1. 서 론
컨테이너 터미널을 크게 보면 선박들이 접안하는 안벽 영역과 많은 컨테이너들이 임시로 보관되는 장치장 영역으로 나눌 수 있다. 안벽에는 여러 대의 대형 안벽 크레인(QC: quay crane)이 설치되어 있어서 선박에 컨테이너를 싣거나(적하) 내리는(양하) 작업을 담당하고, QC와 장치장 사이의 컨테이너 운반을 위해서는 보통 수십 대 이상에 달하는 내부트럭(YT: yard tractor)이 동원된다. 컨테이너 터미널의 중요한 운영 목표 중 하나는 QC 작업의 지연을 최소화함으로써 선박에 대한 서비스 시간을 최대로 단축하여 생산성을 극대화하는 것이다. QC 작업이 지연되는 주요 요인은 크게 두 가지로서, 첫째는 장치장에서 대상 컨테이너들의 처리가 지연됨으로 인해 그 영향이 QC에까지 미치는 것이고, 둘째는 장치장과 QC 사이를 오가며 컨테이너를 운반하는 YT들이 지연됨으로 인해 QC가 YT를 기다리는 상황이 발생하는 것이다(Kim and Ryu, 2020). YT의 지연은 YT들에 대한 운반 작업 할당이 잘못됨으로 인해 운영 효율이 떨어져서 나타나는 경우도 있고, 터미널 내 교통 정체 때문에 주행 시간이 늘어나면서 생기는 경우도 있다. 본 논문에서는 이 중 교통 정체로 인한 문제에 효과적으로 대응하기 위해 필요한 기술로서 터미널 내 각 차로를 대상으로 가까운 미래의 차량 통과 속도를 예측하는 모델을 학습하는 방안을 제안하고자 한다. 일단 이러한 예측이 가능하게 되면 이를 기반으로 YT의 주행 지연을 최소화하는 최적 주행 경로를 찾을 수 있게 될 것이다. 우리가 일상적으로 사용하고 있는 차량 내비게이션 시스템도 최적 경로를 안내하고는 있지만, 현재 교통 상황만을 기준으로하기 때문에 주행 중 상황 변화로 인해 남은 구간의 최적 경로가 바뀌는 경우가 많고 일단 잘 못된 길로 접어들고 나면 이후의 안내가 별 도움이 되지 못하기도 한다. 그러나 컨테이너 터미널처럼 상대적으로좁은 영역 내에서는 가까운 미래의 교통 상황을 비교적 정확한 수준으로 예측할 수 있고, 이를 이용하면 보다 최적에 가까운 경로 안내가 가능해 진다.
교통 속도 예측에 관한 최근 연구는 주로 일반 도로망이나 고속도로를 대상으로 딥러닝 기술을 적용한 것들이 많다(Ma et al., 2017; Tang et al., 2017; Liao et al., 2018). 컨테이너 터미널과 관련해서는 터미널 주변의 트럭 교통량을 예측하는 연구가 있기는 했으나(Jugović et al., 2011; Nadi et al., 2021), 터미널 내부 도로에서의 교통 속도를 예측하는 연구는 찾아보기 어렵다. 어떤 도로의 교통 속도를 예측하려면 그 도로 및 연결 도로의 최근 속도와 차량 통행량과 같은 시공간 데이터 (spatio-temporal data)를 필요로 한다. 그러나 컨테이너 터미널에는 이러한 데이터 수집을 위한 기반이 갖추어져 있지 않아서 통상적인 방법으로 미래 속도를 예측하기가 어렵다. 다만, 대부분의 컨테이너 터미널이 YT에 GPS를 장착하고 있어서 그 교통 데이터를 얻을 수 있을 뿐 아니라, YT의 운영 데이터에는 YT가 가까운 미래에 어떤 작업을 위해 어디로 갈것인지에 관한 정보가 포함되어 있기 때문에 이를 미래 속도 예측에 유용하게 활용할 수 있다. 외부트럭에 대한 교통 데이터는 직접적으로 얻을 수 없지만 어떤 도로 상에서든 외부트럭과 YT의 속도가 다르지 않을 것이므로 외부트럭의 영향은 YT의 속도에 간접적으로 반영되어 있는 것으로 볼 수 있다.
본 논문은 YT와 외부트럭이 혼재하여 운행하는 컨테이너 터미널에서 YT 교통류의 속도와 밀도 정보만을 기반으로 터미널 내 각 차로에서의 교통 속도를 예측하는 모델을 학습하는 방안을 제안한다. 외부트럭의 움직임은 관측이 불가능하지만, YT는 터미널의 관제소가 안내하는 최단 거리 경로로 운행하고 그 위치와 이동 속도를 GPS를 기반으로 실시간에 파악할 수 있다고 가정한다. 시뮬레이션 실험 결과, 제안된 방법으로 학습한 모델이 내부와 외부트럭이 혼재하는 터미널 내 교통 속도를 상당히 정확한 수준으로 예측함을 확인하였다. 본 논문의 구성은 다음과 같다. 먼저 2장에서는 교통 예측에 관한 기존 연구를 소개한다. 3장에서는 컨테이너 터미널에서의 YT 운영 방식을 간략히 소개하고, 4장에서는 본 논문에서 제안하는 터미널 내 교통 속도 예측 모델의 학습 방안을 제시 한다. 5장에서는 제안 방안의 성능 검증을 위한 시뮬레이션 실험 결과를 살펴보고, 마지막으로 6장에서 결론을 맺는다.
2. 관련 연구
교통 예측(traffic forecast) 문제는 교통 속도(traffic speed), 교통류(traffic flow), 교통 수요(travel demand), 이동 소요 시간(travel time)과 같은 교통 데이터의 미래 값을 예측하는 문제다(Yuan and Li, 2021). 본 장에서는 이 중 본 논문의 주제와 직접적으로 관련이 있는 교통 속도와 교통류 예측에 관한기존 연구를 위주로 그 동향을 살펴본다.
교통류 예측은 일반 도로망에서 교차로들을 통과하는 차량 대수를 예측하는 것이 주 대상이 되고 있다. 교통류 예측은 교차로에 매설된 루프 검지기(loop detector)로부터 수집되는 통과 차량 수 데이터에 대한 분석을 기반으로 하는데, 전통적으로는 ARIMA(autoregressive integrated moving average) 모델 기반의 시계열 분석(time-series analysis)이 주를 이루었으나 최근에는 딥러닝 기법들이 활발하게 적용되고 있다. Guo et al. (2019)은 교통류 데이터의 시간과 공간 특성 간 상관관계를 보다 효과적으로 예측에 반영할 수 있는 attention 기반의 GCN (graph convolutional network)을 제안하였다. Tang et al. (2020)은 수집된 교통류 데이터에 포함된 노이즈를 줄이는 알고리즘과 인공신경망을 결합하여 예측 정확성을 개선하였다.
교통 속도 예측 역시 최근에는 딥러닝 기법을 응용하는 연구가 주를 이루고 있다. Tang et al. (2017)은 2분 간격으로 수집된 교통 속도 데이터로부터 퍼지(fuzzy) 인공 신경망을 학습하여 여러 단계 미래의 교통 속도를 예측하였다. Ma et al. (2017)은 교통 데이터를 시간과 공간 간 관계를 표현하는 2차원 이미지 데이터로 간주하여 이미지 데이터 처리에 특화된 기법인 CNN(convolutional neural network)을 적용함으로써대규모 교통망에서의 교통 속도를 예측하였다. Liao et al.(2018)은 교통 속도 예측을 위하여 교통 외의 부가 정보 데이터를 활용하였다. 즉, 도로의 지리적 구조나 공휴일 혹은 주말 여부와 같은 정보를 반영하기 위하여 GCN(graph convolutional network)을 사용하였고, 온라인 상 대중들의 질의를 분석하여 반영할 수 있도록 LSTM(long short-term memory) 기반의 RNN (recurrent neural network)도 사용하였다.
이상의 연구들은 모두 도로에 설치된 센서로 부터 수집되는 시계열 교통 데이터를 기반으로 예측 모델을 학습하는 것을 기본으로 하며, 예측 성능 향상을 위해 공간적 정보나 기타 부가 정보들을 활용하기도 한다. 그러나 본 연구가 대상으로 하는 컨테이너 터미널의 내부 도로에는 교통 데이터 수집을 위한 센서가 설치되는 경우가 드물기 때문에 이러한 방법들을 그대로 적용하기가 어렵다. 본 연구는 외부트럭과 YT가 혼재 하여 운행하는 터미널에서 외부트럭에 대한 직접적인 교통 정보가 없는 상황에서 YT의 운영 정보를 분석 활용함으로써 교통 속도를 예측한다는 점에서 기존 연구들과 구별된다.
3. 컨테이너 터미널의 YT 운영
YT의 운영에는 크게 두 가지 문제가 있다. 그 첫째는 어떤 YT가 어떤 운반 작업을 수행할지를 결정하는 작업할당 문제이고, 둘째는 할당된 작업을 수행하기 위해 어떤 경로로 목적지까지 이동할지를 결정하는 문제다. 자동화 터미널에서는 이 두 가지를 모두 자동으로 결정하고 있지만, 대부분의 일반 터미널에서는 작업할당만 중앙 관제소가 하고 주행 경로 결정은 YT 운전자에게 맡기고 있다. 현재 많은 터미널에서 YT에 GPS를 장착하여 실시간 위치 파악은 하고 있으나 주행 속도 측정이나 주행 경로 결정까지 하고 있지는 않은 실정이다. 이들 기술이 어려워서라기보다는 현 상황에서 아직 그 활용처가 없기 때문일 것으로 추정된다. 만약 차량 밀도나 속도를 측정하고 이를 기반으로 미래의 속도 예측이 가능해져서 YT가 교통 혼잡을 피하도록 주행 경로를 최적화할 수 있게 된다면 많은 터미널이 이러한 기술을 도입하리라 예상된다. 특히 최근들어 논의되고 있는 자율 주행 YT의 도입을 위해서는 주행 경로 최적화는 필수적인 기술이라 하겠다. 본 장에서는 GPS 의 위치 정보를 기반으로 터미널의 중앙 관제소가 목적지까지의 경로 안내를 한다는 전제 하에 YT의 운영이 어떻게 이루어질 수 있는지를 소개해 보이고자 한다.
안벽의 QC들은 양적하 계획에 정해져 있는 순서대로 컨테이너를 선박에 올리거나 내린다. 양적하 계획은 선박의 안정성과 장치장에서의 작업 효율을 극대화하는 방향으로 사전에 미리 수립된다. 따라서 YT의 운영 목표는 QC가 양적하 작업을 순서에 맞게 지연 없이 수행할 수 있도록 뒷받침하는 것이 된다. 이를 위해서는 YT에 대한 작업할당이 적절해야 하고 YT의 이동도 최단 시간에 도착이 가능한 경로를 따라야 할 것이다. YT의 작업할당 방법에는 여러 가지가 있겠지만 본 논문에서는 이 중 한 가지를 가정하기로 한다. 또한 교통 상황을 실시간에 파악하지 못하는 상황에서는 일단 최단거리 경로를 최적의 경로로 간주하는 것으로 한다.
작업할당 방식은 작업이 차량을 선택하는 작업 주도적 방식(job-initiated dispatching)과 차량이 작업을 선택하는 차량 주도적 방식(vehicle-initiated dispatching)으로 나눌 수 있다. 본 연구의 대상 터미널에서는 YT에 대한 작업할당이 차량 주도적 방식으로 이루어지는 것으로 가정한다. 이 방식에서는 어떤 YT가 현재의 작업을 끝내고 유휴 상태가 되면 모든 QC의 양적하 작업 리스트에서 가장 급한 작업을 자기가 수행할 다음 작업으로 선택하는데, 급한 정도가 같은 작업이 복수로 존재할 경우에는 거리가 가까운 QC의 작업을 선택한다. YT가 작업할당을 받고 나면 대상 컨테이너가 있는 위치까지 무부하 주행(empty travel)으로 이동해야 한다. 할당 받은 작업이 적하 작업이면 적하할 컨테이너가 저장되어 있는 장치장 내 위치가 그 목적지가 되고, 양하 작업이면 그 컨테이너를 선박에서 내려 줄 QC 아래가 목적지로 된다. 목적지가 파악되면 관제소는 YT의 현 위치에서 목적지까지의 최단 경로를 찾아서 YT에게 안내한다. 이 경로대로 무부하 주행을 마친 YT 는 컨테이너를 크레인으로부터 받을 때까지 해당 위치에서 대기한다. 컨테이너 상차가 완료되면 YT는 즉시 그 사실을 관제소에 보고하고, 관제소는 다시 그 컨테이너의 목적지까지 컨테이너를 싣고 부하 주행(loaded travel)을 할 최단거리 경로를 안내한다. 무부하 주행이든 부하 주행이든 만약 최단거리 경로가 복수로 존재한다면 그 중 하나가 무작위로 선택된다. 보통 컨테이너 터미널에서는 다수의 QC가 동시 다발적으로 양적하 작업을 진행하며 이를 뒷받침하기 위해 수십 대의 YT가 동원되어 순차적으로 작업할당을 받고 이동하는 일이 이어진다.
4. 컨테이너 터미널 내 교통 속도 예측
본 장에서는 터미널 내부 교통 속도를 예측하는 모델을 학습하기 위한 방안을 상세히 설명한다. 먼저 4.1절에서 대상 터미널의 도로망 형태를 살펴보고, 4.2절에서는 본 연구를 위한 차량 주행 시뮬레이션에 대해 소개한다. 이어서 4.3절에서 터미널 내부 교통 데이터의 특징을 설명한 다음, 4.4절에서 속도 예측을 위해 사용되는 속성들을 소개한다.
4.1 대상 터미널의 도로망 형태
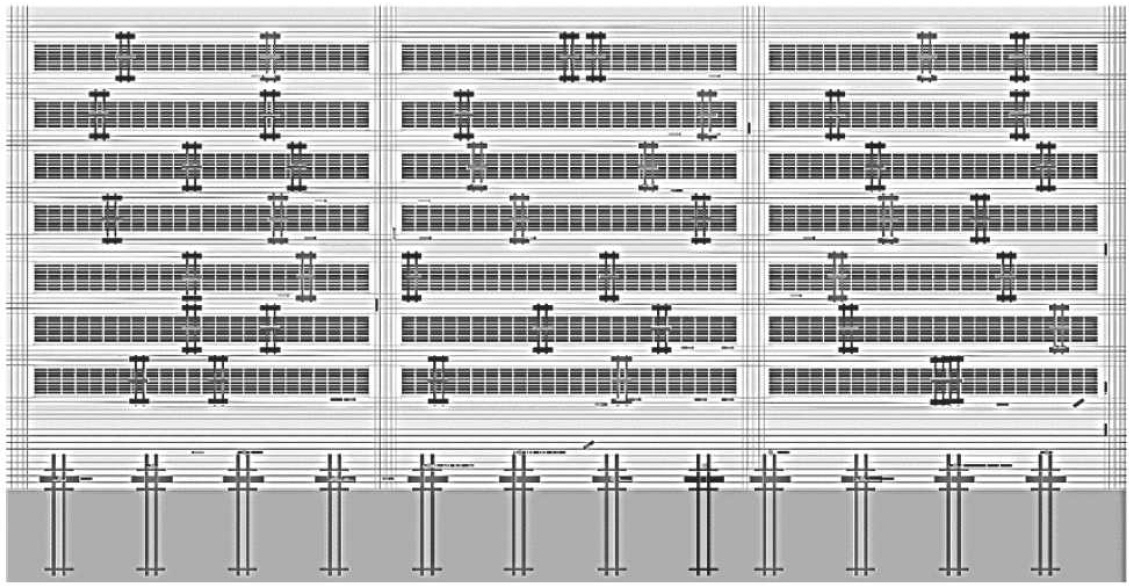
Fig. 1은 본 연구의 대상인 국내 한 컨테이너 터미널의 내부 도로망을 보여주고 있다. 그림 아래쪽의 안벽 영역에는 접안 선박들을 대상으로 컨테이너 양적하 작업을 수행하는 12대의 QC가 설치되어 있다. 나머지 영역을 차지하고 있는 장치장은 총 21개의 블록으로 구성되어 있으며, 이들 블록이 3열로 나뉘어 열 당 7개씩 배치되어 있다. 각 블록에는 2대의 장치 크레인이 설치되어 있어서 트럭이 운반해 온 컨테이너를 장치장에 적재하거나 반대로 장치장에 있는 컨테이너를 집어서 트럭에 실어주는 역할을 한다. 트럭과 장치 크레인 사이의 컨테이너 전달 작업은 블록의 길이 방향 양 측면에 있는 TP(transfer point)에서 이루어진다. 이 터미널의 경우 블록의 각 측면에는 24개의 TP가 연이어 있으며, 위쪽 측면 TP들은 외부트럭 전용, 그리고 아래쪽 측면 TP들은 YT 전용으로 사용된다. TP들이 연이어 있는 이들 차로에서는 주행이 허용되지 않으며, 주행은 TP 차로와 인접한 주행 차로로 해야 한다. TP는 장치장 블록 뿐 아니라 QC 아래의 차로들에도 있게 된다. 그러나 QC의 TP는 그 QC가 일련의 양적하 작업을 수행하는 기간 동안만 한시적으로 설치되며 작업이 없는 QC 아래로는 YT가 자유로이 통과할 수 있다. 그림에는 나타나 있지 않으나 장치장의 좌 상단 방향에는 외부트럭들이 출입하는 게이트가 있다. 외부트럭들은 이 게이트와 목적하는 블록 TP 사이를 운행하고, YT들은 블록 TP와 QC TP 사이를 운행한다.
상하로 인접한 두 블록 사이에는 수평 방향의 일방통행 4차선 도로가 있다. 이 도로의 가장자리 두 차로는 블록과 접한 TP 차로이고 가운데 두 차로는 주행 차로이다. 본 터미널의 경우 이들 차로에서는 모두 그림으로 볼 때 좌측에서 우측으로의 통행만 가능하고, 두 인접 주행 차로 간에는 차량들의 차로 변경이 허용된다. 장치장의 최상단에 위치한 블록들의 위쪽 TP 차로 바로 위에는 별도의 4차선 양방향 통행 도로가 인접해 있다. 그 4개 차로 중 블록과 가까운 쪽 두 개는 그림의 우측으로 가는 차로이고 먼 쪽 두 개는 좌측으로 가는 차로이다. 장치장 최하단에 위치한 블록들의 아래쪽 TP 차로 바로 아래에는 1차선으로만 된 우측 방향의 일방통행로가 인접해 있다. 또 그 아래로는 2차선의 좌측 방향 일방통행 도로가 있다. 이상은 모두 장치장 영역에 속하는 도로이다. 장치장 아래쪽의 안벽 영역에는 좌측 방향으로 가는 9개 차로로 구성된 일방통행 도로가 있다. 이들 중 해측에 가장 가까우면서 QC 아래를 통과하는 6개의 차로에는 QC와의 작업을 위한 TP들이 있을 수 있지만, 장치장과는 달리 이들 차로에서는 주차뿐 아니라 주행도 같이 허용된다. 다만, 양적하 작업을 위해 TP가 설치되면 YT의 진행을 방해하게 되기 때문에 YT의 용이한 주행을 위해 양적하 작업을 수행하는 QC 아래의 TP 설치는 인접한 두 개 이하의 차로로 한정된다.
수직 방향으로는 장치장과 안벽 영역을 가로지르는 총 4개의 도로가 있다. 이 중 두 개는 장치장 좌우 외곽에 인접해 있고 나머지 두 개는 장치장을 3분하는 형태로 내부를 관통하며 지나간다. 이들 도로는 공히 4개의 차로로 이루어져 있는데, 이 중 좌측 두 개는 하행용이고 우측 두 개는 상행용이다. 수직 도로가 수평 도로와 만나는 곳에는 교차로가 형성된다. 이 터미널에는 총 40개의 교차로가 있다.
4.2 차량 주행 시뮬레이션
본 연구에서는 Fig. 1의 터미널에서 주어진 양적하 계획이 실행되는 과정을 시뮬레이션을 통해 상당히 현실적 수준으로 재연하고 이 과정 중 교통 데이터를 수집한다. 외부트럭과 함께 YT들이 주행하는 터미널의 내부 도로 상황을 시뮬레이션 상에서 현실적으로 재연할 수 있으려면 기본적으로 충돌과 교착(deadlock) 없이 차량들을 운행시킬 수 있는 라우팅 (routing) 알고리즘이 필요하다. 본 연구에서는 도로망을 차로 들의 유향 그래프(directed graph)로 모델링한 다음 주어진 출발 노드(node)로부터 목적 노드까지 충돌이나 교착 없이 최단 시간에 도달하는 경로를 찾아 주는 Gawrilow et al. (2008)의 라우팅 알고리즘을 사용하였다. 원래 이 알고리즘은 무인 자동화 차량인 AGV(automated guided vehicle)에 대해 최적 주행 경로를 안내하기 위해 개발된 것으로, 이미 주행 중이거나 경로가 결정된 모든 AGV들의 경로 상 각 링크가 AGV에 의해 점유되는 시간대를 보고, 이들을 피하면서 목적 노드까지 최단 시간에 도달할 수 있는 링크들의 순서와 점유 시간대(필요에 따라서는 정지하는 것까지 포함)를 Dijkstra 알고리즘 (Dijkstra, 1959)을 이용하여 찾는다. 말하자면 이 알고리즘은 자신보다 앞서 출발한 모든 AGV의 주행 예정 경로와 그 경로 상의 각 링크가 점유되는 시간 스케줄을 완벽하게 알고 있다는 전제 하에 자신의 최적 경로를 찾는 것이다. 본 논문에서 실험을 위해 사용하는 차량 주행 시뮬레이터의 핵심 부분에 해당하는 Dijkstra 알고리즘은 탐색 소요 시간을 최대한 줄이기 위해 C++로 구현하였고, 나머지 부분은 Python으로 구현하였다. 이 시뮬레이터는 과거 연구 [5]에서도 사용되어 그 신뢰도가 검증된 바 있다.
본 연구에서는 터미널 내 교통 상황을 시뮬레이션으로 재연하기 위해 Gawrilow et al. (2008)의 라우팅 알고리즘을 일부 수정하여 사용한다. 일반 터미널에서는 외부트럭이나 YT 의 미래 움직임을 완벽하게 알 수 없으므로, 이 알고리즘을 그대로 이용해서 교통 정체를 피하는 최단 시간 경로를 찾는 것은 현실과 맞지 않다. 다른 차량들의 움직임에 대한 세부 정보가 없다는 가정 하에서는 모든 차량이 목적지까지 최단 거리 경로로 가는 것이 최선일 것이다. 그러나 차량들이 충돌이나 교착 없이 주행하는 것을 시뮬레이션 상에서 재연해야 하기 때문에, 일단 최단 거리 경로를 먼저 찾은 다음에 Gawrilow et al. (2008)의 방법대로 앞 선 차량들의 움직임에 대한 정보를 반영하여 그 경로 상에서 충돌과 교착 없이 주행할 수 있는 주행 시간 계획을 만들어 낸다. 이렇게 하면 일단 출발지와 목적지가 주어진 모든 YT와 외부트럭이 서로 충돌 없이 최단 거리 경로를 주행하는 모습을 시뮬레이션으로 재연할 수 있고, 도로망 내 어떤 링크에 대해서든 주어진 시간 구간에서의 평균 차량 밀도와 속도도 파악할 수 있다. 주행 차량들은 모두가 감속 없이 등속으로만 움직이고 그 속도는 직선 구간 주행, 회전 구간 주행, 그리고 차로 변경 시 각각 서로 다르다. 이에 따라 교통 정체로 인해 혹은 목적지에 도달하여 정지하고자 할 때나 정지 상태에서 출발할 때에는 갑작스럽게 속도 변화가 있는 것으로 시뮬레이션 된다. 시뮬레이션이 가감속을 반영하지 못하는 점에 있어서 현실과 차이가 있기는 하지만 주행 시 앞 차와의 안전거리를 지키고 회전 시 차체가 인접 차로를 침범하는 것까지 감안하여 충돌이나 교착 없이 주행할 수 있게 하므로 전체적 교통 흐름을 비교적 현실에 가깝게 재연하는데 큰 문제가 없다.
4.3 터미널 내부 교통 데이터
실제 터미널에서 교통 정체는 항시 발생하는 것이 아니라 교통 흐름의 변화에 따라 일부 도로에서 일부 시간대에 발생한다. 터미널 내에서 운행하는 외부트럭의 수와 YT의 수를 현실 터미널에서의 통계를 기반으로 무작위 생성하여 시뮬레이션 해 보면 전체 교통 데이터에서 정체 데이터가 차지하는 비율이 매우 낮다. 이렇게 불균형이 심한 데이터(skewed data)로 학습할 경우 의미 있는 예측 모델을 학습하기가 매우 어렵다. 학습 알고리즘의 입장에서는 데이터 중 극히 일부에 불과한 정체 데이터를 무시해 버리고 대부분을 차지하고 있는 정상 데이터에 대해서만 정확한 예측을 하더라도 전체적으로 평균 정확도를 충분한 수준으로 높일 수 있게 되기 때문이다. 그래서 실제로 학습을 해 보면 대부분 평균 정확도만 높지 정체시의 예측 정확도는 턱없이 낮은 모델을 얻게 된다. 이러한 어려움에 대한 해결책으로는 오버 샘플링(over-sampling) 혹은 언더 샘플링(under-sampling)을 통해 인위적으로 분포의 균형을 맞추는 방법이 있다. 우리 문제의 경우 오버 샘플링은 소수인 정체 데이터를 여러 번 복사하여 그 수를 늘이는 것이고, 언더 샘플링은 다수인 정상 데이터를 일부만 무작위로 추출하여 정체 데이터와 그 수가 비슷하게 만드는 것이다. 이러한 방법을 쓰더라도 기본적으로 정체 데이터가 어느 정도 확보되지 않고서는 좋은 모델을 학습하기가 여전히 어렵게 된다.
Fig. 1의 배치도에는 나타나 있지 않지만 도로망을 링크와 노드의 그래프로 표현해 보면(Fig. 2 참조) 그 구성 링크들이 여러 가지 유형으로 나뉜다. 대부분은 직진 링크이지만 교차로에는 직진뿐 아니라 좌회전과 우회전 링크도 있다. 원론적으로 보면 보다 정확한 교통 속도 예측을 위해서는 각 유형별로 별도의 모델을 학습하여 사용하는 것이 좋을 것이다. 극단적으로는 동일 유형이더라도 그 위치가 다르면 각기 별도의 모델을 학습하는 것도 생각해 볼 수 있겠다. 그러나 그럴 경우 각 모델별로 학습에 필요한 충분한 양의 정체 데이터를 확보 하기가 쉽지 않다. YT의 작업 시나리오를 다양하게 바꾸어가며 교통 시뮬레이션을 상당 기간 동안 하더라도 위치별 및 유형별로 골고루 정체가 발생하도록 만들기가 어렵기 때문이다. 물론 현실의 터미널에서도 위치별 유형별로 정체 데이터가 충분히 누적되려면 아주 오랜 기간이 소요될 것이다. 따라서 본 연구에서는 위치나 유형에 관계없이 단 하나의 모델만 학습하여 교통 속도를 예측하도록 함으로써 정체 데이터의 부족 문제를 해결하고자 하였다.
Fig. 2는 사거리 교차로와 그 근처의 여러 링크들을 보여주고 있다. 그림의 실선 링크들이 교차로를 통과하는 링크들이 고, 점선 링크들은 교차로로 진입하거나 통과 후 진출하는 링크들이다. 그림에서 오른쪽 방향으로 일방통행인 수평도로에서의 교차로 통과는 직진, 좌회전, 우회전 모두 가능하다. 양방통행인 수직도로에서는 상행 시 직진과 우회전만 가능하고 하행 시에는 직진과 좌회전만 가능하다. 속도 예측 모델 학습을 위해서는 이들 링크를 단위 시간 구간 동안 통과하는 YT들의 평균 속도와 평균 밀도 데이터를 수집해야 한다.
소정의 단위 시간 구간 T 동안 어떤 링크 L을 통과하는 차량의 속도 v는 v = d / t로 계산되는데, d는 차량의 중심점이 T 동안 L 내에서 이동한 거리이고 t는 그 차량이 L 내에서 보낸 시간이다. 여기서 t에는 L 내에서 정지 상태로 대기하는 시간도 포함된다. 교차로 내의 링크들은 비교적 짧기 때문에 정체 시 진입 차량은 링크의 시작 노드(그림에서 작은 원으로 표시)에 차량의 중심점을 맞춘 상태로 대기한다. 중심점이 링크의 반대쪽 끝 노드를 통과하면 차량이 그 링크를 벗어난 것으로 간주한다. 평균 속도는 T 동안 L을 통과한 차량들의 속도의 합을 차량 수로 나눔으로써 계산된다. 그런데 본 연구에서는 이 속도를 0과 1 사이의 값으로 정규화(normalization)하여 사용한다. 앞에서 언급했듯이 차량의 주행 속도가 직선 링크와 회전 링크에서 각기 서로 다름에도 불구하고 우리가 차로 유형 구분 없이 하나의 모델만 이용하여 평균 속도를 예측하려하기 때문에 정규화가 필요한 것이다. 정규화된 속도는앞에서 구한 v를 L에서의 주행 가능 속도(4.2절에서 가정한 링크 유형별 속도)로 나눔으로써 간단히 구해진다. 본 연구에서 차량의 밀도는 역시 0과 1 사이의 값으로 T 동안 L에서 관찰된 차량의 수를 T 동안 L에서 관측 가능한 최대 차량의 수로 나눈 값으로 정의한다.
미래의 속도 예측은 예측 대상 링크 뿐 아니라 그 진입 및 진출 링크들에서의 최근의 차량 밀도와 속도를 기반으로 하는 경우가 많다. Fig. 3의 타이밍 다이어그램을 보고 설명하자면, 최근의 속도와 밀도란 현 시점이 포함된 단위 시간 구간인 T0 을 기준으로 해서 과거 구간들인 T-1, T-2, . . . T-n 에서의 평균 속도와 밀도를 말한다. T0 구간에는 현 시점 이후의 미래도 포함되어 있기 때문에 그 평균 속도나 밀도를 알지 못한다. 예측하고자 하는 미래는 보통 T1 구간을 대상으로 하는 경우가 많다. 만일 더 먼 미래인 T2 구간에서의 속도를 예측하려면 역시 미래인 T1 에서의 속도와 밀도를 알아야 하므로 그 값들을 예측해서 사용해야 할 것이다. 이렇게 예측치를 기반으로 예측을 하게 되면 먼 미래로 갈수록 예측의 정확도는 상당히 떨어질 수밖에 없다. 본 연구에서의 예측 대상 미래는 YT 의 최적 주행 경로를 안내하는데 사용될 것을 염두에 둔 것으로, 여러 구간의 미래까지 포함한다. 터미널 내부로 한정되어 가깝기는 하지만 YT가 목적지까지 주행하는데 어느 정도 시간이 소요되기 때문이다.
본 연구에서는 외부트럭에 대한 교통 데이터 수집이 불가능한 상황을 가정하므로 YT의 속도와 밀도에 관한 데이터만 이용하여 미래 속도를 예측해야 한다. 그런데 위에서 언급했듯이 먼 미래의 속도 예측을 위해 가까운 미래의 속도를 또 예측하여 사용하는 것이 문제가 되기 때문에 속도는 미래가 아닌 최근 속도만 사용한다. 반면 밀도로는 최근 밀도가 아니라 미래 밀도를 주로 사용한다. YT의 경우에는 예측 모델을 사용하지 않고 작업계획 정보를 이용하여 미래의 밀도를 비교적 정확히 추정할 수 있다. 작업계획에는 미래의 어느 시점에 어떤 컨테이너가 어디에서 출발하여 어디까지 갈 예정인지에 관한 정보가 들어 있기 때문에 이를 이용하면 관련 도로 상의 YT 미래 밀도를 상당 수준으로 정확히 추정할 수 있게 된다. 최근 밀도를 사용하지 않는 이유는 그 영향이 이미 최근 속도에 반영되어 있기 때문이다.
YT의 밀도는 다음과 같이 계산된다. 부하 주행이든 무부하 주행이든 현재 YT가 주행 중이라면 목적지까지의 경로가 이미 결정되어 있기 때문에 그것을 그대로 현재와 미래 밀도 계산에 반영하면 된다. 그런데 YT가 무부하 주행 중인 경우에는 다음에 이어질 부하 주행의 경로에 대한 주행도 미래 밀도계산에 반영할 수 있다. 다만 무부하 주행을 마치고 YT에 대한 컨테이너 상차 작업이 완료되어 출발 준비가 되어야 목적지까지의 부하 주행 경로가 결정되므로 목적지까지의 최단 경로가 여러 개 존재할 경우 실제 어디로 갈지는 아직 확정되지 않은 상태다. 따라서 본 연구에서는 부하 주행의 출발지로부터 목적지까지의 k개의 최단 거리 경로 모두를 밀도 계산에 반영하되, 각 경로로 1대의 YT가 아닌 1/k대의 YT가 주행하는 것으로 계산함으로써 불확실한 상황에서 기대치를 반영한다. 또한 현재 정차 상태인 YT 중에서도 작업계획에 따라 작업 배정만 받고 아직 주행 경로가 정해지지 않은 경우에는 무부하 주행과 부하 주행 모두에 대해서 이러한 기대치 계산 방식으로 추정 밀도를 계산한다. 정차 중인 YT들 중 아직 작업배정을 받지 못한 것들에 대해서는 주행 경로 추정을 하지 못한다. 작업 배정 전에는 목적지가 어디인지도 알지 못하기 때문이다.
4.4 속도 예측을 위한 속성
Table 1은 속성 선별 과정을 거쳐 속도 예측 모델의 입력으로 확정된 38개의 속성들을 보여주고 있다. 첫 세 속성은 속도 예측 대상 링크가 일반 직진, 교차로 내 직진, 교차로 내 회전 중 어떤 유형의 링크인지를 표시하는 것으로 항상 이 세 속성 중 하나만 1이 된다. 그 다음 10개의 속성은 각각 최근 시간 구간 T-1, T-2, . . . T-10에서의 예측 대상 링크 내 YT 속도의 평균값이다. 다음 속성은 예측하고자 하는 미래가 현재 시간 구간 T0으로부터 몇 번째로 떨어진 구간인지를 나타낸다. 나머지 속성들은 모두 여러 관련 링크에서의 YT 밀도를 나타내는 속성들이다. 밀도는 확정 밀도와 추정 밀도로 구분되고 각기별도의 속성이 된다. 4.3절의 마지막 부분에서 설명했듯이 확정 밀도는 확정된 경로로부터 계산되는 밀도이고, 추정 밀도는 목적지까지의 여러 대안 경로 중 무작위로 선택될 기대치를 반영하여 계산하는 밀도이다. 밀도 관련 속성 중 가장 중요한 것은 당연히 예측 대상 링크의 밀도이겠지만, 그 외에도 간섭 링크, Upstream 링크, Downstream 링크에서의 밀도도 중요하다. 어떤 링크 L ́에 차량이 지나가는 동안 대상 링크 L로 동시에 충돌 없이 차량이 지나갈 수 없다면 L ́을 L의 간섭 링크라 한다. 당연히 L ́의 차량 밀도가 L의 정체 여부에 큰 영향을 미치고 간섭 링크가 많을수록 그 영향도 커지므로 간섭 링크의 속성 값으로는 대상 링크에 대한 여러 간섭 링크 밀도의 총 합을 이용한다. Upstream 링크와 Downstream 링크는 대상링크로 연결되어 들어가는 링크와 대상 링크 통과 후 바로 연결되는 링크로서 각각 복수개가 존재할 수 있다. Upstream 링크는 많을수록 대상 링크로 들어오는 차량의 수가 늘어나서 정체될 가능성이 높아지므로 그 속성 값으로는 그들 링크 밀도의 총 합을 이용한다. 이 속성 값이 커지면 정체 가능성도 높아진다. Downstream 링크는 많을수록 대상 링크의 정체 해소에 도움이 되기 때문에 그 속성 값으로는 각 링크의 여유도의 총 합을 이용한다. 여기서 여유도란 1에서 밀도를 뺀 값을말한다. 이 속성 값은 커질수록 정체 가능성이 낮아진다. 이상 이들 관련 링크에서의 YT 밀도 혹은 여유도는 예측 대상 시간 구간인 Tk 에서 뿐만 아니라 그 바로 전과 후의 구간인 Tk-1과 Tk+1에 대해서도 계산되어 반영되므로 관련 링크별로 속성이 3개씩이 된다.
5. 실험 결과
제안 방안의 평가를 위해 Fig. 1의 터미널에서 72대의 YT가 1,500개의 양적하 컨테이너 운반 작업을 수행하는 상황을 3장에서 설명한 운영 방식에 따라 시뮬레이션으로 재연하였다. 이하 실험은 모두 Intel i7-10700KF (3.80GHz) CPU를 장착한 PC 상에서 수행되었다. 외부트럭은 분당 평균 5대씩 들어오고 역시 평균적으로 같은 수가 나가도록 설정하였다. 양적하 컨테이너의 출발 TP와 도착 TP는 각각 무작위로 선정하였다. 시뮬레이션 상에서 이들 작업이 모두 완료되기까지는 약 5 시간이 소요되는데, 시뮬레이션 시작 시점에는 모든 YT가 무작위로 정해진 위치에서 무부하 주행만 하게 되어 있기때문에 이를 감안하여 첫 30분을 초기화 기간으로 간주하고 그 이후부터 교통 데이터를 수집하였다. 데이터 수집의 단위 시간 구간 T의 길이는 30초로 설정하였다. 이러한 시뮬레이션과 데이터 수집을 총 100회 실행하였고 이 중 70회는 훈련 (training)용 그리고 나머지 30회는 테스트(test)용으로 사용하였다. 훈련용으로 수집한 데이터는 총 200만 개 이상이었지만 이 중 정체가 없어 속도가 1인 대부분의 데이터는 제외한 다음, 주행 속도에 따라 [0, 0.1)의 속도구간 1부터 [0.9, 1.0)의 속도구간 10까지 각 구간마다 데이터의 수가 비슷하도록 언더 샘플링(4.3절 참조)하여 훈련 데이터를 구성하였다. 이렇게 확보한 훈련 데이터의 총 수는 310,340개였고 마찬가지 과정을 거쳐 확보한 테스트 데이터의 총 수는 132,310개였다. 본 연구에서 채택한 예측 모델은 수치예측에 널리 사용되는 다층 인공 신경망(MLP: multi-layer perceptron)으로서 3개의 은닉층 (hidden layer)을 가지며 각 은닉층은 64개의 ReLU(rectified linear unit)로 구성되어 있다.
Table 2는 학습한 모델의 랭킹(ranking) 성능을 테스트한 결과이다. 두 데이터 a와 b의 실제 속도가 va와 vb 이고 예측 속도가 va'와 vb'라면, va ≥ vb 일 때 va ́≥ vb ́이면 랭킹이 맞게 된 것이고 아니면 틀린 것이다. Table 2는 서로 다른 속도 구간에서 샘플링한 10,000개의 데이터 쌍에 대해 모델을 적용했을 때의 랭킹 정확도를 보이고 있다. 표에서 속도구간 1과 속도구간 10에서 뽑은 데이터 쌍들에 대한 랭킹 정확도는 96.1%로서 매우 높게 나타나고 있다. 그러나 동일한 속도구간에서 뽑은 데이터 쌍에 대해서는 그 정확도가 떨어져서 50% 를 약간 상회하는 수준을 보인다. 속도 예측 결과가 YT의 최단시간 주행 경로를 찾는데 사용되려면 서로 다른 속도의 링크를 구분할 수 있어야 한다는 점에서 랭킹 성능이 중요하다하겠다. 속도구간 구분 없이 전체 테스트 데이터에서 무작위로 뽑은 10,000개의 데이터 쌍에 대해 모델을 적용했을 때의 랭킹 성능은 71.3%로서 비교적 양호함을 확인하였다. 모델의 속도 예측치가 실제 값과 절대적으로 얼마나 차이가 나는지를 보기 위해 테스트 데이터 전체에 모델을 적용한 결과 MAE(mean absolute error) 값은 0.18로 확인되었다. 또한 추가로 실시한 10회의 시뮬레이션을 통해 최단 거리로만 경로를 안내하는 경우와 속도 예측 모델을 활용하여 최단시간 경로를 찾아 안내한 경우를 비교했을 때 YT 주행 소요 시간이 평균 약 10.2% 절감되는 것을 볼 수 있었다. 이는 본 논문에서 제안한 예측 모델의 정확도가 주행경로 최적화를 위해 사용되기에 충분한 수준에 이르고 있음을 말해 주는 것이라 하겠다. 랭킹 성능이 71.3%로 그다지 좋지 않게 보이지만, 이는 경로를 찾는 과정에서 주행 소요 시간이 긴 쪽을 잘못 선택할 확률이 28.7% 밖에 되지 않음을 의미하는 것으로 이로 인해 10.2%의 절감이 가능했던 것으로 볼 수 있다. 만약 랭킹 성능을 더 올릴 수 있다면 주행 소요시간도 더 절감할 수 있을 것이다.
6. 결 론
본 논문에서는 컨테이너 터미널 내 도로 상의 미래 교통 속도를 예측하는 모델을 학습하는 방안을 제시하였다. 보통 교통 예측은 도로 상의 모든 차량에 대한 밀도 및 속도 정보를 기반으로 하는데 비해 컨테이너 터미널에서는 외부트럭에 대한 교통 데이터 수집이 불가능한 상황이라 어려움이 있다. 대신 YT에 대해서는 상세 교통 데이터를 확보할 수 있을 뿐 아니라 YT의 작업계획 정보를 이용하여 가까운 미래의 운행 경로도 추정할 수 있기 때문에 본 연구에서는 이를 최대한 활용함으로써 비교적 정확한 수준의 속도 예측 모델을 학습할 수 있었다. 시뮬레이션 실험에서 이 모델을 이용하여 YT의 주행 경로를 개선한 결과 주행 소요 시간이 유의미한 수준으로 단축됨을 확인하였다. 본 기술은 향후 항만에 자율 주행 YT가 도입될 경우 반드시 필요한 것이 되겠지만, GPS를 장착한 보통의 YT를 운영하는 터미널에도 충분히 적용이 가능한 중요한 기술이라 하겠다.


 PDF Links
PDF Links PubReader
PubReader ePub Link
ePub Link Full text via DOI
Full text via DOI Download Citation
Download Citation Print
Print