Űéś, ŕ┤Çýáť ý×ÉýŤÉýŁä ýÂöŕ░ÇŰíť Ű░░ýáĽÝĽśýŚČ ýŤÉÝ֝ݼť ŕ┤Çýáťŕ░Ç ýŁ┤ŰúĘýľ┤ýžÇŰĆäŰíŁ ýí░ý╣śÝĽśŕ▓î ŰÉťŰőĄ. ŕĚŞŰčČŰéś ÝĽşŰé┤ ŕÁÉÝćÁ ýâüÝÖęýŁÇ ŰőĄýľĹÝĽť Ű│Çýłśŕ░Ç ýí┤ý×ČÝĽśŕŞ░ ŰĽîŰČŞýŚÉ ŕÁÉÝćÁ Ýś╝ý×í ýâüÝÖęýŁä ýáĽÝÖĽÝĽśŕ▓î ýśłýŞíÝĽśŕŞ░ŰŐö ŰžĄýÜ░ ýľ┤ŰáĄýÜ┤ ýŁ╝ýŁ┤Űę░, Ýśäý×ČŰŐö ŕ┤ÇýáťýéČýŁś ŕ┤Çýáť ŕ▓ŻÝŚśýŁä Ű░öÝâĽýť╝Űíť ÝîÉŰőĘŰÉśŕ│á ý׳ŰŐö ýőĄýáĽýŁ┤ŰőĄ. ýŁ┤ýŚÉ Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ÝÜĘýťĘýáüýŁŞ ÝĽşŰžî ŕÁÉÝćÁ ŕ┤ÇŰŽČŰą╝ ýťäÝĽ┤ ŕÁÉÝćÁ Ýś╝ý×íŰĆä Ű░Ć Ýś╝ý×í ŕÁČýŚşýŁä ýśłýŞíÝĽśŰŐö Ű░ęŰ▓ĽýŁä ýáťýĽłÝĽśŰę░, ýőĄÝĽ┤ýŚş ŰŹ░ýŁ┤Ýä░Űą╝ ýáüýÜęÝĽť ýőĄÝŚśýŁä ÝćÁÝĽ┤ ýáťýĽłŰÉť Ű░ęŰ▓ĽýŁ┤ ŕ┤Çýáť ýžÇýŤÉ ŰĆäŕÁČŰíť ÝÖťýÜęŰÉá ýłś ý׳ŰŐöýžÇ ŕ│áý░░ÝĽśŕ│áý×É ÝĽťŰőĄ.
2. ýäáÝľë ýŚ░ŕÁČ ŰÂäýäŁ
ŕ│Áŕ░ä ŰŹ░ýŁ┤Ýä░ýŁś ŰÂäÝĆČ Ű░Ć Ű░ÇýžĹŰĆäŰą╝ ŰÂäýäŁÝĽśŰŐö Ű░ęŰ▓Ľ ýĄĹ ŕ░Çý׹ ŕŞ░Ű│ŞýáüýŁŞ ŕŞ░Ű▓ĽýŁÇ Ý׳ÝŐŞŰžÁ(heatmap)ýŁ┤ŰőĄ. Ý׳ÝŐŞŰžÁýŁÇ ŕ│Áŕ░ä ŰŹ░ýŁ┤Ýä░ýŁś ŰÂäÝĆČŰą╝ ýžÇŰĆäýťäýŚÉ ýĄĹý▓ęÝĽśýŚČ ÝĹťýőťÝĽśŰŐö ŕ│Áŕ░äýáĽŰ│┤ ŰÂäýäŁ Ű░ęŰ▓Ľýť╝Űíť ŰŹ░ýŁ┤Ýä░ýŁś Ű░ÇýžĹ ýáĽŰĆäýŚÉ Űö░ŰŁ╝ ýŚ┤ýžÇŰĆä ÝśĽÝâťŰíť Ű│┤ýŚČýú╝ŰŐö ŕ▓âýŁ┤ ÝŐ╣ýžĽýŁ┤ŰőĄ. ýŁ┤ŰčČÝĽť Ý׳ÝŐŞŰžÁ ŰÂäýäŁýŁä ÝćÁÝĽ┤ ŰîÇýâü ÝĽ┤ýŚşýŚÉýäťýŁś ýäáŰ░Ľ Ű░ÇýžĹ ýśüýŚşýŁä ŕ▒░ýőťýáüýť╝Űíť ÝîîýĽůÝĽá ýłś ý׳ýžÇŰžî, ýäŞŰ░ÇÝĽť ŕÁÉÝćÁ ŰÂäýäŁýŁÇ ýľ┤ŰáĄýÜ┤ ŰČŞýáťýáÉýŁ┤ ý׳ŰőĄ(Kim et, al., 2018).
ÝĽşŰžîýŁś ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×í ŰÂäýäŁýŚÉ ŕ┤ÇÝĽť ýŚ░ŕÁČŰŐö ýú╝Űíť ýäáŰ░Ľ ýÜ┤ÝĽşý×ÉýŁś ŕ┤ÇýáÉýŚÉýäť ýłśÝľëŰÉśýŚłŰőĄ. Park et, al.(2014)ýŁÇ ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ ŕŞ░Ű░śýť╝Űíť ŕÁÉÝćÁŰčëýŁä ýÂöýáĽÝĽť ÝŤä, ŰîÇýâü ÝĽşŰíťýŁś ýäáŰ░Ľ ýłśýÜę ýÜęŰčëýŁä Ű╣äŕÁÉÝĽśýŚČ ýÁťýóůýáüýŁŞ ŕÁÉÝćÁ Ýś╝ý×íŰĆäŰą╝ ŕ│äýé░ÝĽśŰŐö Ű░ęŰ▓ĽýŁä ýáťýĽłÝĽśýśÇýť╝Űę░, ýŁ┤ŰŐö Ýśäý×Č ŰîÇŰÂÇŰÂäýŁś ÝĽ┤ýâüŕÁÉÝćÁýĽłýáäýžäŰőĘýŚÉ ýáüýÜęŰÉśŕ│á ý׳ŰőĄ. ýŁ┤ŰĽî, ŕÁÉÝćÁŰčëýŁÇ ŕŞ░Ű│Şýáüýť╝Űíť ÝĽ┤ýâü ýâüÝâť, ÝĽ┤ýâüŕÁÉÝćÁŕ┤ÇŰŽČ Ű░ęýőŁ Űô▒ýŁä ŕ│áŰáĄÝĽśýŚČ ŕ▓░ýáĽÝĽśŰę░, ýĽłýáä ýÜ┤ÝĽşýŁä ýťäÝĽť ýśüýŚşýŁä ýáĽýŁśÝĽśŕ│á ýäáŰ░Ľ ýÜ┤ÝĽşý×ÉýŁś ŕ┤ÇýáÉýŚÉýäť ýŁ┤Űą╝ ýťáýžÇÝĽśýŚČ ýÜ┤ÝĽşÝĽśŰŐö ýí░ŕ▒┤ýť╝Űíť ŕÁÉÝćÁŰčëýŁä ýé░ýݼśŕŞ░ŰĆä ÝĽťŰőĄ(Um et, al., 2012). ŕÁÉÝćÁ Ýś╝ý×í ÝśäÝÖęýŁä ÝîîýĽůÝĽśŕŞ░ ýťäÝĽ┤ ýäáŰ░ĽýŁś ÝćÁÝĽş ŰÂäÝĆČ ýáĽŰ│┤Űą╝ ýéČýÜęÝĽśŕŞ░ŰĆä ÝĽťŰőĄ(Kim et. al., 2011). Ý׳ÝŐŞŰžÁ Űô▒ýť╝Űíť ŰÂäýäŁÝĽśŕ│áý×É ÝĽśŰŐö ÝĽ┤ýŚşýŁś ýäáŰ░Ľ ŕÁÉÝćÁ Ű░ÇýžĹŰĆäŰą╝ ÝîîýĽůÝĽť ÝŤä, ÝŐ╣ýἠýťäý╣śýŚÉ ÝâÉýâëýäá(gateline)ýŁä ýäĄý╣śÝĽśýŚČ ýäáŰ░ĽýŁś ÝćÁÝĽş ÝÖĽŰąá ŰÂäÝĆČŰą╝ ýÂöýáĽÝĽťŰőĄ. ýŁ┤ŰčČÝĽť Ű░ęŰ▓ĽýŁÇ IALAýŁś ÝĽ┤ýâüŕÁÉÝćÁ ýĽłýáäýä▒ ÝĆëŕ░Ç ýćîÝöäÝŐŞýŤĘýľ┤ýŁŞ IWRAPýŚÉýäť ÝÖťýÜęŰÉśŕ│á ý׳ŰŐö Ű░ęŰ▓ĽýŁ┤Űę░, ŰŹöýÜ▒ ýäŞŰ░ÇÝĽśŕ▓î ŕÁÉÝćÁ Ýś╝ý×íýŁä ŰÂäýäŁÝĽá ýłś ý׳ŰŐö ý׹ýáÉýŁ┤ ý׳ýžÇŰžî, ÝćÁÝĽş ŕ▓ŻŰíťŕ░Ç Ű│Áý×íÝĽť ŕ▓ŻýÜ░ ý×ĹýŚů ýőťŕ░äýŁ┤ ŰžÄýŁ┤ ÝĽäýÜöÝĽť ŰőĘýáÉýŁ┤ ý׳ŰőĄ(GateHouse, 2018). ŰśÉÝĽť, ŕÁÉÝćÁŰąś ýőťŰ«ČŰáłýŁ┤ýůś ŕŞ░Ű▓ĽýŁä ýŁ┤ýÜęÝĽśýŚČ ŕÁÉÝćÁ Ýś╝ý×íŰĆäŰą╝ ýśłýŞíÝĽśŰŐö Ű░ęŰ▓ĽýŁ┤ ýáťýĽłŰÉśŕŞ░ŰĆä ÝĽśýśÇŰőĄ(Park, 2022). ŕÁÉÝćÁŰąś ýőťŰ«ČŰáłýŁ┤ýůśýŁÇ ýäáŰ░ĽýŁś ýݜä Ű╣łŰĆä, ýäáŰ░ĽýŁś ýáťýŤÉ, ýÜ┤ÝĽş ŕ▓ŻŰíť Űô▒ýŁä ýőĄýáť ýÜ┤ÝĽş ÝÖśŕ▓Żŕ│╝ ýťáýéČÝĽśŕ▓î ýäĄýáĽÝĽśŕ│á ýäáŰ░Ľ ŕÁÉÝćÁŰąśŰą╝ ý×ČÝśäÝĽśŰŐö ŕŞ░Ű▓ĽýŁ┤Űę░, ýőťŰ«ČŰáłýŁ┤ýůśýŁś ý×ůŰáą ÝîîŰŁ╝Ű»ŞÝä░Űą╝ ýí░ýáłÝĽśýŚČ Ű»ŞŰלýŁś Ýś╝ý×íŰĆä ýśłýŞíýŁ┤ ŕ░ÇŰչݼśýžÇŰžî, ýőĄýäŞŕ│äýŁś ŕÁÉÝćÁ ÝśäýâüýŁä ý×ČÝśäÝĽśŰŐöŰŹ░ ÝĽťŕ│äŕ░Ç ýí┤ý×ČÝĽťŰőĄ.
ÝĽťÝÄŞ, ÝĽşŰžî ýÜ┤ýśüŕ┤ÇŰŽČ ŕ┤ÇýáÉýŚÉýäť Ýś╝ý×íŰĆäŰą╝ ÝĆëŕ░ÇÝĽśŰŐö Ű░ęŰ▓ĽýŁ┤ ýáťýĽłŰÉśŕŞ░ŰĆä ÝľłŰőĄ(Peng et. al., 2022). ÝÖöŰČ╝ýäáýŁ┤ ŰžÄýŁ┤ ÝćÁÝĽşÝĽśŰŐö ý╗ĘÝůîýŁ┤Űäł Ýä░Ű»ŞŰäÉýŁś Ýś╝ý×íŰĆäŰą╝ ýŞíýáĽÝĽśŰŐö Ű░ęŰ▓Ľýť╝Űíť ŕÁÉÝćÁŰčëŕ│╝ ÝĽşŰžî ýŁ┤ýÜę ýőťŕ░ä ýáĽŰ│┤(turnaround time)Űą╝ ýŁ┤ýÜęÝĽśýŚČ Ýś╝ý×íŰĆäŰą╝ ŰÂäýäŁÝĽśŕ│á ýśłýŞíÝĽťŰőĄ. ŕĚŞŰčČŰéś ýŁ┤ŰčČÝĽť Ű░ęŰ▓ĽýŁÇ ÝĽşŰžî ýőťýäĄýŚÉ ŰîÇÝĽť Ýś╝ý×íŰĆäŰą╝ ŰÂäýäŁÝĽśŰŐö ŰŹ░ŰŐö ÝÜĘŕ│╝ýáüýŁ╝ ýłś ý׳ýžÇŰžî, ŰőĄýľĹÝĽť ýäáýóůýŁ┤ ýÜ┤ÝĽşÝĽśŰŐö ÝĽşŰžîýŁś ŕ▓ŻýÜ░ ŕĚŞ ÝŐ╣ýä▒ýŁä ۬ĘŰĹÉ Ű░śýśüÝĽá ýłś ýŚćŕ▓î ŰÉťŰőĄ.
ýŁ┤ý▓śŰč╝ ŰîÇŰÂÇŰÂäýŁś ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×íŰĆäýŚÉ ŕ┤ÇÝĽť ýŚ░ŕÁČŰôĄýŁÇ ýäáŰ░Ľ ýÜ┤ÝĽşý×ÉýŁś ŕ┤ÇýáÉýŚÉýäť ŕÁÉÝćÁ Ýś╝ý×íŰĆäŰą╝ ýáĽýŁśÝĽśŕ│á ý׳ŰőĄ. ýŽë, ýäáŰ░Ľ ŕÁÉÝćÁŰčëýŁ┤ ýŽŁŕ░ÇÝĽśŰę┤, ÝĽ┤Űő╣ ÝĽ┤ýŚşýŚÉýäťýŁś ýäáŰ░Ľ Ű░ÇýžĹŰĆäŕ░Ç ýŽŁŕ░ÇÝĽśŕ│á, ýŁ┤ýŚÉ Űö░ŰŁ╝ ŕÁÉÝćÁ Ýś╝ý×íŰĆäŕ░Ç ýŽŁŕ░ÇÝĽśŕ▓î ŰÉťŰőĄ. ŕĚŞŰčČŰéś ŕ┤ÇýáťŕÁČýŚş ýáäý▓┤Űą╝ ۬ĘŰőłÝä░Űžü ÝĽ┤ýĽ╝ ÝĽśŰŐö ÝĽ┤ýâüŕÁÉÝćÁŕ┤ÇýáťýŁś ŕ┤ÇýáÉýŚÉýäťŰŐö ŕÁÉÝćÁ Ű░ÇýžĹýŚÉ Űö░ŰąŞ Ýś╝ý×íŰĆäŰ┐ÉŰžî ýĽäŰőłŰŁ╝, ŕ┤Çýáť ŕÁÉýőá ÝÜčýłśŕ░Ç ýŽŁŕ░ÇÝĽśŰŐö ŕÁÉÝćÁ Ýś╝ý×í ýâüÝÖęýŚÉ ŰîÇÝĽť ŕ│áŰáĄŰĆä ÝĽäýÜöÝĽśŰőĄ.
3. ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×í ýśłýŞí
3.1 ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×í ýáĽýŁś
ÝĽ┤ýâüŕÁÉÝćÁŕ┤Çýáť ŕ┤ÇýáÉýŚÉýäťýŁś ŕÁÉÝćÁ Ýś╝ý×í ýâüÝÖęýŁÇ ŰőĘýłťÝ׳ ŕÁÉÝćÁŰčëýŁ┤ ŰžÄýŁÇ ýâüÝÖęýŁ┤ ýĽäŰőłŰŁ╝ ŕ┤Çýáť ŕ░ťý×ůýŁś ýŚČýžÇŕ░Ç ŰžÄýŁÇ ýâüÝÖęýŁä ýŁśŰ»ŞÝĽťŰőĄ. Fig. 1ýŁś (a)ýŚÉýäťýÖÇ ŕ░ÖýŁ┤, ýäáŰ░Ľ Ű░ÇýžĹŰĆäŰŐö ŰćĺýžÇŰžî, ÝĽşŰíť Űé┤ýŚÉýäť ýäáŰ░ĽýŁ┤ ýŤÉÝ֝ݼśŕ▓î ýÜ┤ÝĽşÝĽśŰŐö ŕ▓ŻýÜ░ ŕ┤Çýáť ŕ░ťý×ůýŁ┤ ÝĽäýÜöÝĽśýžÇ ýĽŐŰőĄ. Ű░śŰę┤ýŚÉ Fig. 1ýŁś (b)ŰŐö ŰĹÉ ŕ░ťýŁś ÝĽşŰíťŕ░Ç ŕÁÉý░ĘÝĽśŰŐö ýžÇýáÉýŁ┤Űę░, ýŁ┤ýŚÉ Űö░ŰŁ╝ ýäáŰ░ĽýŁ┤ ýí░ýÜ░ ÝĽá ŕ░ÇŰŐąýä▒ýŁ┤ ŰžĄýÜ░ ŰćĺýĽä ŕ┤Çýáť ŕ░ťý×ůýŁ┤ ŰőĄýłś ÝĽäýÜöÝĽť ýâüÝÖęýŁ┤ŰőĄ. ýŁ┤ýŚÉ Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ŕÁÉÝćÁŰčë ŕŞ░Ű░śýŁś ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×íŰĆä ýáĽýŁśýŚÉ ŕ┤Çýáť ŕ░ťý×ůýŁś ýÜöýćîŰą╝ ýÂöŕ░ÇÝĽśýŚČ ŕÁÉÝćÁ Ýś╝ý×íŰĆäŰą╝ ýáĽýŁśÝĽśýśÇŰőĄ. Ýś╝ý×í ýśłýŞíýŁś Ű▓öýťäŰŐö ÝĽşŰžî ýőťýäĄýŁä ÝĆČÝĽĘÝĽśŰŐö ŕ┤Çýáť ŕÁČýŚşýť╝Űíť ÝĽťýáĽÝĽśŕ│á, Ýś╝ý×í ýśłýŞí ŕŞ░ŕ░äýŁÇ ŕ┤Çýáť ýŚůŰČ┤ýŚÉ ýśüÝľąýŁä Ű»Şý╣śŰŐö ÝľąÝŤä 24ýőťŕ░ä ýŁ┤Űé┤Űíť ýáĽÝĽśýśÇýť╝Űę░, ýőťŕ░äýŚÉ Űö░ŰąŞ ýśłýŞíŰ┐ÉŰžî ýĽäŰőłŰŁ╝ ŕ│Áŕ░äýáüýŁŞ ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×í ýśłýŞíýŁä ÝĆČÝĽĘÝĽśýśÇŰőĄ.
3.2 ýäáŰ░Ľ ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ Ű¬ĘŰŹŞŰžü
ÝĽ┤ýâüŕÁÉÝćÁŕ┤Çýáť ŕ┤ÇýáÉýŚÉýäť ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×íýŁä ýśłýŞíÝĽśŰáĄŰę┤ ŰîÇýâü ÝĽ┤ýŚşýŚÉýäťýŁś ýäáŰ░Ľ ýÜ┤ÝĽş ÝŐ╣ýä▒ýŁä ÝîîýĽůÝĽ┤ýĽ╝ ÝĽśŰę░, ýŁ┤Űą╝ ýťäÝĽ┤ýäťŰŐö ýäáŰ░ĽýŁś ýÜ┤ÝĽş ŕ▓ŻŰíť ýáĽŰ│┤Űą╝ ýÂöýݼ┤ýĽ╝ ÝĽťŰőĄ.
ÝĽ┤ýľĹýłśýé░ŰÂÇýŚÉýäťŰŐö ÝĽşŰé┤Űą╝ ýÜ┤ÝĽşÝĽśŰŐö ýäáŰ░ĽýŁÇ ýáĽÝĽ┤ýžä ÝĽşŰíťŰą╝ Űö░ŰŁ╝ ÝĽşÝľëÝĽśŰĆäŰíŁ ŕĚťýáĽÝĽśŕ│á ý׳ŰőĄ(Ministry of Ocean and Fisheries, 2023). ŕĚŞŰčČŰéś ÝĽ┤Űő╣ ŕĚťýáĽýŚÉŰŐö ýú╝ýÜö ÝĽşŰíťýŚÉ ŰîÇÝĽ┤ýäťŰžî ýÜ┤ÝĽş Ű░ęÝľą, ýÜ┤ÝĽş ýćŹŰĆä, ŕ░ÇÝĽş ýśüýŚş Űô▒ýŁä ýžÇýáĽÝĽśŕ│á ý׳ýľ┤ýäť ŕĚŞ ýÖŞýŁś ýśüýŚşýŚÉýäťŰŐö ýäáŰ░ĽýŁś ýÜ┤ÝĽş ÝîĘÝä┤ýŁä ýśłýŞíÝĽśŕŞ░ ýľ┤ŰáĄýÜ┤ ŰČŞýáťýáÉýŁ┤ ý׳ŰőĄ. ýŁ┤ýŚÉ Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ýäáŰ░ĽýŁś ŕ│╝ŕ▒░ ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ Ű░öÝâĽýť╝Űíť ýäáŰ░ĽýŁś ýú╝ýÜö ýÜ┤ÝĽş ŕ▓ŻŰíť ýáĽŰ│┤Űą╝ ýÂöýݼśýśÇŰőĄ.
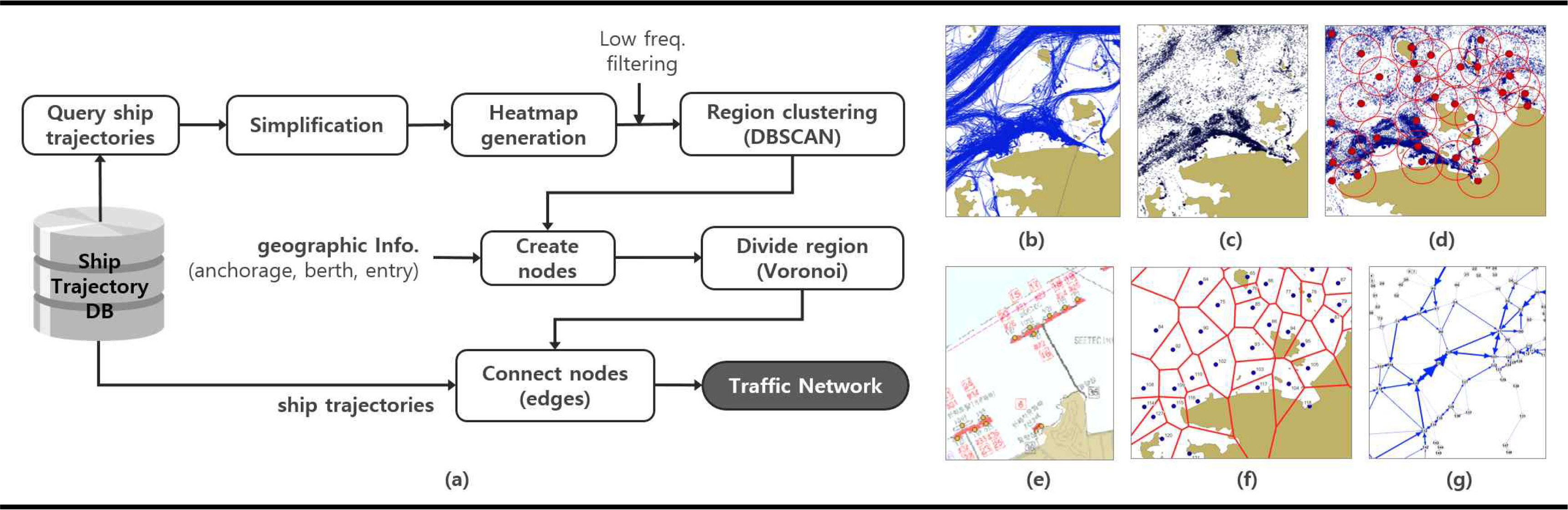
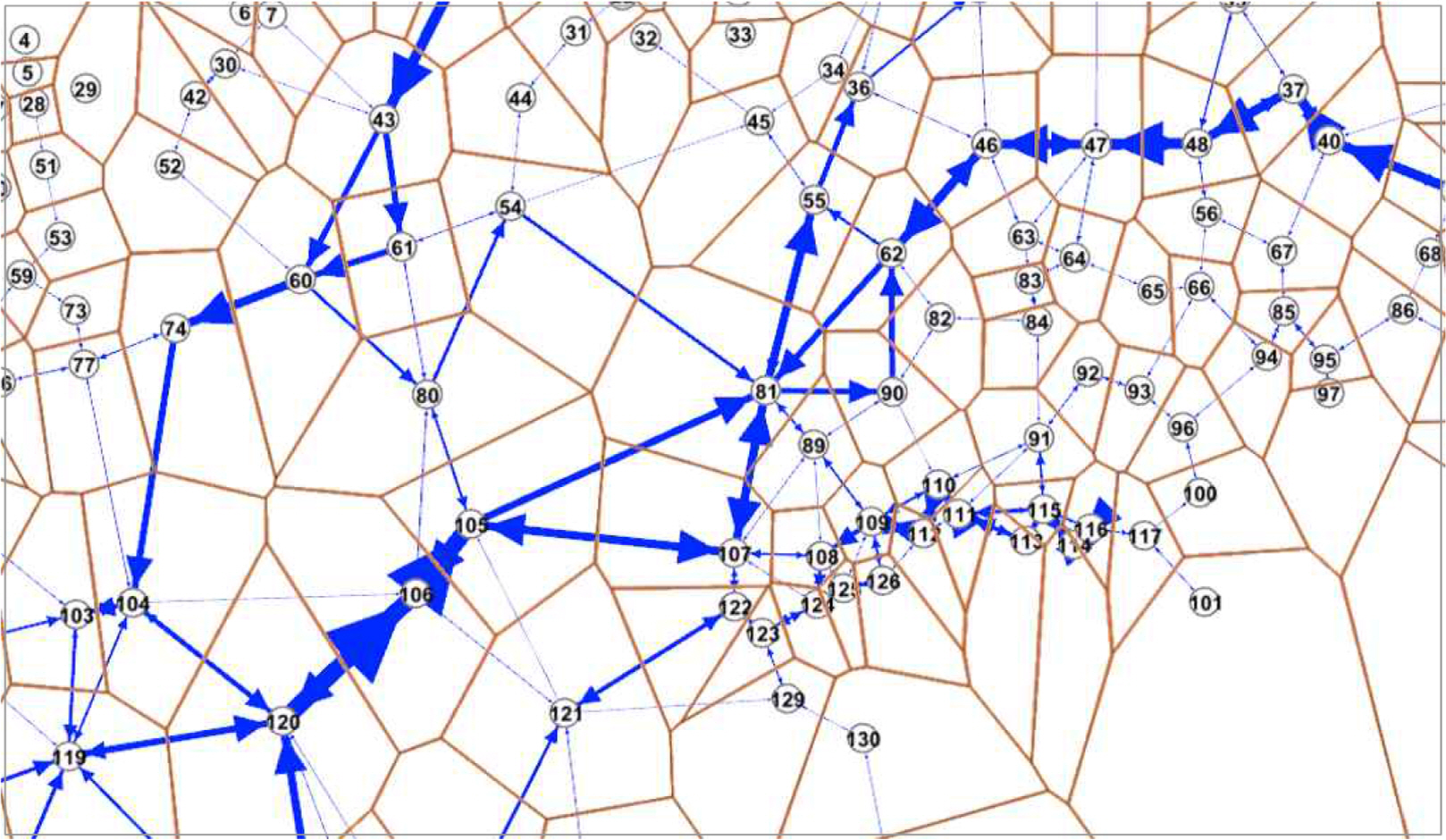
ýäáŰ░ĽýŁś ýÜ┤ÝĽş ŕ▓ŻŰíť ýáĽŰ│┤ŰŐö ŰůŞŰôťýÖÇ Ű░ęÝľąýä▒ýŁä ŕ░ÇýžÇŰŐö ýŚÉýžÇŰíť ŕÁČýä▒ŰÉť ŰäĄÝŐŞýŤîÝüČ ŕĚŞŰלÝöä ÝśĽÝâťŰíť ŰéśÝâÇŰé╝ ýłś ý׳ýť╝Űę░, ýÂťŰ░ťýžÇ, ۬ęýáüýžÇ, ýÜ┤ÝĽş ŕ▓ŻŰíť, ýÜ┤ÝĽş Ű╣łŰĆä Űô▒ýŁś ÝĽ┤ýâü ŕÁÉÝćÁ ÝŐ╣ýä▒ýŁä ýáĽŰčëýáüýť╝Űíť ÝŝݜäÝĽá ýłś ý׳ŰŐö ÝŐ╣ýžĽýŁ┤ ý׳ŰőĄ. Fig. 2ýŚÉŰŐö ŰîÇýÜęŰčëýŁś ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŰíťŰÂÇÝä░ ýäáŰ░Ľ ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČŰą╝ ýâŁýä▒ÝĽśŕŞ░ ýťäÝĽť ýáłý░ĘŰą╝ ŰĆäýőŁÝÖöÝĽśýśÇŰőĄ. ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ Ű¬ĘŰŹŞŰžü ýáłý░ĘŰŐö ý┤Ł 7ŰőĘŕ│äŰíť ŕÁČýä▒ŰÉśŰę░, ŕ░ü ŰőĘŕ│äŰ│ä ýäŞŰÂÇ Űé┤ýÜęýŁÇ ŰőĄýŁîŕ│╝ ŕ░ÖŰőĄ.
STEP 1 ÝĽşýáü ŰŹ░ýŁ┤Ýä░ ýÂöýÂť
ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŰŐö ŰŹ░ýŁ┤Ýä░Ű▓áýŁ┤ýŐĄýŚÉ ýáÇý׹ŰÉśýľ┤ ý׳ýť╝Űę░, ÝâÉýâë ýśüýŚş, ýőťŕ░ä Ű▓öýťä Űô▒ýŁä ý×ůŰáą ýí░ŕ▒┤ýť╝Űíť ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ ÝâÉýâëÝĽťŰőĄ. ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ ýâŁýä▒ýŁä ýťäÝĽ┤ýäťŰŐö ýÁťýćî 6ŕ░ťýŤö ýŁ┤ýâüýŁś ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŕ░Ç ÝĽäýÜöÝĽśŰę░, ŰîÇýÜęŰčëýŁś ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ ÝÜĘŕ│╝ýáüýť╝Űíť ŕ┤ÇŰŽČÝĽá ýłś ý׳ŰŐö ŰŹ░ýŁ┤Ýä░Ű▓áýŁ┤ýŐĄ ýőťýŐĄÝůťýŁ┤ ÝĽäýłśýáüýŁ┤ŰőĄ. ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŰŐö RADARýÖÇ AISýŁś ÝćÁÝĽę ŰČ╝ÝĹťŰíť ŕÁČýä▒ŰÉśŰę░, ŕ░ü ŰČ╝ÝĹťŰŐö VTS ŰČ╝ÝĹť ÝćÁÝĽę ýőťýŐĄÝůťýŚÉ ýŁśÝĽ┤ ÝćÁÝĽęŰÉśýľ┤ ý׳ŰőĄ. ŕ░ü ŰŹ░ýŁ┤Ýä░ŰŐö ýłśýőá ýőťŕ░üýŚÉ Űö░ŰŁ╝ ýáĽŰáČŰÉśýľ┤ ý׳ýť╝Űę░, ýłśýőá ýŁ╝ýőť, ýťäŰĆä, ŕ▓ŻŰĆä, ýćŹŰĆä, ý╣ĘŰíť, ŰČ╝ÝĹť ID ýáĽŰ│┤Űą╝ ÝĆČÝĽĘÝĽťŰőĄ.
STEP 2 ÝĽşýáü ŰőĘýłťÝÖö
ýÂöýÂťŰÉť ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŰŐö ŰČ╝ÝĹť ID Ű│äŰíť ŰÂäŰąśÝĽť ÝŤä, ýőťŕ░ä ýłťýäťŰíť ýáĽŰáČÝĽśýŚČ ÝĽşýáü ŰőĘýłťÝÖö ŰőĘŕ│äŰą╝ ŕ▒░ý╣ťŰőĄ. ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŰŐö ýäáŰ░Ľ ýÜ┤ÝĽş ŕ▓ŻŰíťýâüýŁś ýŚ░ýćŹŰÉť ýáÉýŁś ÝśĽÝâťŰíť ÝŝݜäÝĽá ýłś ý׳ýť╝Űę░, ýäáŰ░ĽýŁś ýÜ┤ÝĽş ýćŹŰĆäýŚÉ Űö░ŰŁ╝ ŰőĄýľĹÝĽť ýú╝ŕŞ░Űíť ýáÇý׹ŰÉťŰőĄ. ýŁ┤ŰčČÝĽť ÝĽşýáü ŰŹ░ýŁ┤Ýä░ ýĄĹ ý╣ĘŰíťŕ░Ç Ű│Çŕ▓ŻŰÉśŰŐö Ű│Çý╣ĘýáÉ(waypoint) ýáĽŰ│┤ŕ░Ç ýĄĹýÜöÝĽť ýŁśŰ»ŞŰą╝ ŕ░ÇýžÇŰę░, ýŁ┤Űą╝ ÝćÁÝĽ┤ ýäáŰ░ĽýŁś ýÜ┤ÝĽş ŕ▓ŻŰíť ÝŐ╣ýä▒ýŁä ÝîîýĽůÝĽá ýłś ý׳ŕ▓î ŰÉťŰőĄ. ÝĽşýáü ŰőĘýłťÝÖö ŕ│╝ýáĽýŁÇ ýäťŰíť ŰőĄŰąŞ ŰŹ░ýŁ┤Ýä░ýŁś ýőťŕ░ä ŕ░äŕ▓ęýŁä ýŁ╝Ű░śÝÖöÝĽśŰŐö ÝÜĘŕ│╝ŕ░Ç ý׳ýť╝Űę░, ýÜ┤ÝĽş ŕ▓ŻŰíť ÝŐ╣ýžĽýŁÇ ýÁťŰîÇÝĽť ýťáýžÇÝĽśŕ│á ýâüŰîÇýáüýť╝Űíť ýĄĹýÜöŰĆäŕ░Ç Űé«ýŁÇ ÝĆČýŁŞÝŐŞŰą╝ ýáťŕ▒░ÝĽĘýť╝ŰíťýŹĘ ŰŹ░ýŁ┤Ýä░ýŁś ýÜęŰčëýŁä ŰîÇÝĆş ýĄäýŁ╝ ýłś ý׳ŰőĄ. Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ÝĽşýáü ŰőĘýłťÝÖöŰą╝ ýťäÝĽ┤ Ramer-Douglas-Peucker(RDP) ýĽîŕ│áŰŽČýŽśýŁä ýáüýÜęÝĽśýśÇŰőĄ(Ramer et al., 1972). RDP ýĽîŕ│áŰŽČýŽśýŁÇ ŕ│íýäá ÝśĽÝâťýŁś ýŚ░ýćŹýáÉýŁä ýžüýäá ÝśĽÝâťŰíť ŰőĘýłťÝÖöÝĽśŰŐö ýĽîŕ│áŰŽČýŽśýŁ┤Űę░, ýŁ┤Űą╝ ýŁ┤ýÜęÝĽśýŚČ ýŚ░ýćŹŰÉť ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŰíťŰÂÇÝä░ Ű│Çý╣ĘýáÉ ÝĆČýŁŞÝŐŞŰą╝ ýäáŰ│äÝĽá ýłś ý׳ŰőĄ. Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ý×äŕ│ä ŕ▒░ŰŽČ ŕ░ĺ(¤Á=0.005)ýŁä ýáüýÜęÝĽśýśÇŰőĄ.
STEP 3 ÝĽşýáü ŕÁ░ýžĹÝÖö
ÝĽşýáü ŰőĘýłťÝÖö ŰőĘŕ│äŰą╝ ŕ▒░ý╣ť ŰîÇýÜęŰčëýŁś ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŰŐö Fig. 2 ýŁś (c)ýÖÇ ŕ░ÖýŁ┤ ýäáŰ░ĽýŁś ýÜ┤ÝĽş ŕ▓ŻŰíť ÝŐ╣ýä▒ýŁä ÝĆČÝĽĘÝĽśŰŐö Ű│Çý╣ĘýáÉ ÝĆČýŁŞÝŐŞ ýžĹÝĽęýť╝Űíť ÝŝݜäŰÉá ýłś ý׳ýť╝Űę░, ýŁ┤ŰŐö ýÜ┤ÝĽşÝĽśŰŐö ýäáŰ░ĽýŁś ýú╝ýÜö Ű│Çý╣Ę ýťäý╣śŰą╝ ýŁśŰ»ŞÝĽťŰőĄ. Ű│Çý╣ĘýáÉ ÝĆČýŁŞÝŐŞýŁś ŕÁ░ýžĹÝÖöŰą╝ ýťäÝĽ┤ Ý׳ÝŐŞŰžÁ ýŁ┤Ű»ŞýžÇŰą╝ ýâŁýä▒ÝĽť ÝŤä ýáÇŰ╣łŰĆä ýśüýŚşýŁä ý░żýĽäŰé┤ŕ│á ýŁ┤ ýśüýŚşýŚÉ ÝĆČÝĽĘŰÉśŰŐö ÝĆČýŁŞÝŐŞŰą╝ ýáťŕ▒░ÝĽťŰőĄ. ýŁ┤Űą╝ ÝćÁÝĽ┤ Ű│Çý╣Ę ýśüýŚşýŁ┤ Ű³ݼäýÜöÝĽśŕ▓î ŰžÄýĽäýžÇŰŐö ŕ▓âýŁä Ű░ęýžÇÝĽśŕ│á, ŰŹ░ýŁ┤Ýä░ýŁś ý▓śŰŽČ ýćŹŰĆäŰą╝ ÝľąýâüýőťÝéČ ýłś ý׳ŕ▓î ŰÉťŰőĄ. ŕĚŞ ÝŤä, ÝĽäÝä░Űžü ŰÉť Ű│Çý╣ĘýáÉ ÝĆČýŁŞÝŐŞŰôĄýŁä ŕÁ░ýžĹÝÖöÝĽśýŚČ ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôťýŁś ÝŤäŰ│┤ŕÁ░ýŁä ýÂöýݼśŕ▓î ŰÉśŰŐöŰŹ░, Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ŕÁ░ýžĹÝÖöŰą╝ ýťäÝĽ┤ Ű░ÇŰĆä ŕŞ░Ű░ś ŕÁ░ýžĹÝÖö ýĽîŕ│áŰŽČýŽśýŁŞ DBSCAN(Density-based spatial clustering of applications with noise)ýŁä ýéČýÜęÝĽśýśÇŰőĄ. DBSCAN ýĽîŕ│áŰŽČýŽśýŁÇ ŕÁ░ýžĹ ŕĚŞŰú╣ýŁś ýłśŰą╝ ýáĽÝĽśýžÇ ýĽŐŕ│á ŰŹ░ýŁ┤Ýä░ýŁś Ű░ÇŰĆäýŚÉ Űö░ŰŁ╝ ŕÁ░ýžĹÝÖöŰą╝ ýłśÝľëÝĽśŕŞ░ ŰĽîŰČŞýŚÉ ŕŞ░ÝĽśÝĽÖýáüýŁŞ ۬ĘýľĹýŁś ŕÁ░ýžĹýŚÉŰĆä ýáüýÜęýŁ┤ ŕ░ÇŰչݼśŰőĄŰŐö ý׹ýáÉýŁ┤ ý׳ýť╝Űę░(Ester et al., 1996), ýäŞŰÂÇ ÝîîŰŁ╝Ű»ŞÝä░ŰŐö ¤Á=1, minPts=10ýť╝Űíť ýäĄýáĽÝĽśýśÇŰőĄ.
STEP 4 ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôť ýâŁýä▒
Ű│Çý╣ĘýáÉ ÝĆČýŁŞÝŐŞýŁś ŕÁ░ýžĹÝÖöŰą╝ ÝćÁÝĽ┤ ýÂöýÂťŰÉť ŰůŞŰôť ÝŤäŰ│┤ŕÁ░ŕ│╝ ŰÂÇŰĹÉ, ýáĽŰ░ĽýžÇ, ýÂťý×ůýáÉ Űô▒ ÝĽşŰžîýŁś ýžÇŰŽČ ýáĽŰ│┤Űą╝ ýÂöŕ░ÇÝĽśýŚČ ýÁťýóůýáüýť╝Űíť ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôťŰą╝ ýâŁýä▒ÝĽťŰőĄ. ýŁ┤ŰĽî ýťäý╣śŕ░Ç ýĄĹŰ│ÁŰÉśŰŐö ÝĆČýŁŞÝŐŞŰą╝ ýéşýáťÝĽśŕ▒░Űéś, ýťáýéČÝĽť ýťäý╣śýŁś ŰůŞŰôťŰą╝ Ű│ĹÝĽęÝĽśŰŐö Űô▒ ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôť ýÁťýáüÝÖö ŰőĘŕ│äŰą╝ ŕ▒░ý╣śŕ▓î ŰÉťŰőĄ.
STEP 5 ýśüýŚş ŰÂäÝĽá
Fig. 2ýŁś (f)ýÖÇ ŕ░ÖýŁ┤ ýÁťýóůýáüýť╝Űíť ýâŁýä▒ŰÉť ŰůŞŰôťŰą╝ ŕŞ░ýĄÇýť╝Űíť ŰîÇýâü ÝĽ┤ýŚşýŁä ŰÂäÝĽáÝĽśŰę░, Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö Ű│┤ŰíťŰůŞýŁ┤ ŰőĄýŁ┤ýľ┤ŕĚŞŰ×Ę(voronoi diagram)ýŁä ýáüýÜęÝĽśýśÇŰőĄ. Ű│┤ŰíťŰůŞýŁ┤ ŰőĄýŁ┤ýľ┤ŕĚŞŰ×ĘýŁÇ ŰůŞŰôť ýéČýŁ┤ýŁś ŕ▒░ŰŽČŰą╝ ŕŞ░Ű░śýť╝Űíť ÝĆëŰę┤ýŁä ŰÂäÝĽáÝĽśŰŐö Ű░ęŰ▓Ľýť╝Űíť ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôťŰą╝ ŕŞ░ýĄÇýť╝Űíť ŰÂäÝĽáŰÉť ýśüýŚşýŁÇ ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ ŰÂäŰąśÝĽśŰŐö ŕŞ░ýĄÇýŁ┤ ŰÉťŰőĄ.
STEP 6 ŰäĄÝŐŞýŤîÝüČ ýŚÉýžÇ ýâŁýä▒
ŰäĄÝŐŞýŤîÝüČýŁś ýŚÉýžÇ ýáĽŰ│┤ŰŐö ýŁ┤ýáä ŰőĘŕ│äýŚÉýäť ŰÂäÝĽáŰÉť ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôťýŁś ýśüýŚş ýáĽŰ│┤Űą╝ ýŁ┤ýÜęÝĽśýŚČ ýâŁýä▒ŰÉťŰőĄ. ýäáŰ░ĽŰ│äŰíť ŕÁČŰÂäŰÉť ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ ýőťŕ░ä ýłťýäťŰíť ýáĽŰáČÝĽť ÝŤä, ŰÂäÝĽáŰÉť ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôť ýśüýŚşýŚÉ ÝĽáŰő╣ÝĽśŕ▓î ŰÉśŰę┤, ŰůŞŰôť ýśüýŚş ýőťÝÇÇýŐĄŰíť Ű│ÇÝ֜ݼá ýłś ý׳ŰőĄ. ýŁ┤Űáçŕ▓î Ű│ÇÝÖśŰÉť ŰůŞŰôť ýśüýŚş ýőťÝÇÇýŐĄŰŐö ŰůŞŰôť ýśüýŚş ŕ░ä ýŁ┤ŰĆÖ ýáĽŰ│┤Űą╝ ÝĆČÝĽĘÝĽśŰę░, ýŁ┤Űą╝ ýŁ┤ýÜęÝĽśýŚČ ŰäĄÝŐŞýŤîÝüČ ýŚÉýžÇ ýáĽŰ│┤Űą╝ ýâŁýä▒ÝĽá ýłś ý׳ŰőĄ. STEP 1ýŚÉýäť ýÂöýÂťŰÉť ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ ۬ĘŰĹÉ ýśüýŚş ýőťÝÇÇýŐĄŰíť Ű│ÇÝ֜ݼť ÝŤä, ýŚÉýžÇŰą╝ ýŚ░ŕ▓░ÝĽśŕ│á, ŰůŞŰôť ŕ░ä ýŁ┤ŰĆÖ Ű╣łŰĆäýŚÉ Űö░ŰŁ╝ ýáÇŰ╣łŰĆä ýŚÉýžÇŰą╝ ýáťŕ▒░ÝĽśŰę┤ Fig. 3ŕ│╝ ŕ░ÖýŁÇ ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ Ű¬ĘŰŹŞýŁ┤ ýÖäýä▒ŰÉťŰőĄ. ýâŁýä▒ŰÉť ŰäĄÝŐŞýŤîÝüČ Ű¬ĘŰŹŞýŁś ŕ░ü ŰůŞŰôťŰŐö Ű░ęÝľąýä▒ýŁä ŕ░ÇýžÇŰŐö ýŚÉýžÇŰíť ýŚ░ŕ▓░ŰÉťŰőĄ. ŕ░ü ŰůŞŰôťýŚÉ ýŚ░ŕ▓░ŰÉť ýŚÉýžÇýŁś ŕ░ťýłśŰŐö ýŚ░ŕ▓░ŰĆä(degree)Űíť ÝŝݜäÝĽá ýłś ý׳ýť╝Űę░, ýŁ┤ŰčČÝĽť ýŚ░ŕ▓░ŰĆä ýáĽŰ│┤Űą╝ ýŁ┤ýÜęÝĽśŰę┤ ŕ░ü ŰůŞŰôť ýśüýŚşýŚÉýäťýŁś ýäáŰ░Ľ ŕÁÉÝćÁ ÝŁÉŰŽäýŁś ÝŐ╣ýä▒(ýžĹýĄĹ Ýś╣ýŁÇ ŰÂäýé░)ýŁä ÝîîýĽůÝĽá ýłś ý׳ŕ▓î ŰÉťŰőĄ.
3.3 ýäáŰ░Ľ ŕÁÉÝćÁŰčë ýśłýŞí
ýäáŰ░ĽýŁś ŕÁÉÝćÁŰčëýŁÇ ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×íýŁä ýśłýŞíÝĽśŰŐöŰŹ░ ŕ░Çý׹ ŕŞ░Ű│ŞýŁ┤ ŰÉśŰŐö ýáĽŰ│┤ýŁ┤ŰőĄ. Ű│Ş Űů╝ŰČŞýŚÉýäťýŁś ýäáŰ░Ľ ŕÁÉÝćÁŰčëýŁÇ ŰîÇýâü ÝĽ┤ýŚşýŁä ýÜ┤ÝĽşÝĽśŰŐö ýäáŰ░ĽýŁś ý▓Ö ýłśŰą╝ ýŁśŰ»ŞÝĽśŰę░, ýáäý▓┤ ŕÁÉÝćÁŰčëŕ│╝ ŰůŞŰôť ýśüýŚş ŕÁÉÝćÁŰčëýť╝Űíť ŕÁČŰÂäŰÉťŰőĄ. ŰůŞŰôť ýśüýŚş ŕÁÉÝćÁŰčëýŁÇ ýĽ× ýáłýŚÉýäť ŕŞ░ýłáÝĽť ýäáŰ░Ľ ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôť ýśüýŚşýŚÉ ÝĆČÝĽĘŰÉť ýäáŰ░ĽýŁś ý▓Ö ýłśýŁ┤Űę░, ŕ░ü ýśüýŚşýŁś ŕÁÉÝćÁŰčëýŁä ۬ĘŰĹÉ ÝĽęýé░ÝĽśŰę┤ ýáäý▓┤ ŕÁÉÝćÁŰčëŕ│╝ ŕ░ÖŰőĄ. ÝĽťÝÄŞ, ýáĽŰ░Ľ ýĄĹýŁ┤ŕ▒░Űéś ýáĹýĽłŰÉť ýâüÝâťýŁś ýäáŰ░ĽýŁÇ ŕÁÉÝćÁýŁś ÝŁÉŰŽäýŚÉ Ű»Şý╣śŰŐö ýśüÝľąýŁ┤ ýáüŕŞ░ ŰĽîŰČŞýŚÉ ŕÁÉÝćÁŰčë ýé░ýáĽýŚÉŰŐö ýáťýÖŞÝĽśýśÇŰőĄ.
Ű│Ş Űů╝ŰČŞýŚÉýäťýŁś ŕÁÉÝćÁŰčë ýśłýŞí ýĽîŕ│áŰŽČýŽśýŁÇ ÝüČŕ▓î ŰĹÉ ŰÂÇŰÂäýť╝Űíť ŰéśŰłî ýłś ý׳ŰőĄ. ŰĘ╝ýáÇ, ŰîÇýâü ÝĽ┤ýŚşýŁś ŕ│╝ŕ▒░ ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░Űą╝ ŕŞ░ýĄÇýť╝Űíť ÝľąÝŤä 24ýőťŕ░äýŚÉ ŰîÇÝĽ┤ ýáäý▓┤ ŕÁÉÝćÁŰčëýŁä ýśłýŞíÝĽśŰę░, ŕĚŞ ÝŤä, ýśłýŞíŰÉť ýáäý▓┤ ŕÁÉÝćÁŰčëýŁä ýśüýŚşŰ│ä ŕÁÉÝćÁŰčë Ű╣äýťĘýŚÉ Űö░ŰŁ╝ Ű░░ŰÂäÝĽśýŚČ ŰůŞŰôť ýśüýŚş ŕÁÉÝćÁŰčëýŁä ýÂöýáĽÝĽťŰőĄ.
ýáäý▓┤ ŕÁÉÝćÁŰčëýŁś ýśłýŞíýŁÇ ýőťŕ│äýŚ┤ ŰŹ░ýŁ┤Ýä░ ýśłýŞí ýĽîŕ│áŰŽČýŽśýŁŞ Prophet (Taylor, 2018)ýŁä ýéČýÜęÝĽťŰőĄ. Prophet ýĽîŕ│áŰŽČýŽśýŁÇ ýú╝ŕŞ░ýáüýŁ┤ýžÇ ýĽŐýŁÇ ÝŐŞŰáîŰôť ýáĽŰ│┤ýÖÇ ŕ│äýáł, ýŤö, ýőťŕ░ä Űô▒ ýú╝ŕŞ░ýáüýť╝Űíť ŰéśÝâÇŰéśŰŐö ÝîĘÝä┤ ýáĽŰ│┤Űą╝ ŕ▓░ÝĽęÝĽśýŚČ ýśłýŞíýŁä ýłśÝľëÝĽśŰę░, ýáĽÝÖĽŰĆäŕ░Ç Űćĺŕ│á ý▓śŰŽČ ýćŹŰĆäŕ░Ç Ű╣áŰąŞ ý׹ýáÉýŁ┤ ý׳ŰőĄ. ý×ůŰáą ýáĽŰ│┤ŰŐö ýőťŕ│äýŚ┤ ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░ýŁ┤Űę░, ýśłýŞí ýÜöý▓ş ýőťŕ░äýŁä ŕŞ░ýĄÇýť╝Űíť ÝľąÝŤä 24ýőťŕ░äýŁś ýśłýŞíŰÉť ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░Űą╝ ýÂťŰáąÝĽťŰőĄ.
ÝĽťÝÄŞ, ŰůŞŰôť ýśüýŚşýŁś ŕÁÉÝćÁŰčë Ű╣äýťĘýŁÇ ÝĽşŰžîýŁś ŕÁÉÝćÁ ÝŐ╣ýä▒ýŁ┤ Ű░śýśüŰÉśýľ┤ ýőťŕ░äŰîÇýŚÉ Űö░ŰŁ╝ ýäťŰíť ŰőĄŰąŞ ÝŐ╣ýžĽýŁä ŕ░ÇýžÇŕ│á ý׳ŰőĄ. Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ŰůŞŰôť ýśüýŚşýŁś ŕ│╝ŕ▒░ ŕÁÉÝćÁŰčë Ű╣äýťĘýŁś ýőťŕ░äŰîÇŰ│ä ÝĆëŕĚáŕ░ĺýŁä ýŁ┤ýÜęÝĽśŰę░, ýŁ┤Űáçŕ▓î ŕ│äýé░ŰÉť ŕÁÉÝćÁŰčë Ű╣äýťĘýŚÉ Űö░ŰŁ╝ ýáäý▓┤ ŕÁÉÝćÁŰčëýŁä Ű░░ŰÂäÝĽśýŚČ ŰůŞŰôť ýśüýŚşŰ│ä ŕÁÉÝćÁŰčëýŁä ýśłýŞíÝĽťŰőĄ.
3.4 ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×íŰĆä ýśłýŞí
ýäáŰ░Ľ ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ ýáĽŰ│┤ýÖÇ ýśłýŞíŰÉť ýäáŰ░Ľ ŕÁÉÝćÁŰčëýŁä ýŁ┤ýÜęÝĽśýŚČ ŕÁÉÝćÁ Ýś╝ý×íŰĆäŰą╝ ýśłýŞíÝĽá ýłś ý׳ŰőĄ. ýĽ×ýäť ŕŞ░ýłáÝĽť Ű░öýÖÇ ŕ░ÖýŁ┤, Ű│Ş Űů╝ŰČŞýŚÉýäť ýáĽýŁśÝĽśŰŐö ŕÁÉÝćÁ Ýś╝ý×íýŁÇ ýäáŰ░Ľ ŕ░ä ýí░ýÜ░ ŕ░ÇŰŐąýä▒ýŁ┤ ŰćĺýĽäýäť ŕ┤Çýáť ŕ░ťý×ůýŁ┤ ÝĽäýÜöÝĽť ýâüÝÖęýŁä ýŁśŰ»ŞÝĽśŰę░, ŕÁÉÝćÁŰčëýŚÉ Űö░ŰąŞ Ýś╝ý×íŰĆä ŕ░ĺýŚÉ ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ ýŚ░ŕ▓░ŰĆä ýáĽŰ│┤Űą╝ ýÂöŕ░ÇÝĽśýŚČ Ýś╝ý×íŰĆäŰą╝ ŕ│äýé░ÝĽťŰőĄ.
ŕÁÉÝćÁŰčëýŚÉ Űö░ŰąŞ Ýś╝ý×íŰĆäŰŐö ÝĽ┤Űő╣ ýőťŕ░äŰîÇýŁś ÝĆëŕĚá ŕÁÉÝćÁŰčëýŁä ŕŞ░ýĄÇýť╝Űíť ŕŞ░Ű│Ş Ýś╝ý×íŰĆä ŕ░ĺýŁä ýÂöýáĽÝĽśŰę░, ŕ░ü ŰäĄÝŐŞýŤîÝüČ ýŚÉýžÇýŚÉ ŰîÇÝĽ┤ ý×ůŰáą ýŚ░ŕ▓░ŰĆä(in-degree)ýÖÇ ýÂťŰáą ýŚ░ŕ▓░ŰĆä(out-degree) ŕ░ĺýŁä Ű░śýśüÝĽśýŚČ ýÁťýóů Ýś╝ý×íŰĆäŰą╝ ŕ│äýé░ÝĽťŰőĄ. Ýś╝ý×íŰĆäŰŐö ýőŁ (1)ýŚÉ Űö░ŰŁ╝ ŕ░ü ýŚÉýžÇŰ│äŰíť ŕ│äýé░ŰÉśŰę░, -1.0ŰÂÇÝä░ 1.0ŕ╣îýžÇýŁś ŕ░ĺýŁä ŕ░ÇýžäŰőĄ.
Vpred : predicted traffic volume
╬╝(Vprev) : mean of previous traffic volume
VRrgn : traffic volume ratio of regio
Irgn : in-degree of regio
Orgn : out-degree of region
¤ërgn : network degree consta
3.5 ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×íŰĆä ŕ░ÇýőťÝÖö
ýśłýŞíŰÉť Ýś╝ý×íŰĆä ýáĽŰ│┤ŰŐö Fig. 4ýÖÇ ŕ░ÖýŁ┤ ŰäĄÝŐŞýŤîÝüČ ŕĚŞŰלÝöäýŁś ÝśĽÝâťŰíť ýÂťŰáąÝĽśŰę░, Ýś╝ý×íŰĆäýŚÉ Űö░ŰŁ╝ ÝĽťýé░(ÝîîŰ×Ĺ), ýŤÉÝÖť(ý┤łŰíŁ), Ýś╝ý×í(Ű╣Ęŕ░Ľ)ýŁś 3ŰőĘŕ│äŰíť ŕÁČŰÂäÝĽśýŚČ ýâëýâüýť╝Űíť ÝĹťýőťŰÉťŰőĄ. ŕ░ü ýŚÉýžÇŰŐö ŰůŞŰôť ŕ░ä ŕÁÉÝćÁ ÝŁÉŰŽäýŁä ýőŁŰ│äÝĽá ýłś ý׳ŰĆäŰíŁ Ű░ęÝľąýŁä ŕÁČŰÂäÝĽśýŚČ ÝĹťýőťÝĽśýśÇýť╝Űę░, ÝÖöŰę┤ ÝĽśŰőĘýŁś ýŐČŰŁ╝ýŁ┤ŰŹöŰą╝ ÝćÁÝĽ┤ ýśłýŞí ýőťŕ░ä(1ýőťŕ░ä ŕ░äŕ▓ę)ýŁä ýí░ýáłÝĽśýŚČ ýśłýŞí Ýś╝ý×íŰĆäŰą╝ ÝÖĽýŁŞÝĽá ýłś ý׳ŰĆäŰíŁ ÝĽśýśÇŰőĄ.
4. ýőĄÝŚś Ű░Ć ŕ│áý░░
4.1 ýőĄÝŚś ŕ░ťýÜö
Ű│Ş Űů╝ŰČŞýŚÉýäť ýáťýĽłŰÉť ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×í ýśłýŞí Ű░ęŰ▓ĽýŁä ŕ▓ÇýŽŁÝĽśŕŞ░ ýťäÝĽ┤ ýőĄÝĽ┤ýŚş ŕÁÉÝćÁ ŰŹ░ýŁ┤Ýä░Űą╝ ýáüýÜęÝĽť ýőĄÝŚśýŁä ýłśÝľëÝĽśŕ│á ŕĚŞ ŕ▓░ŕ│╝Űą╝ ŰÂäýäŁÝĽśŕ│áý×É ÝĽťŰőĄ.
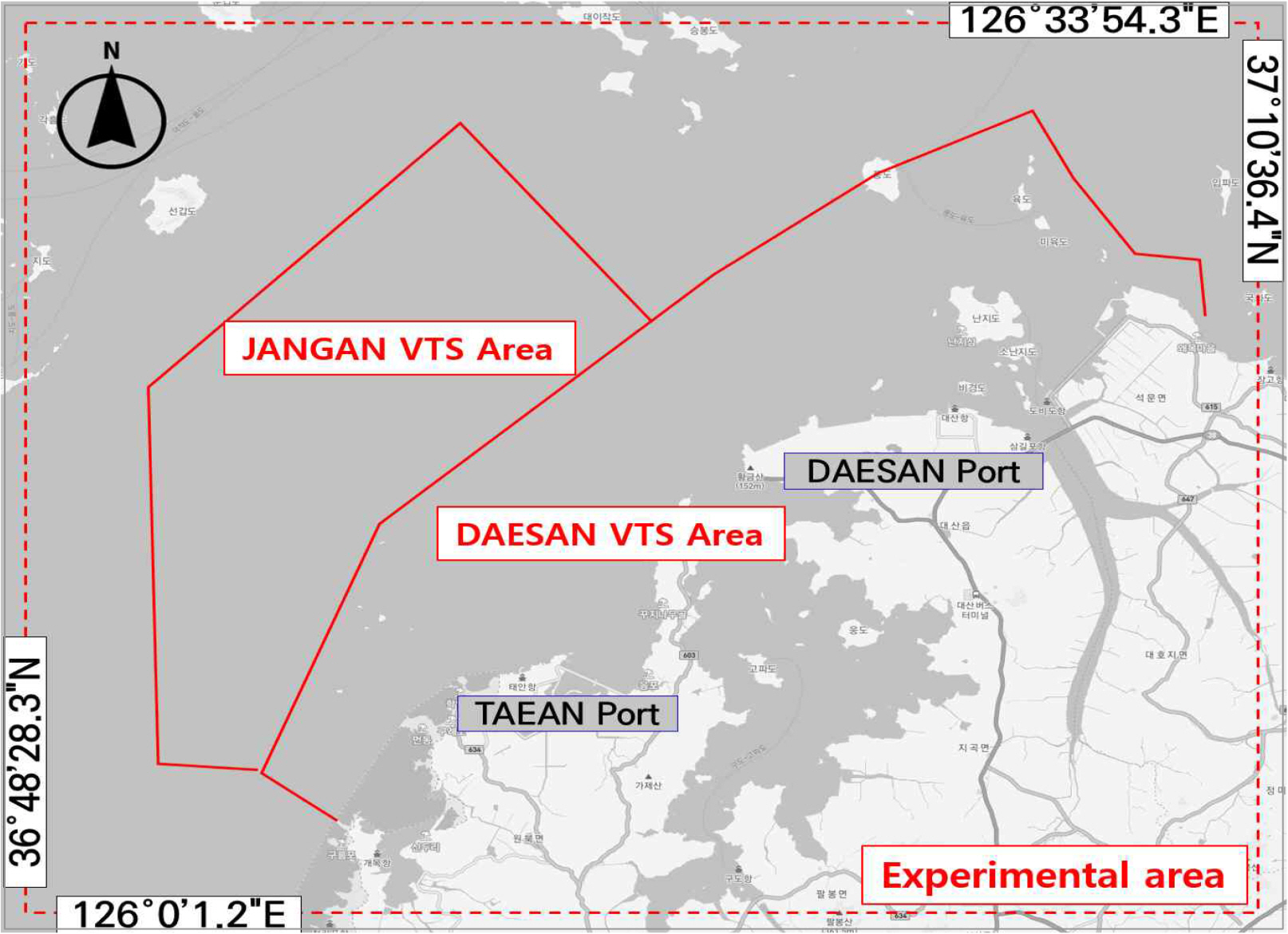
ýőĄÝŚś ŰîÇýâü ÝĽşŰžîýŁŞ ŰîÇýé░ÝĽşýŁÇ ŕÁşŰé┤ ýú╝ýÜö ŰČ┤ýŚşÝĽş ýĄĹ ÝĽť ŕ││ýť╝Űíť ýú╝Űíť ýäŁýťáÝÖöÝĽÖ ŕŞ░ýŚůýŁś ÝĽşŰžî ýőťýäĄŰôĄýŁ┤ ýäĄý╣śŰÉśýľ┤ ý׳ýť╝Űę░, Ýśäý×ČŰŐö ý┤Ł 31ŕ░ťýŁś ýäáýäŁýŁ┤ ýÜ┤ýśüŰÉśŕ│á ý׳ŰőĄ(2023Űůä ŕŞ░ýĄÇ). ŰśÉÝĽť, ŰîÇýé░ÝĽş ŕĚ╝ý▓ś ÝĽ┤ýŚşýŚÉŰŐö ýŁŞý▓ťÝĽş, ÝĆëÝâŁÝĽş, ŰîÇýé░ÝĽşýŁä ýŁ┤ýÜęÝĽśŰŐö ýäáŰ░ĽŰôĄýŁ┤ ý×ůÝĽş ŰîÇŕŞ░ ý׹ýćîŰíť ýŁ┤ýÜęÝĽśŰŐö ÔÇśý׹ýĽłýäť ŰîÇŕŞ░ ýáĽŰ░ĽýžÇÔÇÖŕ░Ç ý׳ýľ┤ýäť ŰőĄýľĹÝĽśŕ│á Ű│Áý×íÝĽť ýäáŰ░Ľ ŕÁÉÝćÁ ÝŁÉŰŽäýŁä Ű│┤ýŁ┤ŰŐö ýžÇŰŽČÝĽÖýáü ÝŐ╣ýä▒ýŁä ŕ░ÇýžäŰőĄ. Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö Fig. 5ýÖÇ ŕ░ÖýŁ┤ ŰîÇýé░ÝĽş ŕ┤Çýáť ŕÁČýŚşŕ│╝ ý׹ýĽłýäť ŕ┤Çýáť ŕÁČýŚşýŁä ۬ĘŰĹÉ ÝĆČÝĽĘÝĽśŰŐö ÝĽ┤ýŚşýŚÉ ŰîÇÝĽ┤ ýőĄÝŚśýŁä ýłśÝľëÝĽśýśÇŰőĄ.
ýőĄÝŚśýŚÉ ýéČýÜęŰÉśŰŐö ýäáŰ░Ľ ŕÁÉÝćÁ ŰŹ░ýŁ┤Ýä░ŰŐö ŕ┤Çýáť Ű╣ůŰŹ░ýŁ┤Ýä░ ý▓┤ŕ│ä(BEAD)ýŁś API(Application Programming Interface)Űą╝ ÝćÁÝĽ┤ ýÂöýÂťŰÉśýŚłŰőĄ. BEAD ýőťýŐĄÝůťýŁÇ AIS, RADAR, VHF Űô▒ ÝĽ┤ýâüŕÁÉÝćÁŕ┤Çýáťýä╝Ýä░ýŚÉýäť ýłśýžĹŰÉśŰŐö ŕ┤Çýáť ŰŹ░ýŁ┤Ýä░Űą╝ ýőĄýőťŕ░äýť╝Űíť ýłśýžĹÝĽśŕ│á ýáÇý׹, ŰÂäýäŁÝĽá ýłś ý׳ŰŐö Ű╣ůŰŹ░ýŁ┤Ýä░ ý▓┤ŕ│äýŁ┤ŰőĄ. BEAD ýőťýŐĄÝůťýŁÇ Ýśäý×Č ŰîÇýé░ÝĽş ÝĽ┤ýâüŕÁÉÝćÁŕ┤Çýáťýä╝Ýä░ýŚÉ ýäĄý╣śŰÉśýľ┤ ýőťŰ▓ö ýÜ┤ýśü ýĄĹýŁ┤Űę░, APIŰą╝ ÝćÁÝĽ┤ ŰîÇýÜęŰčëýŁś ŕ┤Çýáť ŰŹ░ýŁ┤Ýä░Űą╝ ýí░ÝÜîÝĽśŕ│á ýÂöýݼá ýłś ý׳ŰőĄ. Ű│Ş ýőĄÝŚśýŚÉýäť ýéČýÜęŰÉť ŰŹ░ýŁ┤Ýä░ŰŐö ýĽŻ 6ŕ░ťýŤö ŰĆÖýĽł(2022Űůä 1ýŤöŰÂÇÝä░ 2022Űůä 6ýŤöŕ╣îýžÇ) ýłśýžĹŰÉť ŕ┤Çýáť ŰŹ░ýŁ┤Ýä░ýŁ┤Űę░, ÝĽşýáü ŰŹ░ýŁ┤Ýä░ýÖÇ ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░Űíť ŕÁČŰÂäŰÉťŰőĄ. ÝĽşýáü ŰŹ░ýŁ┤Ýä░ŰŐö AIS Ű░Ć RADAR ŰŹ░ýŁ┤Ýä░ŕ░Ç ÝćÁÝĽęŰÉť ŰČ╝ÝĹť ŰŹ░ýŁ┤Ýä░ýŁ┤Űę░, 1ý┤ł ýú╝ŕŞ░Űíť ýâŁýä▒ŰÉť ŰŹ░ýŁ┤Ýä░ŕ░Ç ýâŁýä▒ ýőťŕ░üýŚÉ Űö░ŰŁ╝ ýáĽŰáČŰÉśýľ┤ ý׳ŰőĄ. ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░ýŚÉŰŐö ŰžĄ 10ŰÂä ŕ░äŕ▓ęýť╝Űíť ýáäý▓┤ ŕÁÉÝćÁŰčëŕ│╝ ŰůŞŰôť ýśüýŚşŰ│ä ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░ŕ░Ç ÝĆČÝĽĘŰÉśýľ┤ ý׳ŰőĄ. Ű│Ş ýőĄÝŚśýŚÉýäť ýéČýÜęŰÉť ۬ĘŰôá ŰŹ░ýŁ┤Ýä░ŰŐö ÝĽ┤ýľĹŕ▓Żý░░ý▓şýŁ┤ ýćîýťáŕÂîýŁä ŕ░ÇýžÇŕ│á ý׳ýť╝Űę░, ÝĽ┤ýâüŕÁÉÝćÁŕ┤Çýáťýä╝Ýä░ Űé┤ŰÂÇýŚÉýäťŰžî ýáĹŕĚ╝ýŁ┤ ŕ░ÇŰչݼśŰőĄ.
ÝĽťÝÄŞ, ýÂöýÂťŰÉť ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ ýŁ┤ýÜęÝĽśýŚČ ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČŰą╝ Ű»ŞŰŽČ ýâŁýä▒ÝĽśýśÇýť╝Űę░, ýâŁýä▒ŰÉť ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČ ýáĽŰ│┤Űą╝ Ű░öÝâĽýť╝Űíť ŕÁÉÝćÁŰčë Ű░Ć Ýś╝ý×íŰĆäŰą╝ ýőĄýőťŕ░ä ýśłýŞíÝĽśýśÇŰőĄ.
ýőĄÝŚśýŁÇ 2022Űůä 6ýŤö 16ýŁ╝ 0ýőťŰą╝ ŕŞ░ýĄÇýť╝Űíť ÝľąÝŤä 24ýőťŕ░ä ŰĆÖýĽłýŁś ŕÁÉÝćÁŰčëŕ│╝ Ýś╝ý×íŰĆäŰą╝ ýśłýŞíÝĽť ÝŤä, ýőĄýáť ŕÁÉÝćÁ ŰŹ░ýŁ┤Ýä░ýÖÇýŁś Ű╣äŕÁÉŰą╝ ÝćÁÝĽ┤ ýśłýŞí ŕ▓░ŕ│╝Űą╝ ŕ▓ÇýŽŁÝĽśýśÇŰőĄ.
4.2 ýőĄÝŚś ŕ▓░ŕ│╝ ŰÂäýäŁ
4.2.1 ŕÁÉÝćÁŰčë ýśłýŞí
ýśłýŞí ýőťý×Ĺ ýőťŕ░ü(2022-06-16 00:00:00)ýŁä ŕŞ░ýĄÇýť╝Űíť ŕ│╝ŕ▒░ 3ŕ░ťýŤöŕ░äýŁś ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░Űą╝ ý×ůŰáąÝĽśýŚČ ÝľąÝŤä 24ýőťŕ░ä ŰĆÖýĽłýŁś ŕÁÉÝćÁŰčëýŁä ýśłýŞíÝĽśýśÇýť╝Űę░, ýőĄÝŚśýŚÉ ýéČýÜęŰÉť Prophet ۬ĘŰôłýŁś ýäŞŰÂÇ ýéČÝĽşýŁÇ Table 1ŕ│╝ ŕ░ÖŰőĄ.
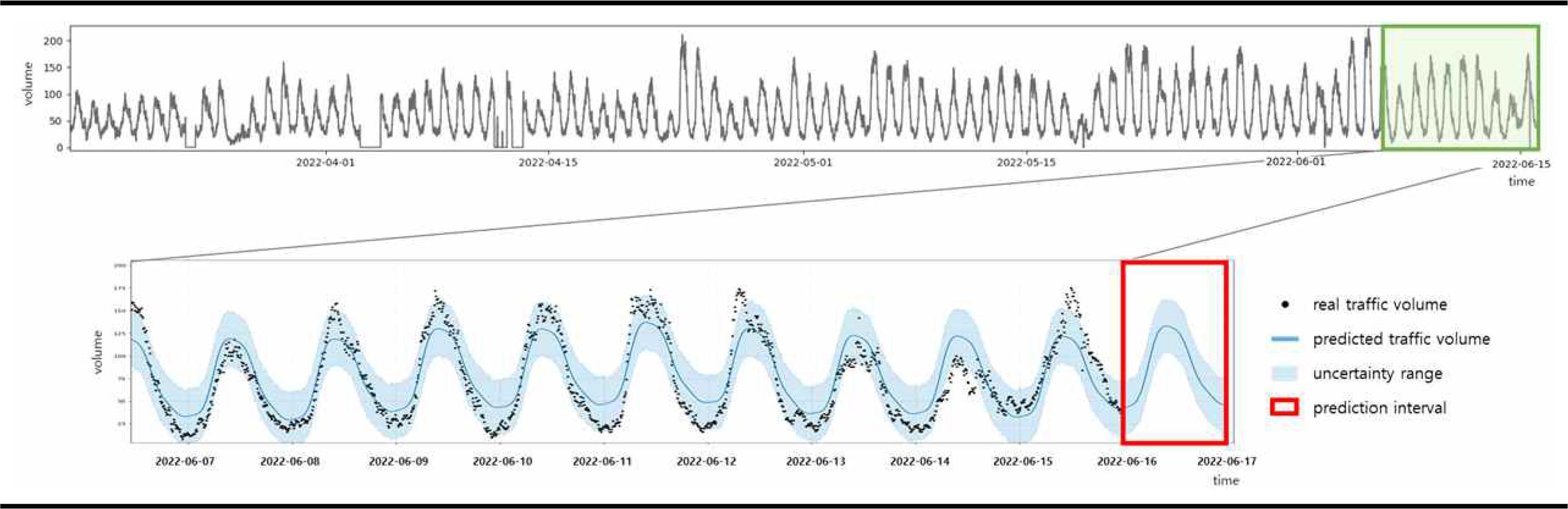
Fig. 6ýŁÇ ý×ůŰáąŰÉť ŕ│╝ŕ▒░ ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░ýÖÇ ŕÁÉÝćÁŰčë ýśłýŞí ŕ▓░ŕ│╝Űą╝ ŰéśÝâÇŰéŞŰőĄ. Fig. 6ýŁś ýĽäŰלý¬Ż ŕĚŞŰלÝöäýŚÉ ÝŝݜäŰÉť ŕ▓ÇýŁÇýâë ýáÉýŁÇ ýőĄýáť ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░ýŁ┤Űę░, ÝîîŰ×Çýâë ýőĄýäáýŁ┤ ýśłýŞíŰÉť ŕÁÉÝćÁŰčëýŁä ýŁśŰ»ŞÝĽťŰőĄ. Ű╣Ęŕ░äýâë ýéČŕ▓ęÝśĽýŁÇ ýśłýŞí ŕÁČŕ░ä(24ýőťŕ░ä)ýŁ┤Űę░, ýśłýŞí ŕ▓░ŕ│╝ŰŐö 1ýőťŕ░ä ŕ░äŕ▓ęýť╝Űíť ý┤Ł 24ŕ░ťýŁś ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░ŕ░Ç ýâŁýä▒ŰÉťŰőĄ.
ŰîÇýâü ÝĽ┤ýŚşýŁś ŕÁÉÝćÁŰčëýŁÇ 12ýőťýŚÉýäť 13ýőť ýéČýŁ┤ýŚÉ ýÁťŰîÇŕ░Ç ŰÉśŕ│á, 23ýőťýŚÉýäť 1ýőť ýéČýŁ┤ýŚÉ ýÁťýćîŕ░Ç ŰÉśŰŐö ÝîĘÝä┤ýŁä Ű│┤ýŁ┤Űę░, ýŁ┤ŰčČÝĽť ÝîĘÝä┤ýŁ┤ ýŁ╝ ŰőĘýťäŰíť Ű░śŰ│ÁŰÉśŰŐö ýú╝ŕŞ░ýáü ÝŐ╣ýä▒ýŁ┤ ý׳ŰőĄ. ýśłýŞí ŕ▓░ŕ│╝ýŚÉŰŐö ýŁ┤ŰčČÝĽť ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░ýŁś ýú╝ŕŞ░ýáü ÝŐ╣ýä▒ýŁ┤ ýל Ű░śýśüŰÉśýŚłýť╝Űę░, 1ýŤöŰÂÇÝä░ ýáÉý░Ę ýŽŁŕ░ÇÝĽśŕ│á ý׳ŰŐö ýáäýŚşýáüýŁŞ ŕ▓ŻÝľąŰĆä ÝĆČÝĽĘŰÉť ŕ▓âýť╝Űíť Ű│┤ýŁŞŰőĄ.
ýśłýŞí ýśĄý░ĘŰŐö ýĽŻ 5.0ýť╝Űíť ýőĄýáť ŕÁÉÝćÁŰčëŕ│╝ýŁś MAE(Mean Absolute Error)Űą╝ ŕ│äýé░ÝĽśýŚČ ýŞíýáĽÝĽśýśÇýť╝Űę░, ŰîÇýâü ÝĽ┤ýŚşýŁś ýáäý▓┤ ŕÁÉÝćÁŰčëýŁ┤ ÝĆëŕĚá 100ý▓Öŕ░ÇŰčëý×äýŁä ŕ│áŰáĄÝĽśŰę┤ ýśłýŞí ŕ▓░ŕ│╝Űą╝ ýőáŰó░ÝĽá ýłś ý׳ýŁä ŕ▓âýť╝Űíť ÝîÉŰőĘŰÉťŰőĄ. ŰśÉÝĽť, ýśłýŞí ŕŞ░ŕ░äýŁ┤ પýľ┤ýžłýłśŰíŁ ýśĄý░Ęŕ░Ç ŕŞëýŽŁÝĽśýŚČ ýśłýŞí ŕ▓░ŕ│╝ýŚÉ ŰîÇÝĽť ýőáŰó░ŰĆäŕ░Ç Űé«ýĽäýžÇŕ▓î ŰÉśŰŐöŰŹ░, Ű│Ş ýőĄÝŚśýŁś ýśłýŞí ŕŞ░ŕ░äýŁŞ 24ýőťŕ░ä ŰĆÖýĽłýŁÇ ýśłýŞí ŕ▓░ŕ│╝ýŚÉ ŰîÇÝĽť ýőáŰó░ŰĆäŕ░Ç ýťáýžÇŰÉĘýŁä ýĽî ýłś ý׳ŰőĄ.
4.2.2 ŕÁÉÝćÁ Ýś╝ý×íŰĆä ýśłýŞí
ýśłýŞíŰÉť ŕÁÉÝćÁŰčë ŰŹ░ýŁ┤Ýä░Űą╝ Ű░öÝâĽýť╝Űíť ýőĄÝŚś ÝĽ┤ýŚş ýáäý▓┤ýŚÉ ŰîÇÝĽť 24ýőťŕ░ä ŰĆÖýĽłýŁś Ýś╝ý×íŰĆäŰą╝ ýśłýŞíÝĽśŕ│á ŕĚŞ ŕ▓░ŕ│╝Űą╝ ŰÂäýäŁÝĽśýśÇŰőĄ.
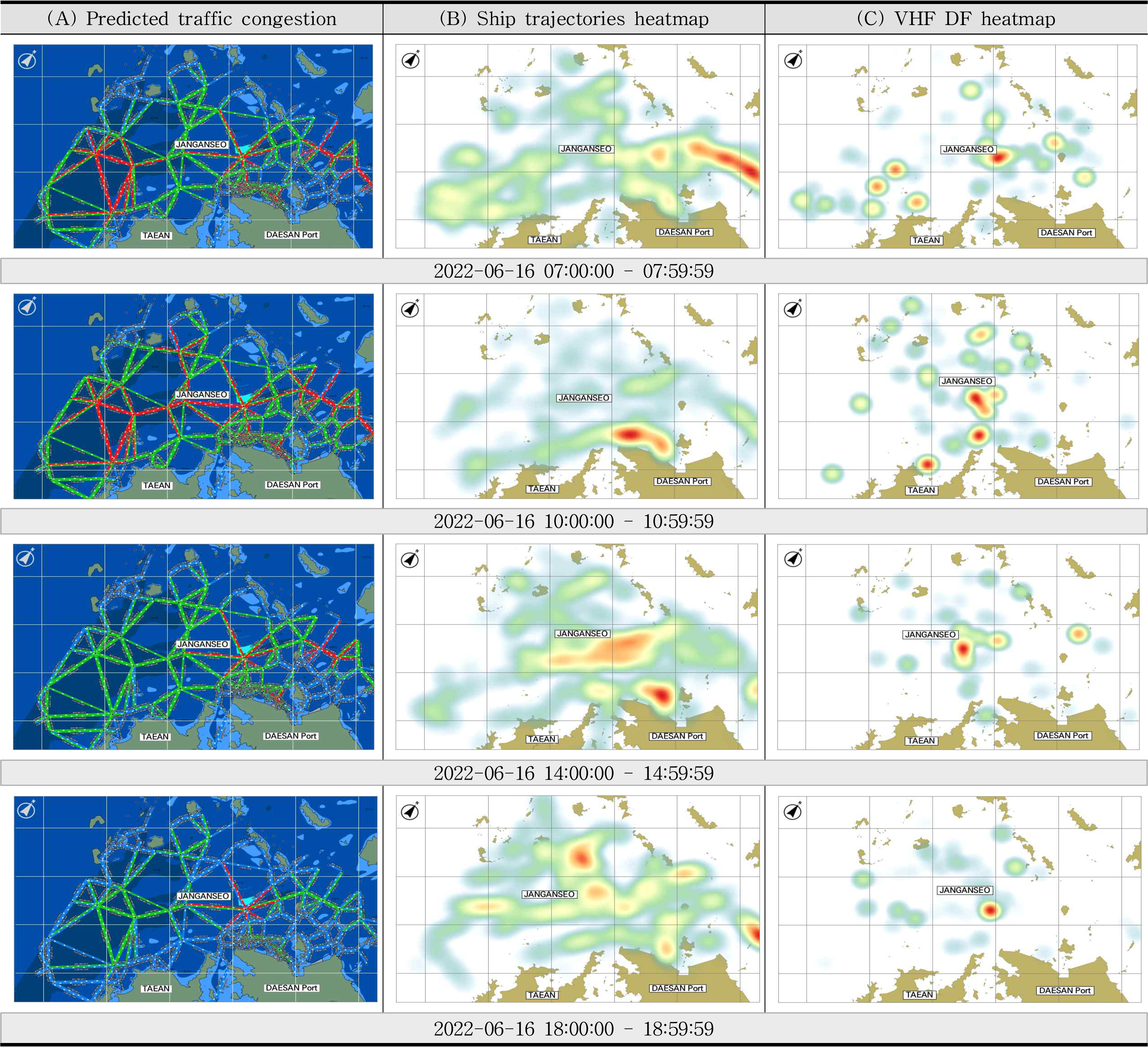
Fig. 7ýŁś (A)ýŚ┤ýŁÇ ýú╝ýÜö ýőťŕ░äŰîÇýŚÉ ŰîÇÝĽť Ýś╝ý×íŰĆä ýśłýŞí ŕ▓░ŕ│╝Űą╝ ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČýÖÇ ÝĽĘŕ╗ś ŕ░ÇýőťÝÖöÝĽť ŕ▓░ŕ│╝ýŁ┤ŰőĄ. Fig. 7ýŁś (B)ýŚ┤ýŁÇ Ýś╝ý×íŰĆäýÖÇ ýőĄýáť ŕÁÉÝćÁŰčëŕ│╝ýŁś Ű╣äŕÁÉŰą╝ ýťäÝĽ┤ ÝĽ┤Űő╣ ýőťŕ░äŰîÇýŁś ýäáŰ░Ľ Ű░ÇýžĹŰĆäŰą╝ Ý׳ÝŐŞŰžÁ ÝśĽÝâťŰíť ÝĹťýőťÝĽśýśÇŰőĄ. Ý׳ÝŐŞŰžÁýŁÇ ýäáŰ░ĽýŁś ýÜ┤ÝĽş ýćŹŰĆäŕ░Ç 1 ŰůŞÝŐŞ ýŁ┤ýâüýŁŞ ŰŹ░ýŁ┤Ýä░Űą╝ ýŁ┤ýÜęÝĽśýŚČ ýâŁýä▒ÝĽĘýť╝ŰíťýŹĘ ýáĽŰ░Ľ ýĄĹýŁ┤ŕ▒░Űéś ýáĹýĽł ýĄĹýŁŞ ýäáŰ░ĽýŁä ýáťýÖŞÝĽśýśÇýť╝Űę░, Ý׳ÝŐŞŰžÁ ýâŁýä▒ Ű░śŕ▓Ż(radius)ýŁÇ 3 kmŰíť ýáüýÜęÝĽśýśÇŰőĄ.
ÝĽťÝÄŞ, ŕÁÉÝćÁ Ýś╝ý×íýŁś ýáĽŰĆäŰą╝ ÝîÉŰőĘÝĽśŰŐö ŕŞ░ýĄÇýŁ┤ ýú╝ŕ┤ÇýáüýŁ╝ ýłś ý׳ýť╝Űę░ ýśłýŞí ŕ▓░ŕ│╝ýŚÉ ŕ░ťýŁŞý░Ęŕ░Ç Ű░ťýâŁÝĽśŰŐö ŰČŞýáťýáÉýŁ┤ ý׳ŰőĄ. Űö░ŰŁ╝ýäť Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ŕ┤Çýáť ŕÁÉýőáýŁ┤ ýŁ┤ŰúĘýľ┤ýžÇŰŐö ýťäý╣śýÖÇ Ű╣łŰĆä ýáĽŰ│┤Űą╝ ýŁ┤ýÜęÝĽśýŚČ ŕÁÉýőá Ű░ÇýžĹŰĆäŰą╝ ŕ│äýé░ÝĽśŕ│á ýŁ┤Űą╝ Ýś╝ý×íŰĆä ýśłýŞí ŕ▓░ŕ│╝ýÖÇ Ű╣äŕÁÉÝĽśýśÇŰőĄ. ýŁ┤ŰčČÝĽť ŕÁÉýőá Ű░ÇýžĹŰĆäŰŐö ŕÁÉÝćÁ Ýś╝ý×íýŁä ýáĽŰčëÝÖöÝĽśŰŐö ŕŞ░ýĄÇýť╝Űíť ÝÖťýÜęÝĽśýśÇýť╝Űę░, ýőĄýáť ŕÁÉÝćÁ Ýś╝ý×í ýâüÝÖęŕ│╝ŰŐö ý░ĘýŁ┤ŕ░Ç ý׳ýŁä ýłś ý׳ŰőĄ. ŕ┤Çýáť ŕÁÉýőáýŁ┤ Ű░ťýâŁÝĽť ýťäý╣ś ýáĽŰ│┤ŰŐö ÝĽ┤ýâüŕÁÉÝćÁŕ┤Çýáťýä╝Ýä░ýŚÉ ýäĄý╣śŰÉť VHF DF(Direction Finder) ŰŹ░ýŁ┤Ýä░ŰíťŰÂÇÝä░ ýÂöýáĽÝĽá ýłśŰĆä ý׳ŰőĄ. VHF ŕÁÉýőá ýťäý╣ś Ű░Ć Ű╣łŰĆäŰŐö Fig. 7ýŁś (C)ýŚ┤ŕ│╝ ŕ░ÖýŁ┤ ÝĽ┤Űő╣ ýőťŕ░äŰîÇýŁś DF ŰŹ░ýŁ┤Ýä░Űą╝ Ý׳ÝŐŞŰžÁ ÝśĽÝâťŰíť ÝĹťýőťÝĽśýśÇýť╝Űę░, ýáĽŰ░Ľ ýĄĹýŁ┤ŕ▒░Űéś ýáĹýĽł ýĄĹýŁŞ ýäáŰ░ĽýŁÇ ýáťýÖŞÝĽśýśÇŕ│á, Ý׳ÝŐŞŰžÁ ýâŁýä▒ Ű░śŕ▓Ż(radius)ýŁÇ 3 kmŰíť ýáüýÜęÝĽśýśÇŰőĄ.
Fig. 7ýŚÉýäť ýśłýŞíŰÉť Ýś╝ý×íŰĆä ýáĽŰ│┤ŰŐö ŕ░ÖýŁÇ ýőťŕ░äŰîÇýŁś ýäáŰ░Ľ ýÜ┤ÝĽş Ű░ÇýžĹŰĆäýÖÇ Ű╣äŕÁÉÝĽá ŰĽî ýáäŰ░śýáüýť╝Űíť ýťáýéČÝĽť ÝîĘÝä┤ýŁä ŕ░ÇýžÇŕ│á ý׳ýŁîýŁä ýĽî ýłś ý׳ŰőĄ. Fig. 7ýŁś ýśĄýáä 7ýőťýŚÉ ŰîÇÝĽť Ýś╝ý×íŰĆä ýśłýŞí ŕ▓░ŕ│╝Űą╝ ýé┤ÝÄ┤Ű│┤Űę┤, ý׹ýĽłýäť ýáĽŰ░ĽýžÇŰą╝ ýĄĹýőČýť╝Űíť ýľĹý¬Ż ýśüýŚşýŁś Ýś╝ý×íŰĆäŕ░Ç Űćĺŕ▓î ýśłýŞíŰÉśýŚłŰőĄ. ÝĽ┤Űő╣ ýőťŕ░äŰîÇýŁś ýőĄýáť ŕÁÉÝćÁŰčëýŁÇ ÝĆëÝâŁÝĽşýť╝Űíť ý×ůýݼşÝĽśŰŐö ýśüýŚşýŚÉ Ű░ÇýžĹŰÉśýľ┤ ý׳ýľ┤ýäť ýśłýŞíŰÉť Ýś╝ý×í ýśüýŚşŕ│╝ ŰőĄýćî ý░ĘýŁ┤ŕ░Ç ý׳ýžÇŰžî, ýőĄýáť ŕÁÉýőáýŁ┤ ýŁ┤ŰúĘýľ┤ýžä ýśüýŚşýŁÇ ýśłýŞíŰÉť Ýś╝ý×íŰĆä ýśüýŚşŕ│╝ ýťáýéČÝĽť ŕ▓âýť╝Űíť ŰéśÝâÇŰéČŰőĄ. Fig. 7ýŁś 18ýőťýŚÉ ŰîÇÝĽť Ýś╝ý×íŰĆä ýśłýŞí ŕ▓░ŕ│╝ýŚÉýäťŰĆä ý׹ýĽłýäť ýáĽŰ░ĽýžÇ ŰÂÇŕĚ╝ýŁś ÝĽ┤ýŚşýŚÉ Ýś╝ý×íýŁ┤ ýśłýâüŰÉśýŚłýžÇŰžî, ŕÁÉÝćÁ Ű░ÇýžĹ ýśüýŚşŕ│╝ŰŐö ŰőĄŰąŞ ýľĹýâüýŁä Ű│┤ýśÇýť╝Űę░, ŕÁÉýőá ýśüýŚş Ý׳ÝŐŞŰžÁŕ│╝ŰŐö ýŁ╝ý╣śÝĽĘýŁä ýĽî ýłś ý׳ýŚłŰőĄ.
ýŁ╝Ű░śýáüýŁŞ ŕ▓ŻýÜ░ŰŐö ŕÁÉÝćÁ Ýś╝ý×íŰĆäŕ░Ç ŕÁÉÝćÁ Ű░ÇŰĆäýÖÇ Ű╣äŰíÇÝĽśýžÇŰžî, ŕĚŞŰáçýžÇ ýĽŐýŁÇ ŕ▓ŻýÜ░ŰĆä ýóůýóů Ű░ťýâŁÝĽťŰőĄ. Ű│Ş ýőĄÝŚśýŚÉýäťýÖÇ ŕ░ÖýŁ┤ ŕÁÉÝćÁ Ű░ÇýžĹŰĆäŕ░Ç Űé«ýžÇŰžî, ŕ┤Çýáť ŕÁÉýőáýŁ┤ ŰžÄýŁ┤ Ű░ťýâŁÝĽśŰŐö ŕ▓ŻýÜ░ýŚÉŰŐö Ýś╝ý×íÝĽť ýâüÝÖęýť╝Űíť, ŕÁÉÝćÁ Ű░ÇýžĹŰĆäŕ░Ç ŰćĺýžÇŰžî, ŕ┤Çýáť ŕÁÉýőáýŁ┤ Ű░ťýâŁÝĽśýžÇ ýĽŐŰŐö ŕ▓ŻýÜ░ŰŐö ÝĽťýé░ÝĽť ýâüÝÖęýť╝Űíť ýÂöýáĽÝĽá ýłś ý׳ýť╝Űę░, ýáťýĽłÝĽśŰŐö Ű░ęŰ▓ĽýŁś Ýś╝ý×íŰĆä ýśłýŞí ŕ▓░ŕ│╝ŕ░Ç ýŁ┤Űą╝ ýל Ű░śýśüÝĽśŕ│á ý׳ŰőĄŕ│á ÝîÉŰőĘŰÉťŰőĄ.
4.2.3 ÝŐ╣ýἠݼ┤ýŚşýŁś Ýś╝ý×í ýőťŕ░äŰîÇ ýśłýŞí
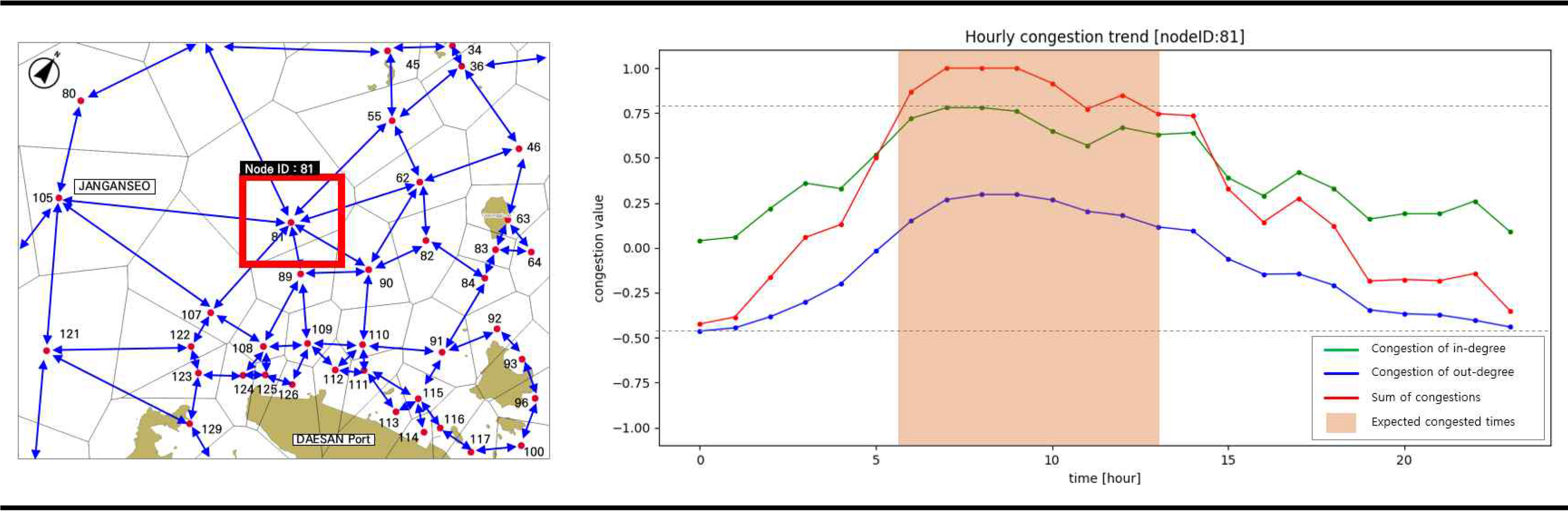
ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČýŁś ŕ░ü ýŚÉýžÇýŚÉ ŰîÇÝĽ┤ ýśłýŞíŰÉť Ýś╝ý×íŰĆä ýáĽŰ│┤Űą╝ ýŁ┤ýÜęÝĽśŰę┤ ÝŐ╣ýἠݼ┤ýŚşýŚÉ ŰîÇÝĽť Ýś╝ý×í ýőťŕ░äŰîÇŰą╝ ýśłýŞíÝĽá ýłśŰĆä ý׳ŰőĄ.
Fig. 8ýŁÇ ÝŐ╣ýἠݼ┤ýŚşýŚÉ ŰîÇÝĽť ŕÁÉÝćÁ ŰäĄÝŐŞýŤîÝüČýÖÇ Ýś╝ý×íŰĆä Ű│ÇÝÖö ýÂöýŁ┤Űą╝ ŰéśÝâÇŰé┤ŰŐö ŕĚŞŰלÝöäýŁ┤ŰőĄ. Fig. 8ýŁś ýÖ╝ý¬Ż ŕĚŞŰŽ╝ýŚÉýäťýÖÇ ŕ░ÖýŁ┤ 81Ű▓ł ŰůŞŰôťŰŐö ý׹ýĽłýäť ýáĽŰ░ĽýžÇ ŕĚ╝ý▓śýŁś ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôťýŁ┤ŰőĄ. ýŁ┤ ýśüýŚşýŁÇ ŰîÇŕŞ░ ýáĽŰ░ĽýžÇŰíťýäť ýú╝ýťä ýśüýŚşýŚÉýäť ýžäý×ůÝĽśŕ▒░Űéś, ýú╝ýťä ýśüýŚşýť╝Űíť ýŁ┤ŰĆÖÝĽśŰŐö ŕÁÉÝćÁ ýâüÝÖęýŁ┤ ŰžÄýŁ┤ Ű░ťýâŁÝĽśŰŐö ÝŐ╣ýžĽýŁä ŕ░ÇýžÇŰę░, ýőĄýáťŰíť ý×ůŰáą ýŚ░ŕ▓░ŰĆäýÖÇ ýÂťŰáą ýŚ░ŕ▓░ŰĆäŕ░Ç Ű¬ĘŰĹÉ 6ýŁŞ ŰäĄÝŐŞýŤîÝüČ ŰůŞŰôťýŁ┤ŰőĄ. ýŁ┤ ŰůŞŰôť ýśüýŚşýŚÉýäťýŁś Ýś╝ý×íŰĆä ýśłýŞí ŕ▓░ŕ│╝ŰŐö Fig. 8ýŁś ýśĄŰąŞý¬Ż ŕĚŞŰלÝöäýÖÇ ŕ░ÖŰőĄ. ý┤łŰíŁýâë ýäáýŁÇ ŰůŞŰôť ýśüýŚşýť╝Űíť ýžäý×ůÝĽśŰŐö Ýś╝ý×íŰĆäýŁś ÝĆëŕĚáŕ░ĺýŁä ýŁśŰ»ŞÝĽśŰę░, ÝîîŰ×ÇýâëýŁÇ ŰůŞŰôť ýśüýŚş Ű░ľýť╝Űíť ýžäýݼśŰŐö Ýś╝ý×íŰĆäýŁś ÝĆëŕĚáŕ░ĺýŁä ýŁśŰ»ŞÝĽťŰőĄ. Ű╣Ęŕ░äýâë ýäáýŁÇ ýžäý×ů Ű░Ć ýžäýÂťýŚÉ ŰîÇÝĽť Ýś╝ý×íŰĆäŰą╝ ÝĽęýé░ÝĽť ŕĚŞŰלÝöäýŁ┤Űę░, ýśĄýáä 9ýőťýŚÉýäť ýśĄýáä 10ýőť ýéČýŁ┤ýŚÉ ýÁťŰîÇ Ýś╝ý×íŰĆäŕ░Ç ýśłýâüŰÉśŕ│á, ýśĄýáä 6ýőťŰÂÇÝä░ 13ýőťŕ╣îýžÇ Ýś╝ý×í ýâüÝÖęýŁ┤ ýžÇýćŹŰÉá ŕ▓âýť╝Űíť ýśłýŞíÝĽá ýłś ý׳ŰőĄ.
5. ŕ▓░Űíá
ŕ┤Çýáť ŕÁČýŚş ýáäý▓┤Űą╝ ۬ĘŰőłÝä░Űžü ÝĽ┤ýĽ╝ ÝĽśŰŐö ÝĽ┤ýâüŕÁÉÝćÁŕ┤ÇýáťýéČŰŐö ýäáŰ░ĽýŁś ŕÁÉÝćÁ Ű░ÇýžĹŰĆäýÖÇ ŕ┤Çýáť ŕ░ťý×ůýŁ┤ ÝĽäýÜöÝĽť ýâüÝÖęýŁä ۬ĘŰĹÉ ŕ│áŰáĄÝĽśýŚČ ŕÁÉÝćÁ Ýś╝ý×íýŁä ÝîÉŰőĘÝĽťŰőĄ. ýŁ┤ýŚÉ Ű│Ş Űů╝ŰČŞýŚÉýäťŰŐö ÝĽ┤ýâüŕÁÉÝćÁŕ┤ÇýáťýéČýŁś ŕ┤ÇýáÉýŚÉýäť ýäáŰ░Ľ ŕÁÉÝćÁ Ýś╝ý×íýŁä ýáĽýŁśÝĽśŕ│á, Ýś╝ý×íŰĆäýÖÇ Ýś╝ý×í ŕÁČýŚşýŁä ýśłýŞíÝĽśŰŐö Ű░ęŰ▓ĽýŁä ýáťýĽłÝĽśýśÇŰőĄ. ŕ┤Çýáť Ű╣ůŰŹ░ýŁ┤Ýä░ ý▓┤ŕ│äŰíťŰÂÇÝä░ ýÂöýÂťŰÉť ŕ│╝ŕ▒░ ÝĽşýáü ŰŹ░ýŁ┤Ýä░Űą╝ ýŁ┤ýÜęÝĽśýŚČ ýäáŰ░Ľ ŕÁÉÝćÁŰčëýŁä ýśłýŞíÝĽśŕ│á, ŰîÇýâü ÝĽ┤ýŚşýŚÉýäťýŁś ýäáŰ░Ľ ýÜ┤ÝĽş ÝîĘÝä┤ýŁä ŰÂäýäŁÝĽśýŚČ ýäáŰ░Ľ ŕ░ä ýí░ýÜ░ŕ░Ç ýśłýâüŰÉśŰŐö ÝĽ┤ýŚşýŁä ý░żýĽä Ýś╝ý×íŰĆä ÝĆëŕ░ÇýŚÉ Ű░śýśüÝĽĘýť╝ŰíťýŹĘ ŕ┤Çýáť ŕÁÉýőá ýÜöýćîŕ░Ç Ű░śýśüŰÉť ŕÁÉÝćÁ Ýś╝ý×íŰĆäŰą╝ ýśłýŞíÝĽá ýłś ý׳ŰőĄ.
ÝĽťÝÄŞ, ýőĄÝĽ┤ýŚş ŰŹ░ýŁ┤Ýä░Űą╝ ýŁ┤ýÜęÝĽť ýőĄÝŚśýŁä ÝćÁÝĽ┤ ýśłýŞíŰÉť ŕÁÉÝćÁ Ýś╝ý×íŰĆä ýáĽŰ│┤ýŚÉ ŕÁÉÝćÁ Ű░ÇýžĹŰĆäýÖÇ ŕ┤Çýáť ŕÁÉýőá ýÜöýćîŕ░Ç ýל Ű░śýśüŰÉśýŚłýŁîýŁä ÝÖĽýŁŞÝĽśýśÇŰőĄ. ýőĄÝŚś ŕ▓░ŕ│╝, ŕ┤Çýáť Ýśäý׹ýŚÉýäť ÝÖťýÜęýŁ┤ ŕ░ÇŰչݼť ýłśýĄÇýŁś ýőáŰó░ŰĆäŰą╝ Ű│┤ýśÇýžÇŰžî, Ýśäý׹ýŚÉ ýáüýÜęÝĽśŕŞ░ ýťäÝĽ┤ýäťŰŐö ŕ┤ÇýáťýéČŕ░Ç ý▓┤ŕ░ÉÝĽśŰŐö ýőĄýžłýáüýŁŞ ŕÁÉÝćÁ Ýś╝ý×íŰĆäýÖÇýŁś ý░ĘýŁ┤Űą╝ ýĄäýŁ┤ŰŐö ýäŞŰÂÇ ýí░ýáĽýŁ┤ ÝĽäýÜöÝĽá ŕ▓âýť╝Űíť ÝîÉŰőĘŰÉťŰőĄ.
ŰśÉÝĽť, ÝĽ┤ýâüŕÁÉÝćÁŕ┤ÇýáťŰą╝ ýłśÝľëÝĽśŰŐö ŰŹ░ ý׳ýľ┤ýäť ýäáŰ░ĽýŁś ýóůŰąśýÖÇ ÝüČŕŞ░, ýäáýáü ÝÖöŰČ╝ýŁś ýóůŰąś Űô▒ýŁ┤ ŕ┤Çýáť ýžĹýĄĹŰĆäýŚÉ ýśüÝľąýŁä Ű»Şý╣á ýłś ý׳ŕŞ░ ŰĽîŰČŞýŚÉ ýŁ┤Űą╝ ýÂöŕ░Ç Ű░śýśüÝĽ┤ýĽ╝ ŰŹöýÜ▒ ýáĽÝÖĽÝĽť ŕÁÉÝćÁ Ýś╝ý×íŰĆäŰą╝ ýé░ýáĽÝĽá ýłś ý׳ýŁä ŕ▓âýť╝Űíť ýéČŰúîŰÉťŰőĄ.
Ű│Ş Űů╝ŰČŞýŚÉýäť ýáťýĽłŰÉť ŕÁÉÝćÁ Ýś╝ý×íŰĆä ýáĽŰ│┤Űą╝ ýŁ┤ýÜęÝĽśýŚČ ŕ┤Çýáť ŕÁČýŚşýŚÉ ŰîÇÝĽť Ű│┤ŰőĄ ý▓┤ŕ│äýáüýŁ┤ŕ│á ŕ│╝ÝĽÖýáüýŁŞ ŕ┤ÇŰŽČŕ░Ç ýŁ┤ŰúĘýľ┤ýžÇŕ│á, ŰŹö ŰéśýĽäŕ░Ç ŕ┤ÇýáťýéČýŁś ýŚůŰČ┤ ŰíťŰôťŰą╝ ýĄäýŁ┤ŕ│á ÝĽşŰžîýŁś ýÜ┤ýśü ÝÜĘýťĘýŁä ÝľąýâüýőťÝéČ ýłś ý׳ŕŞ░Űą╝ ŕŞ░ŰîÇÝĽťŰőĄ.

 PDF Links
PDF Links PubReader
PubReader ePub Link
ePub Link Full text via DOI
Full text via DOI Download Citation
Download Citation Print
Print